







转载自 红色石头Will,写的很好,通俗易懂,且有具体实例,非常感谢,在此记录方便后续学习和讨论。
1.什么是感知机「Perceptron」
PLA全称是Perceptron Linear Algorithm,即线性感知机算法,属于一种最简单的感知机(Perceptron)模型。
PLA用于解决的是对于二维或者高维的 线性可分 问题的分类,最终将问题分为两类——是或者不是。注意PLA一定是针对线性可分的问题,即可以找到一条线,或者超平面去分开是和不是的两堆数据,如果不是线性可分。
可以通过后来的Pocket改正算法,类似贪心的法则找到一个最适合的。
感知机模型是机器学习二分类问题中的一个非常简单的模型。它的基本结构如下图所示:


以上就是线性感知机模型的基本概念,简单来说,它由线性得分计算和阈值比较两个过程组成,最后根据比较结果判断样本属于正类还是负类。
2.PLA理论解释
对于二分类问题,可以使用感知机模型来解决。PLA的基本原理就是逐点修正,首先在超平面上随意取一条分类面,统计分类错误的点;然后随机对某个错误点就行修正,即变换直线的位置,使该错误点得以修正;接着再随机选择一个错误点进行纠正,分类面不断变化,直到所有的点都完全分类正确了,就得到了最佳的分类面。

经过两种情况分析,我们发现PLA每次w的更新表达式都是一样的:w:=w+yx。掌握了每次w的优化表达式,那么PLA就能不断地将所有错误的分类样本纠正并分类正确。
3.数据准备
导入数据
数据集存放在’…/data/’目录下,该数据集包含了100个样本,正负样本各50,特征维度为2。
import numpy as np
import pandas as pd
data = pd.read_csv('./data/data1.csv', header=None)
# 样本输入,维度(100,2)
X = data.iloc[:,:2].values
# 样本输出,维度(100,)
y = data.iloc[:,2].values
数据分类与可视化
下面我们在二维平面上绘出正负样本的分布情况。
import matplotlib.pyplot as plt
plt.scatter(X[:50, 0], X[:50, 1], color='blue', marker='o', label='Positive')
plt.scatter(X[50:, 0], X[50:, 1], color='red', marker='x', label='Negative')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend(loc = 'upper left')
plt.title('Original Data')
plt.show()

PLA算法
特征归一化
首先分别对两个特征进行归一化处理,即:
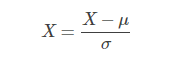
其中,μ是特征均值,σ是特征标准差。
# 均值
u = np.mean(X, axis=0)
# 方差
v = np.std(X, axis=0)
X = (X - u) / v
# 作图
plt.scatter(X[:50, 0], X[:50, 1], color='blue', marker='o', label='Positive')
plt.scatter(X[50:, 0], X[50:, 1], color='red', marker='x', label='Negative')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend(loc = 'upper left')
plt.title('Normalization data')
plt.show()
直线初始化
# X加上偏置项
X = np.hstack((np.ones((X.shape[0],1)), X))
# 权重初始化
w = np.random.randn(3,1)
# 直线第一个坐标(x1,y1)
x1 = -2
y1 = -1 / w[2] * (w[0] * 1 + w[1] * x1)
# 直线第二个坐标(x2,y2)
x2 = 2
y2 = -1 / w[2] * (w[0] * 1 + w[1] * x2)
# 作图
plt.scatter(X[:50, 1], X[:50, 2], color='blue', marker='o', label='Positive')
plt.scatter(X[50:, 1], X[50:, 2], color='red', marker='x', label='Negative')
plt.plot([x1,x2], [y1,y2],'r')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend(loc = 'upper left')
plt.show()

由上图可见,一般随机生成的分类线,错误率很高。
计算scores,更新权重
接下来,计算scores,得分函数与阈值0做比较,大于零则y=1,小于零则y=−1
s = np.dot(X, w)
y_pred = np.ones_like(y) # 预测输出初始化
loc_n = np.where(s < 0)[0] # 大于零索引下标
y_pred[loc_n] = -1
``
`接着,从分类错误的样本中选择一个,使用PLA更新权重系数w。
```cpp
# 第一个分类错误的点
t = np.where(y != y_pred)[0][0]
# 更新权重w
w += y[t] * X[t, :].reshape((3,1))
迭代更新训练
更新权重w是个迭代过程,只要存在分类错误的样本,就不断进行更新,直至所有的样本都分类正确。(注意,前提是正负样本完全可分)
for i in range(100):
s = np.dot(X, w)
y_pred = np.ones_like(y)
loc_n = np.where(s < 0)[0]
y_pred[loc_n] = -1
num_fault = len(np.where(y != y_pred)[0])
print('第%2d次更新,分类错误的点个数:%2d' % (i, num_fault))
if num_fault == 0:
break
else:
t = np.where(y != y_pred)[0][0]
w += y[t] * X[t, :].reshape((3,1))
迭代完毕后,得到更新后的权重系数w,绘制此时的分类直线是什么样子。
# 直线第一个坐标(x1,y1)
x1 = -2
y1 = -1 / w[2] * (w[0] * 1 + w[1] * x1)
# 直线第二个坐标(x2,y2)
x2 = 2
y2 = -1 / w[2] * (w[0] * 1 + w[1] * x2)
# 作图
plt.scatter(X[:50, 1], X[:50, 2], color='blue', marker='o', label='Positive')
plt.scatter(X[50:, 1], X[50:, 2], color='red', marker='x', label='Negative')
plt.plot([x1,x2], [y1,y2],'r')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend(loc = 'upper left')
plt.show()

其实,PLA算法的效率还算不错,只需要数次更新就能找到一条能将所有样本完全分类正确的分类线。所以得出结论,对于正负样本线性可分的情况,PLA能够在有限次迭代后得到正确的分类直线。
总结与疑问
本文导入的数据本身就是线性可分的,可以使用PCA来得到分类直线。但是,如果数据不是线性可分,即找不到一条直线能够将所有的正负样本完全分类正确,这种情况下,似乎PCA会永远更新迭代下去,却找不到正确的分类线。
对于线性不可分的情况,该如何使用PLA算法呢?我们下次将对PLA进行改进和优化。
4.缺点分析
PLA的优缺点:
1.首先,PLA的算法是局限在线性可分的训练集上的,然而我们拿到一个训练集,并不知道其到底是不是线性可分,如果不是,PLA的算法程序将无限循环下去,这样做是不可行的。
2.即使训练集是线性可分,我们也不知道PLA什么时候才能找到一个合适的解,如果要循环很多次才能找到,这对于实际使用是开销很大的。
3.对于线性可分的数据集,一般存在多条满足分类的直线,PLA找到的直线不一定是最优的(很大可能不是最优的,只是其中一条符合要求的解)
5.全部代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
if __name__=='__main__':
data=pd.read_csv('./MachineLearningInAction-master/Perceptron Linear Algorithm/data/data1.csv',header=None)
x=data.iloc[:,:2].values
y=data.iloc[:,2].values
#显示原始数据
plt.scatter(x[:50,0],x[:50,1],color='blue',marker='o',label='positive')
plt.scatter(x[50:,0],x[50:,1],color='red',marker='+',label='negative')
plt.xlabel('feature1')
plt.ylabel('feature2')
plt.title('original data')
plt.legend(loc='upper left')
plt.show()
#归一化
u=np.mean(x,axis=0)
v=np.std(x,axis=0)
X=(x-u)/v
#增加一列,加上偏置
X=np.hstack((X,np.ones((X.shape[0],1))))
w=np.random.randn(3,1)
x1=-2
y1=(-w[2]-w[1]*x1)/w[1]
x2=2
y2=(-w[2]-w[1]*x2)/w[1]
plt.scatter(X[:50, 0], X[:50, 1], color='blue', marker='o', label='Positive')
plt.scatter(X[50:, 0], X[50:, 1], color='red', marker='x', label='Negative')
plt.plot((x1,y1),(x2,y2),color='pink')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend(loc = 'upper left')
plt.title('Normalization data')
plt.show()
for i in range(100):
y_pre1=np.dot(X,w)
y_pre2=np.ones_like(y)
y_pre2[np.where(y_pre1<0)[0]]=-1
num_fault=len(np.where(y_pre2!=y)[0])
print('第%2d次更新,分类错误的点个数:%2d' % (i, num_fault))
if num_fault==0:
break
else:
t=np.where(y_pre2!=y)[0][0]
w+=y[t]*X[t,:].reshape((3,1))
x1 = -2
y1 = -1 / w[1] * (w[2] * 1 + w[0] * x1)
# 直线第二个坐标(x2,y2)
x2 = 2
y2 = -1 / w[1] * (w[2] * 1 + w[0] * x2)
# 作图
plt.scatter(X[:50, 0], X[:50, 1], color='blue', marker='o', label='Positive')
plt.scatter(X[50:, 0], X[50:, 1], color='red', marker='x', label='Negative')
plt.plot([x1,x2], [y1,y2],'r')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend(loc = 'upper left')
plt.show()
6.计算过程截图


















 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









