






ComfyUI安装
基础
conda create -n imggen-cu118 python=3.10.14
conda activate imggen-cu118
# torch
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=11.8 -c pytorch -c nvidia
mkdir projects && cd projects
git clone https://github.com/comfyanonymous/ComfyUI
cd ComfyUI
pip install -r requirements.txt
CUDA_VISIBLE_DEVICES=1 python main.py --listen $your_server_ip --port 8081 &
# 查看日志:tail -f user/comfyui_8081.log
# node: ComfyUI Manager, 方便节点的install, remove, disable, and enable
cd custom_nodes/
git clone https://github.com/ltdrdata/ComfyUI-Manager.git
# 通过Manager => Custom Nodes Manger安装
ComfyUI Nodes for External Tooling # comfyui-tooling-nodes
ComfyUI Essentials # Node:Mask Previews+
net tool node for comfyui # comfyui-tooling-nodes => Node:LoadImageBase64
常用节点
- ComfyUI Manager
https://blog.csdn.net/2401_84760527/article/details/140261908
通过这个节点,我们可以管理安装节点(模型checkpoint, lora, vae, encoder, controlnet)
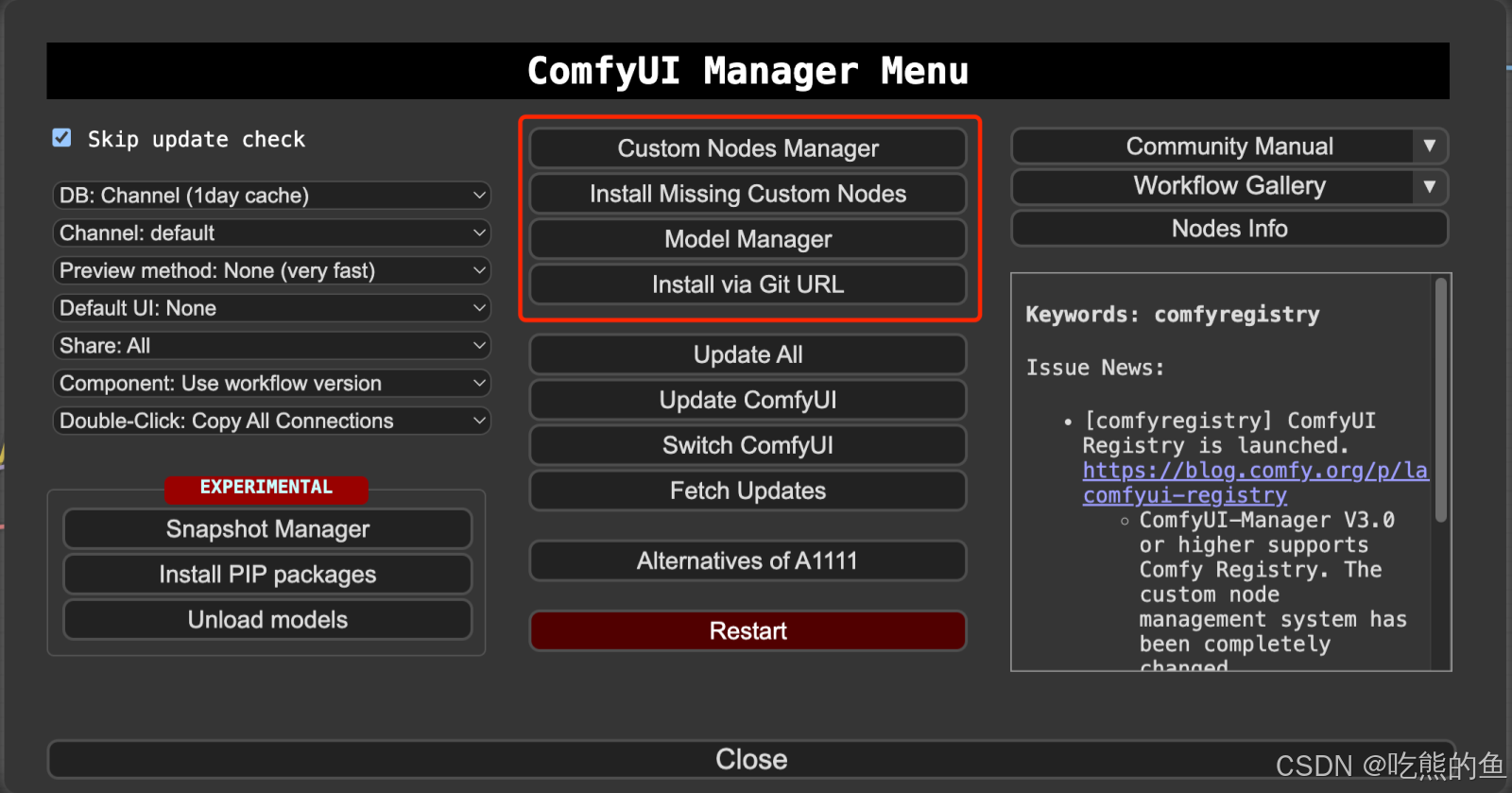
快捷方式
| key | note |
|---|---|
| Ctrl + 左键 | 区域选择 |
| 左键双击 | 打开节点快捷检索 |
| 新工具节点安装 | Manager中可以安装新的工具节点,安装后需要重启 |
| 新模型代码节点安装 | 手动下载,放到对应位置;不需重启,但需要重现刷新web界面 |
工作流
Flux
工作流图片(可直接拖拽到ComfyUI中):
- Flux-Schnell-comfyorg-fp8
- Flux-dev-comfyorg-fp8
- Flux-dev-Kijai-fp8
- Flux_Kijai_split_fp8
- Flux_bfl_split_fp16
- Flux_fill_fp8_outpaint
- Flux_fill_fp8_with_mask
- Flux_fill_outpaint_fp8_base64In_socketOut: WebAPI
在A100 40G上单卡测试速度(生成512x512, step=50)
| workflow | 单图生成时间 |
|---|---|
| 00_Flux-Schnell-comfyorg-fp8 | 2.24s |
| 01_Flux-dev-comfyorg-fp8 | 22.23s |
| 02_Flux-dev-Kijai-fp8 | 29.08s |
| 03_Flux_Kijai_split_fp8 | 29.96s |
| 04_Flux_bfl_split_FP16 | 22.45s |
1. Flux ComfyOrg: Checkpoint + KSampler
最简单的结构:
- 基于ComfyOrg提供的统一VAE、text encoders和UNet的checkpoint,是ComfyOrg做的FP8量化后的权重
- 使用集成noise generator, step scheduler, sampler的KSampler节点
- 由于Flux没有negative prompt,因此使用CLIP Text Encode(Ne节点填充
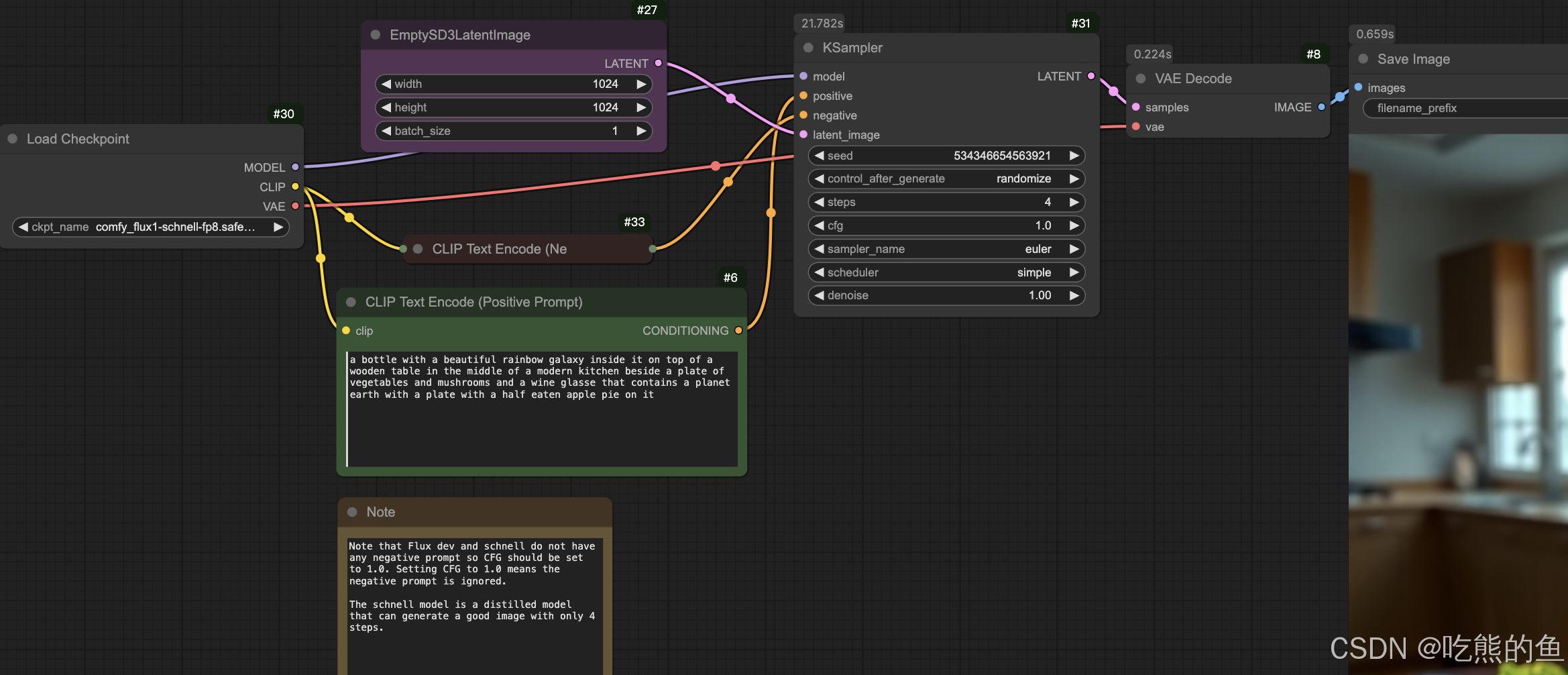
模型下载:Comfy-Org/flux1-schnell => models/checkpoints/# 两个版本都行,就是Ksampler的step设置要不同 # FP8: schnell版本,step默认为4 huggingface-cli download --resume-download Comfy-Org/flux1-schnell --local-dir model_hub/Comfy-Org/flux1-schnell ln -s ../../model_hub/Comfy-Org/flux1-schnell/flux1-schnell-fp8.safetensors \ models/checkpoints/comfy_flux1-schnell-fp8.safetensors # FP8: dev版本,step一般在20+,我用的50, https://huggingface.co/Comfy-Org/flux1-dev/ huggingface-cli download --resume-download Comfy-Org/flux1-dev --local-dir model_hub/Comfy-Org/flux1-dev ln -s ../../model_hub/Comfy-Org/flux1-dev/flux1-dev-fp8.safetensors \ models/checkpoints/comfy_flux1-dev-fp8.safetensors
直接通过Workflow => Browse Templates => 选择"Flux Schnell"打开了默认的FLUX Schnell工作流,修改模型加载位置、steps就可以获得相应的工作流。
2. Flux Kijai + comfyanonymous: 分开的VAE/Text Encoder/UNet + Ksampler
- 使用Kijai提供的VAE和FP8量化的UNet
- UNet就是官方FP16模型直接转FP8保存(量化细节可参考【生成模型】Flux-Fill与量化
1.4) - VAE模型估计和官方给出了ae.safetensors是一样的,没有FP8量化(我的猜想,未经过验证),直接替换成ae.safetensors也是能跑的(已验证)
- UNet就是官方FP16模型直接转FP8保存(量化细节可参考【生成模型】Flux-Fill与量化
- 其他的内容与【Flux ComfyOrg: Checkpoint + KSampler】完全一致
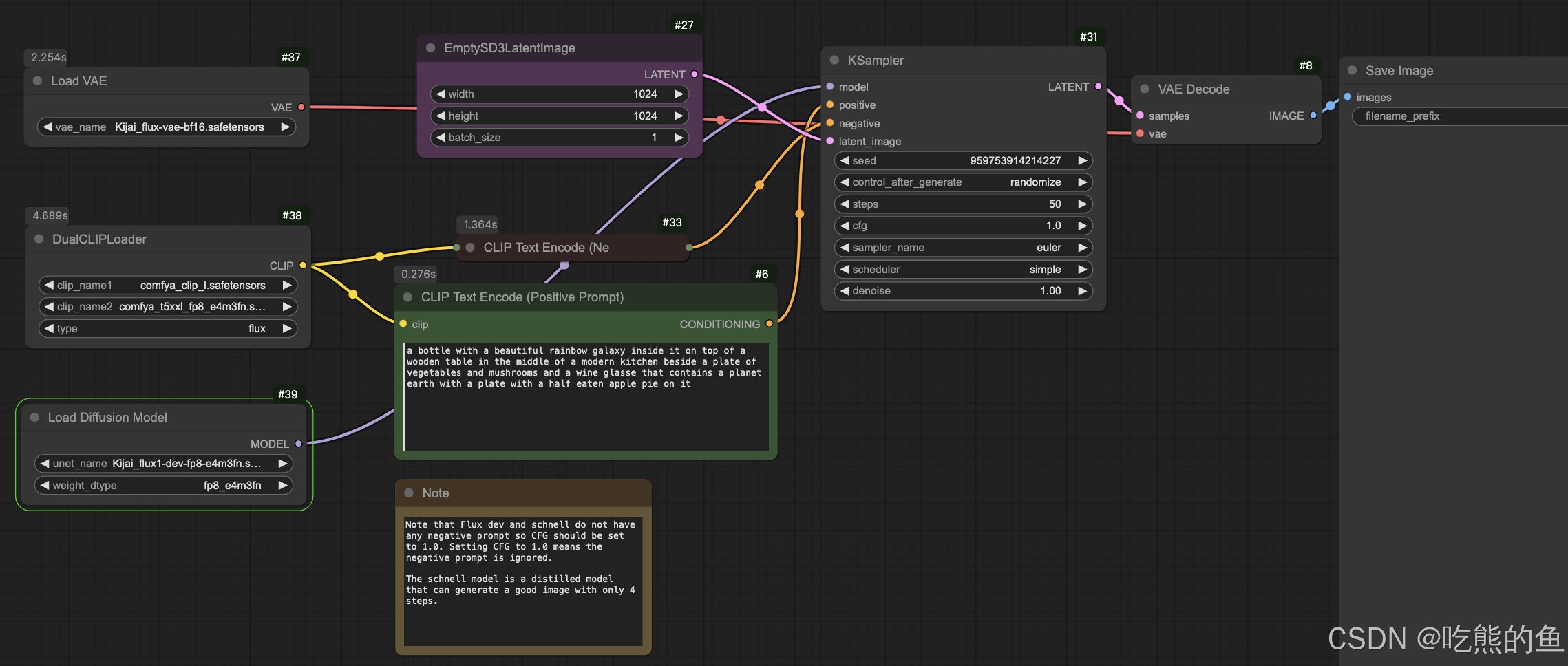
模型下载:
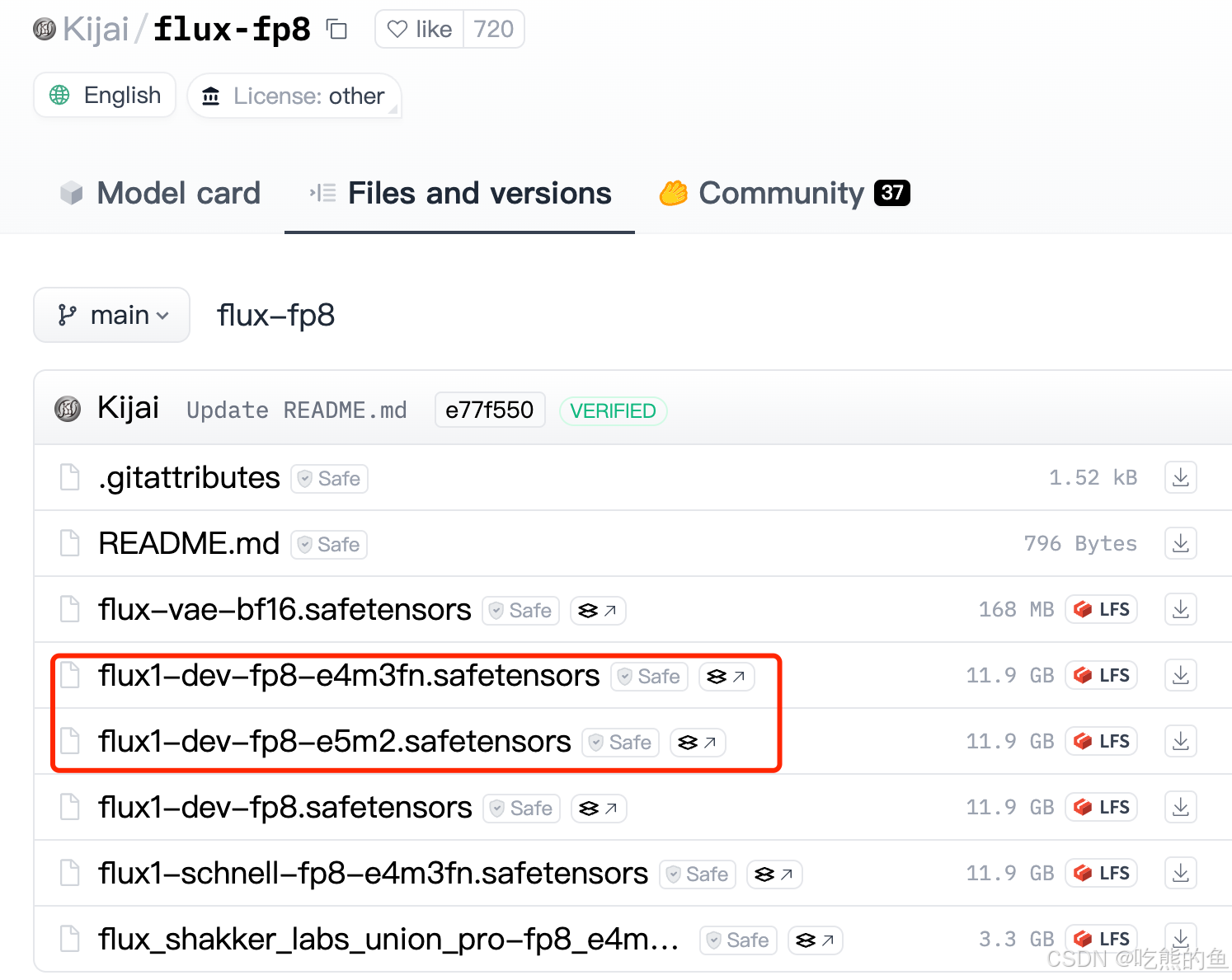
Kijai/flux-fp8 => models/vae/ models/unet/
comfyanonymous/flux_text_encoders => mdoel/clip# Kijai FP8: Flux-UNet + Flux-VAE huggingface-cli download --resume-download Kijai/flux-fp8 --local-dir model_hub/Kijai/flux-fp8/ # bfl_ae.safetensors is also fine ln -s ../../model_hub/Kijai/flux-fp8/flux-vae-bf16.safetensors models/vae/Kijai_flux-vae-bf16.safetensors # VAE比较小,未经量化 # Kijai提供了两种e5m2和e4m3fn量化方式的权重,flux1-dev-fp8.safetensors就是flux1-dev-fp8-e4m3fn.safetensors, flux1-dev-fp8-e5m2.safetensors is also fine, ln -s ../../model_hub/Kijai/flux-fp8/flux1-dev-fp8-e4m3fn.safetensors models/unet/Kijai_flux1-dev-fp8-e4m3fn.safetensors ln -s ../../model_hub/Kijai/flux-fp8/flux1-dev-fp8-e5m2.safetensors models/unet/Kijai_flux1-dev-fp8-e5m2.safetensors # Flux-Text: T5 (两个都可以) huggingface-cli download --resume-download comfyanonymous/flux_text_encoders --local-dir models/clip/comfyanonymous/flux_text_encoders ln -s ../../model_hub/comfyanonymous/flux_text_encoders/clip_l.safetensors models/clip/comfya_clip_l.safetensors # CLIP比较小,未经量化 ln -s ../../model_hub/comfyanonymous/flux_text_encoders/t5xxl_fp8_e4m3fn.safetensors models/clip/comfya_t5xxl_fp8_e4m3fn.safetensors # ln -s ../../model_hub/comfyanonymous/flux_text_encoders/t5xxl_fp8_e4m3fn_scaled.safetensors models/clip/comfya_t5xxl_fp8_e4m3fn_scaled.safetensors
3. Flux Kijai + comfyanonymous 2: 分开的VAE/Text Encoder/UNet + 分开的Ksampler
- 在【Flux Kijai + comfyanonymous】基础上,将KSampler进行了拆分,加载checkpoint的方式可以是上面两种的任意一种,这里选择了第二种
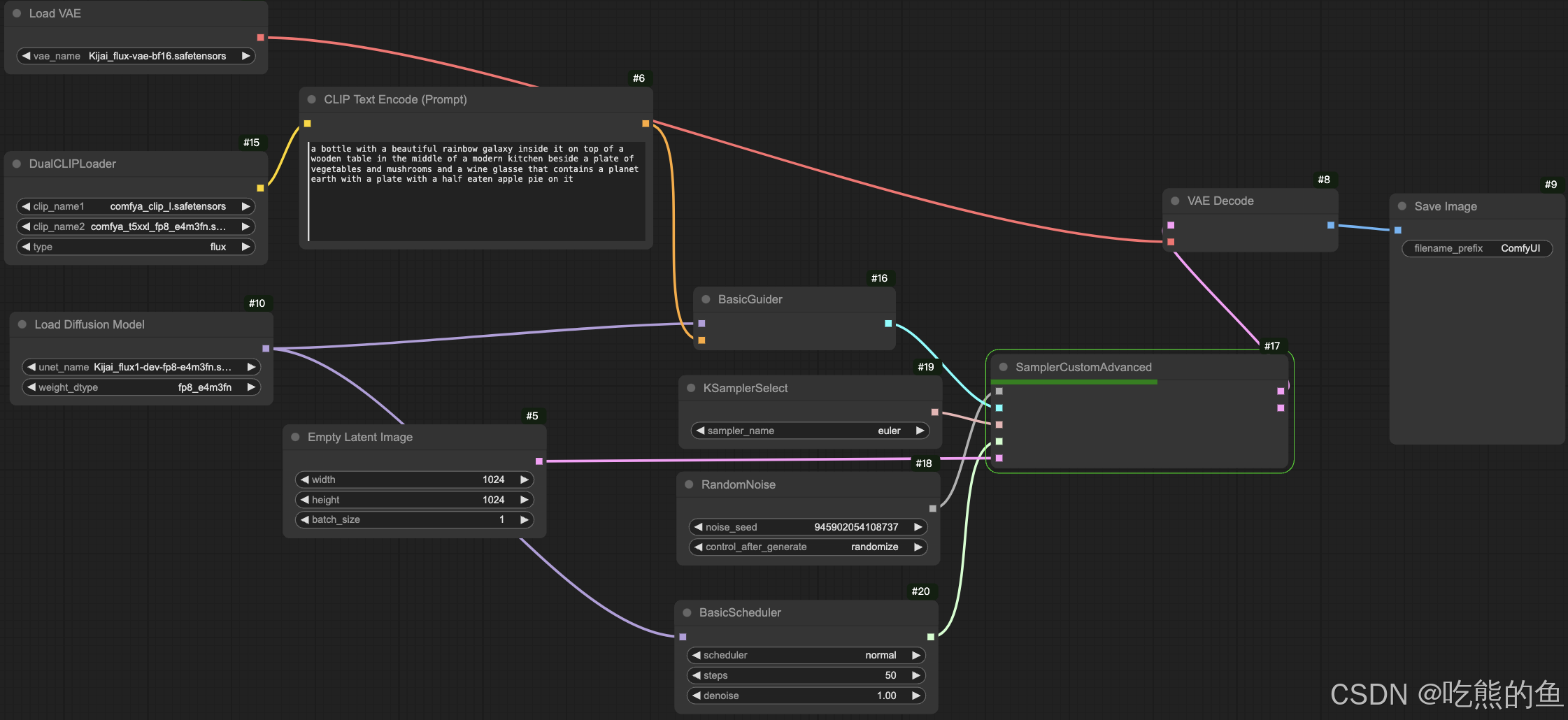
4. Flux-dev FP16
使用官方的FP16版本也是可以的,使用第二种分开的方式加载权重即可。
black-forest-labs/FLUX.1-dev => models/vae/ models/unet/
comfyanonymous/flux_text_encoders => mdoel/clip
下载权重
# FP16 (Optional): https://huggingface.co/black-forest-labs/FLUX.1-dev/
# Flux-UNet + Flux-VAE + CLIP
huggingface-cli download --resume-download black-forest-labs/FLUX.1-dev --local-dir model_hub/black-forest-labs/FLUX.1-dev/
ln -s ../../model_hub/black-forest-labs/FLUX.1-dev/flux1-dev.safetensors models/unet/bfl_flux1-dev.safetensors
ln -s ../../model_hub/black-forest-labs/FLUX.1-dev/ae.safetensors models/vae/bfl_ae.safetensors
ln -s ../../model_hub/black-forest-labs/FLUX.1-dev/text_encoder/model.safetensors models/clip/bfl_clip.safetensors
# Flux black-forest-labs没有提供text encoder T5的合并版本的权重,可以下载comfyanonymous提供的整合版(包括FP16和FP8)
# Flux-CLIP: CLIP + T5
huggingface-cli download --resume-download comfyanonymous/flux_text_encoders --local-dir models/clip/comfyanonymous/flux_text_encoders
# bfl_clip.safetensors is also fine
ln -s ../../model_hub/comfyanonymous/flux_text_encoders/clip_l.safetensors models/clip/comfya_clip_l.safetensors # CLIP比较小,一般不需要量化
ln -s ../../model_hub/comfyanonymous/flux_text_encoders/t5xxl_fp16.safetensors models/clip/comfya_t5xxl_fp16.safetensors
Flux-Fill
# FP16 Flux-Fill
# Flux-Fill模型的结构和Flux-dev是完全一样的,只是通过mask encoder将mask变成的latents替换原本随机产生的latents
huggingface-cli download --resume-download black-forest-labs/FLUX.1-Fill-dev --local-dir model_hub/black-forest-labs/FLUX.1-Fill-dev/
ln -s ../../model_hub/black-forest-labs/FLUX.1-Fill-dev/flux1-fill-dev.safetensors models/unet/bfl_flux1-fill-dev.safetensors
# FP8 (只有UNet部分)
huggingface-cli download --resume-download boricuapab/flux1-fill-dev-fp8 --local-dir model_hub/boricuapab/flux1-fill-dev-fp8/
ln -s ../../model_hub/boricuapab/flux1-fill-dev-fp8/flux1-fill-dev-fp8.safetensors models/unet/bori_flux1-fill-dev-fp8.safetensors
两个版本,一个是输入image,通过填写重绘的区域产生mask;一个是给定重绘的mask区域。
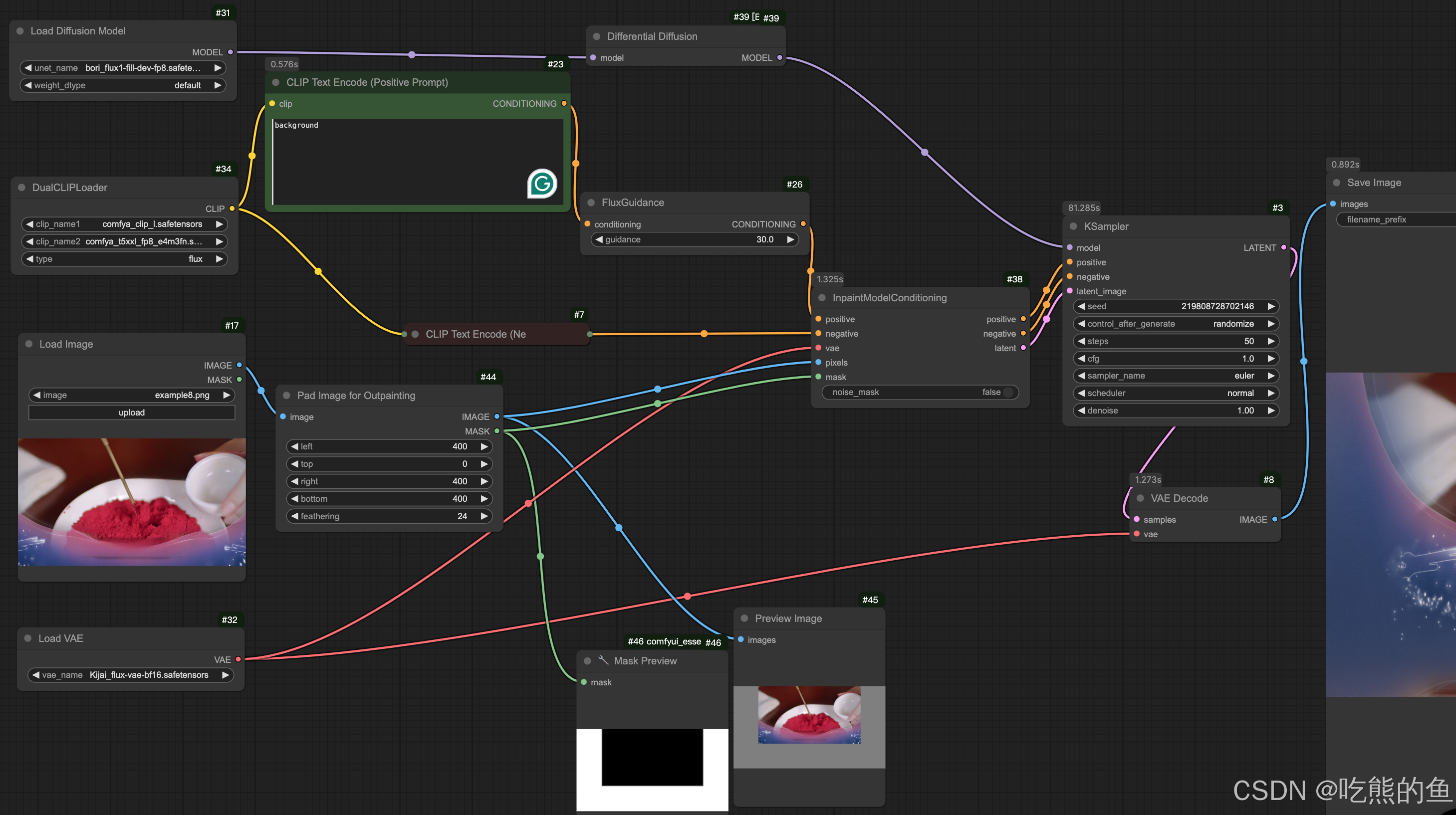

API调用

Flux版本介绍
版本差异在于:
●FP8量化 / GGUF量化 / schnell 4步快速出图 / VAE+CLIP是否融合在一个权重文件里
| model | size | GPU | note |
|---|---|---|---|
| Flux-Dev | 23.8G(UNet) + 168M(VAE)+246M(CLIP)+9.79G(T5) | 4090 | flux1-dev——官方提供的适用于非商业用途,开源的、经过指导蒸馏的模型(FP16)。包含独立的VAE权重和CLIP权重(CLIP text_encoer, text_encoder_2) |
| FLUX.1-schnell | 23.8G(UNet) + 168M(VAE)+246M(CLIP)+9.79G(T5) | 官方提供的适合本地开发和个人使用,图像生成速度更快的模型,4步即可出图,显存未减少 | |
| Kijai-fp8 | 11.9G(UNet FP8)+168M(VAE) | 量化的fp8精度的flux1-dev模型,但略微降低图像质量(几乎感知不到) | |
| Comfy-Org-flux-dev-fp8 | 17.2G(UNet+VAE+CLIP+T5) | 量化的fp8精度的flux1-dev模型 , Comfy-Org的版本中集成了CLIP和VAE,因此较大,而Kijai版本只有Diffusion model本体(11.9G) | |
| Comfy-Org-flux-schnell-fp8 | 17.2G | 量化的fp8精度的flux1-schnell模型 | |
| FLUX.1-dev-gguf | 4.03G-12.7G(FP8)-23.8G(UNet) | 6G+显存 | 提供不同精度的GGUF量化的版本,需要在ComfyUI中先下载ComfyUI-GGUF节点。 6G显存选择:flux1-dev-Q2_K.gguf flux1-dev-Q3_K_S.gguf flux1-dev-Q4_0.gguf 8G显存选择:flux1-dev-Q4_1.gguf … flux1-dev-Q5_K_S.gguf flux1-dev-Q6_k.gguf flux1-dev-Q8_0.gguf |
| flux_text_encoders | 246M(CLIP)+9.79(T5 FP16)/4.89G(T5 FP8) | 包含官方flux1-dev中的CLIP权重,以及text_encoder_2的fp8的量化版本。clip_l.safetensors应该就是Flux-Dev中的text_encoder,而t5xxl_fp16.safetensors应该就是Flux中text_encoder_2的整合,因此ComfyUI标准节点不能加载text_encoder_2这种分成多个文件的模型,因此需要合并起来。同时flux_text_encoders也提供了T5模型的FP8量化版本。 |
FP8相对FP16大小没有减半是因为模型量化并被针对所有的层,一般是Linear层的W,bais和其他层没有量化。
| 量化权重 | 说明 |
|---|---|
 | E4M3FN:E4:表示指数(Exponent)使用 4 位来表示. M3:表示尾数(Mantissa)使用 3 位来表示(不包括隐含的最高位). FN:表示使用非规格化数(Flush to Zero)和非标准的 NaN(Not a Number)表示,这是进一步提高计算速度和降低功耗的优化策略。如果应用场景对数值范围要求较高可接受较低的精度,可选表示更大的数值范围的 flux1-dev-fp8-e5m2.safetensors。如果应用场景要求高精度低范围,可选在较小的数值范围内提供了更高的精度的flux1-dev-fp8-e4m3fn.safetensors。flux1-dev-fp8.safetensors is float8_e4m3fn。flux_shakker_labs_union_pro-fp8_e4m3fn.safetensors是https://huggingface.co/Shakker-Labs/FLUX.1-dev-ControlNet-Union-Pro 的fp8的量化版本 |
 | https://github.com/rainlizard/EasyQuantizationGUI (基于llama.cpp)gguf是一种模型量化格式,旨在减少模型大小和提高推理效率。Q4_K_S代表了该模型所采用的量化方案,其中 “Q4” 表示量化精度为 4-bit 整数,“K” 表示采用了 K-means 聚类量化方法,“S” 可能代表了某种特定的变体或设置。 |

















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}