







基础理论:
半精度浮点数(FP16)对比单精度浮点数(FP32):
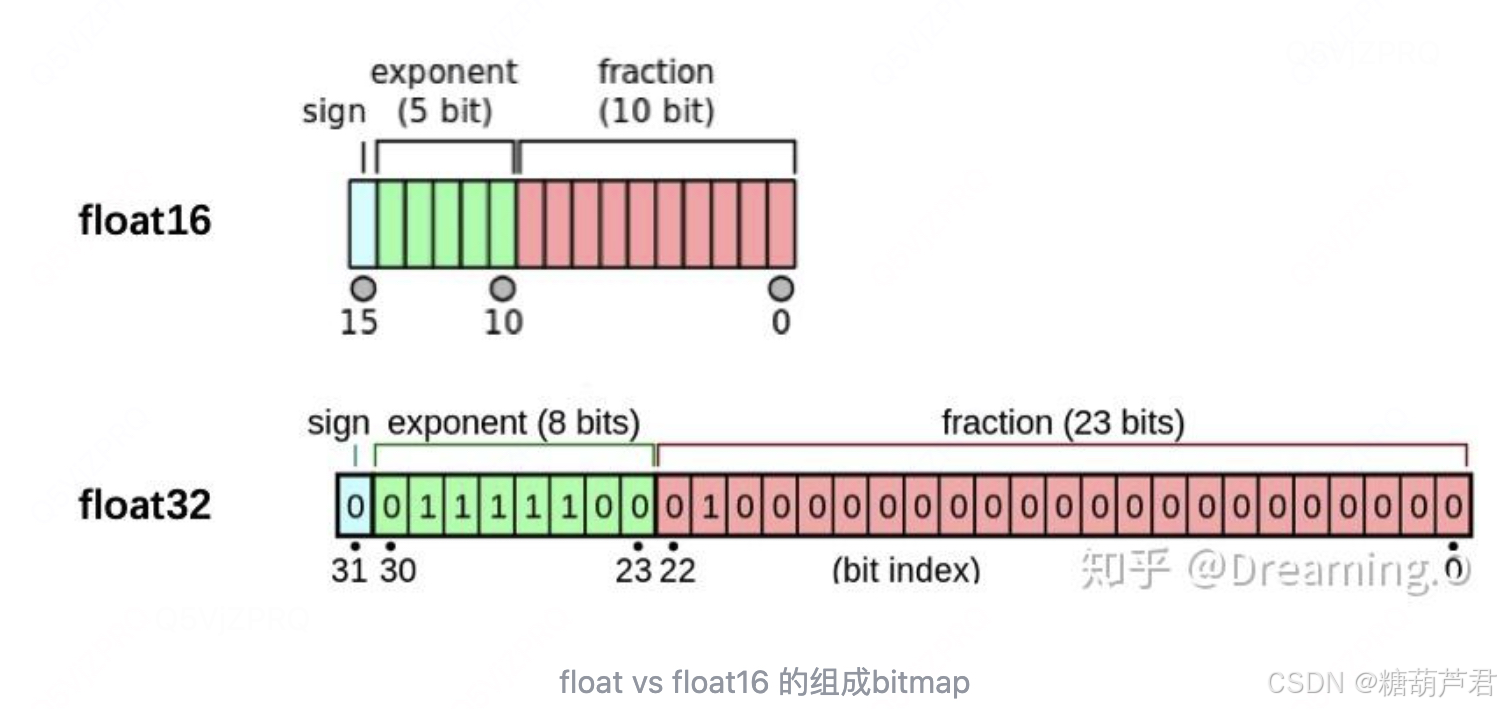
FP16 的格式
FP16 使用 16 位二进制表示一个浮点数,具体结构如下:
1 位:符号位(表示正负)
5 位:指数位(表示数值的范围)
10 位:尾数位(表示数值的精度)
与单精度float(32bit,4个字节)相比,半精度float16仅有16bit,2个字节组成。天然的存储空间是float的一半。
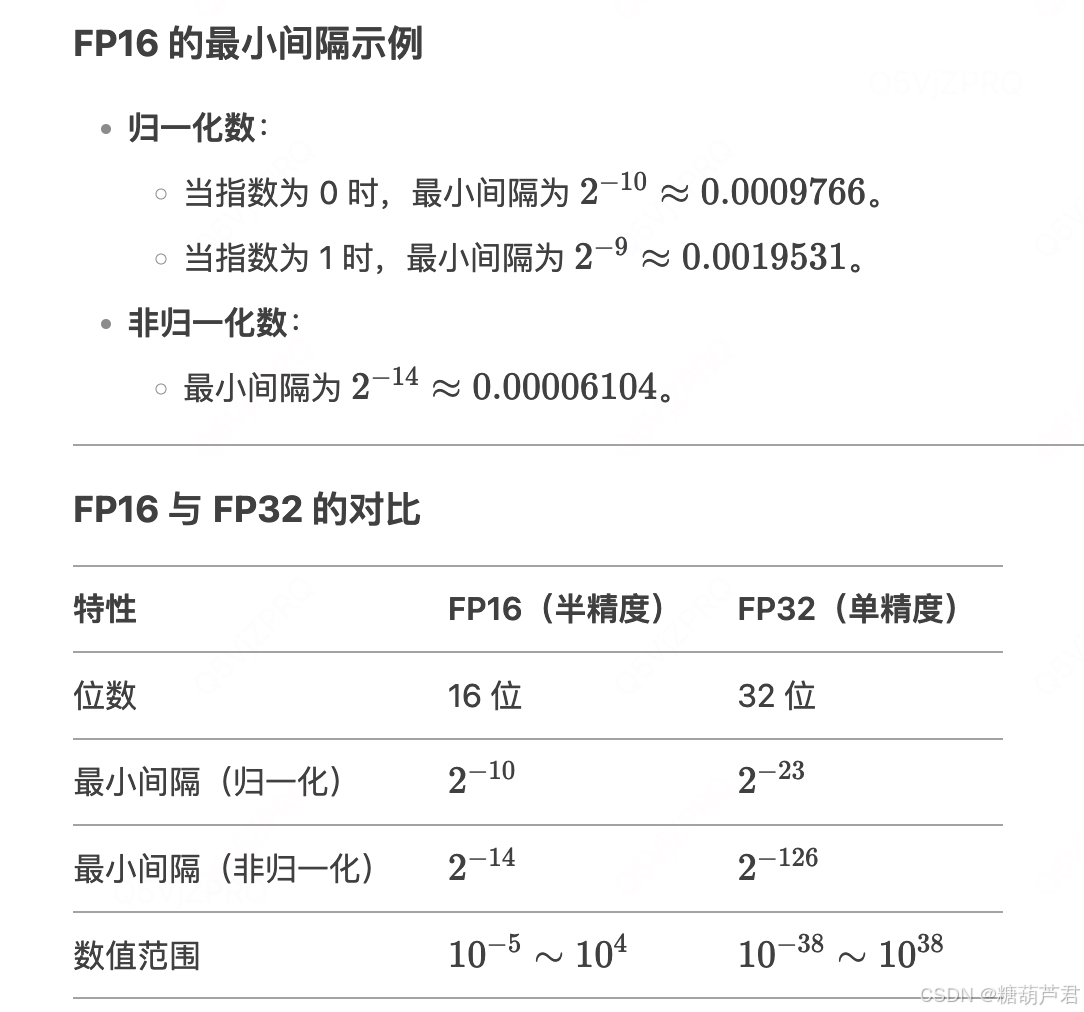
最小间隔:
FP16(半精度浮点数)的最小间隔是指在这种格式下,两个相邻可表示的浮点数之间的最小差值。这个值由FP16的精度决定,反映了FP16能够表示的最小数值变化。如果两个数值的差值小于最小间隔,FP16 无法区分它们。
两者的最小间隔:
混合精度训练:
百度和Nvidia联合推出的论文 MIXED PRECISION TRAINING。
混合精度训练同时使用单精度(FP32)和半精度(FP16)浮点数,利用硬件特性提升计算速度和减少内存占用。
优势
-
加速计算:现代GPU对FP16的计算速度更快。论文指出:在近期的GPU中,半精度的计算吞吐量可以是单精度的 2-8 倍;
-
减少内存占用:FP16占用的内存是FP32的一半,允许更大的批量大小或更复杂的模型。
-
降低能耗:减少内存带宽和计算需求,从而降低能耗。
-
多卡训练时,通讯量减少,加速通讯。
问题:
- 梯度下溢
但是由于FP16的精度表示范围变的狭窄,所以在深度模型训练后期,梯度值变的非常小时,容易出现下溢出的问题:如果梯度值小于 FP16 的最小间隔,会被截断为 0,导致权重更新不准确,模型不收敛。 - 舍入误差:
在混合精度训练中,FP16 用于存储和计算,FP32 用于关键计算步骤。每次从 FP32 转换为 FP16 时,都会引入舍入误差。这些误差在多次迭代中会逐渐累积,影响模型训练的稳定性。
解决方法:
- FP16存储:将模型参数和激活值存储为FP16,减少内存占用。
- FP32计算:在关键计算步骤中使用FP32,避免精度损失。
- 损失缩放:通过缩放损失值,防止梯度下溢。
权重复制(FP32用于计算,FP16用于存储):
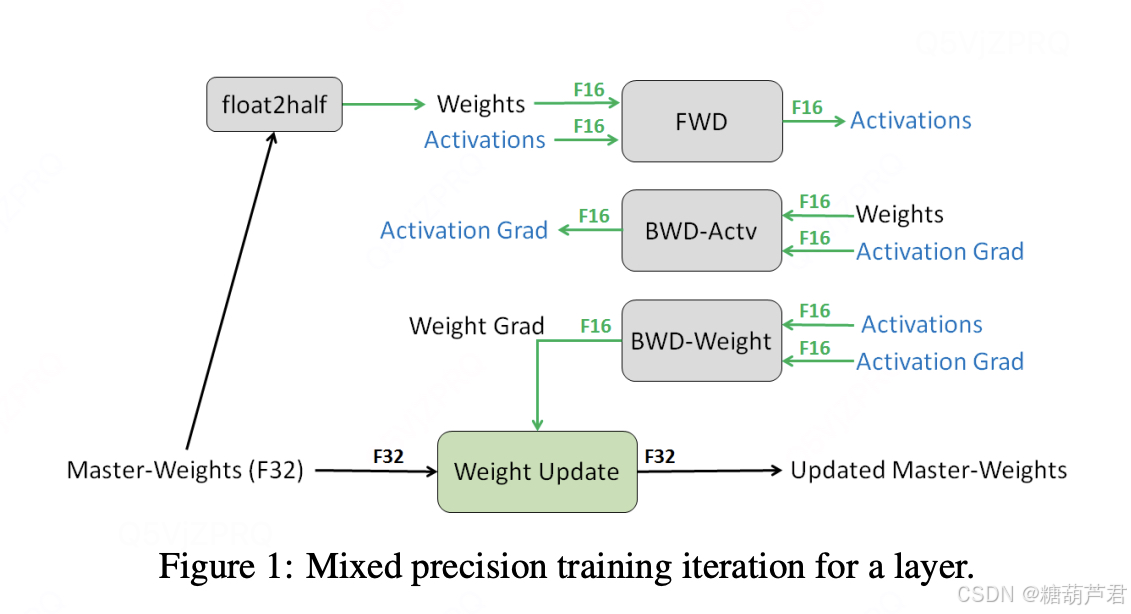
所有值(weights,activations, gradients)均使用 fp16 来存储,而唯独权重weights需要用 fp32 的格式额外备份一次。在更新权重的时候: 权重 = 旧权重 + lr * 梯度,而在深度模型中,lr * 梯度 这个值往往是非常小的,如果利用 fp16 来进行相加的话, 则很可能会出现上面所说的『舍入误差』的这个问题,导致更新无效。因此上图中,通过将weights拷贝成 fp32 格式,并且确保整个更新(update)过程是在 fp32 格式下进行的。
过程:

这样不会导致内存增加吗?其实在训练过程中激活值占据了大半部分显存,而只要激活值使用fp16来存储的话,显存能够减半。
梯度缩放
下图展示了 SSD 模型在训练过程中,激活函数梯度的分布情况:可以看到,有67%的梯度小于
2
−
24
2^{-24}
2−24 ,如果用 fp16 来表示,则这些梯度都会变成0。
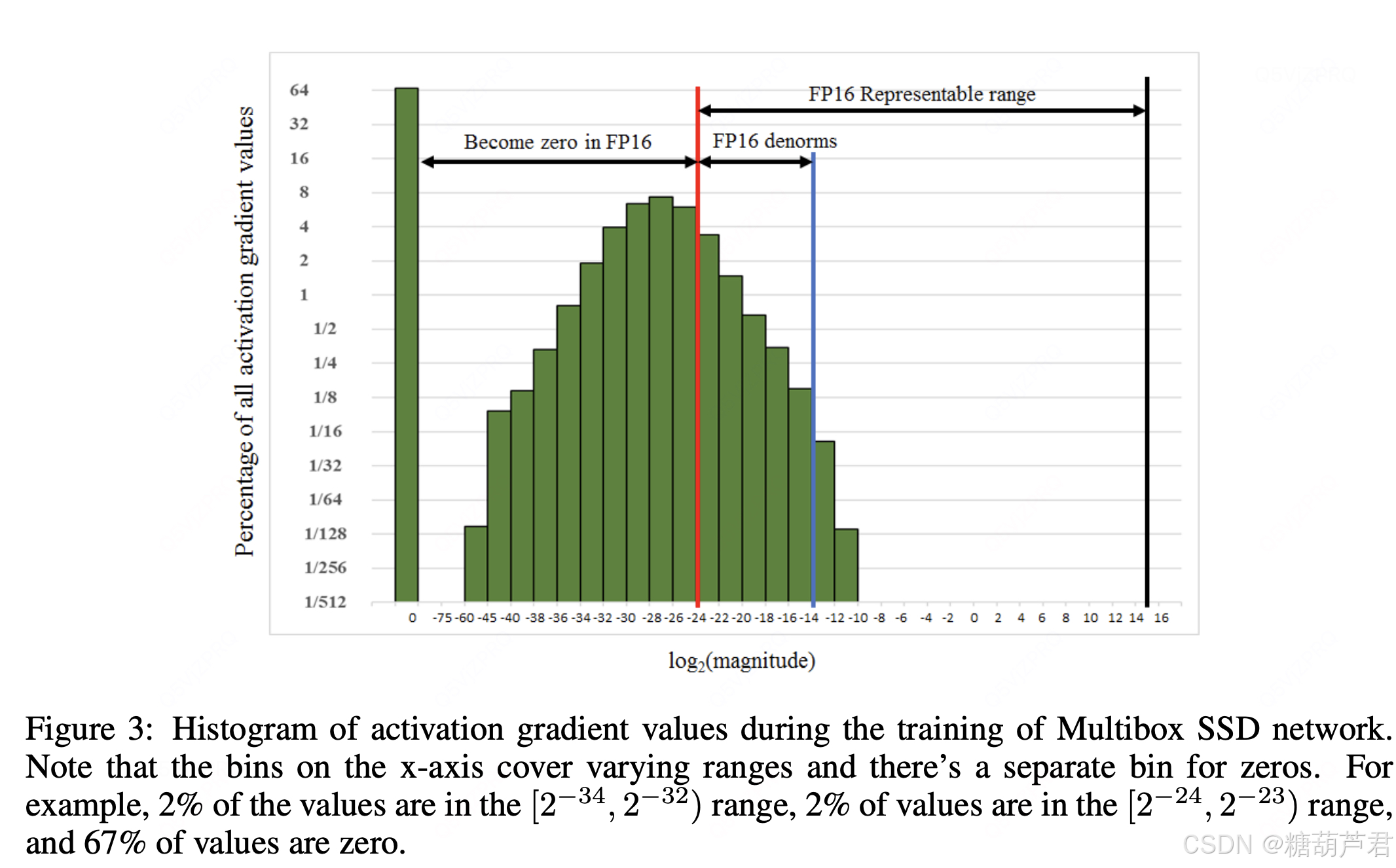
为了解决梯度过小的问题,论文中对计算出来的loss值进行scale,由于链式法则的存在,loss上的scale会作用也会作用在梯度上。这样比起对每个梯度进行scale更加划算。 scaled 过后的梯度,就会平移到 fp16 有效的展示范围内。在反向传播前,将损失值乘以一个缩放因子(如 1024),在梯度更新前,将梯度值除以相同的缩放因子。
API
自动混合精度AMP (Automatic Mixed Precision),它通过一个预先定义的FP16训练安全操作列表。AMP只转换模型中被认为安全的部分,同时将需要更高精度的操作保留在FP32中。另外在混合精度训练中模型中通过给一些接近于零梯度(低于FP16的最小范围)的损失乘以一定数值来获得更大的梯度,然后在应用优化器更新模型权重时将按比例向下调整来解决梯度过小的问题,这种方法被称为梯度缩放。

梯度缩放器scaler会将损失乘以一个可变的量。如果在梯度中观察到nan,则将倍数降低一半,直到nan消失,然后在没有出现nan的情况下,默认每2000步逐渐增加倍数。这样会保持梯度在FP16范围内,同时也防止梯度变为零。
实操
在训练gpt时使用混合精度和梯度缩放之后仍然发现loss出现null:
原因是出现了梯度溢出:
tf.nn.softmax的默认实现为tf.log_softmax,避免直接计算exp出现梯度上溢的情况。
本代码为了mask掉某些token,使用了自定义函数 softmax_ignore_zero (将需要mask的地方加上一个极小值,这样softmax之后的值为0),未先计算log
解决:
将softmax将输入从float16更改为float32,保证softmax的精度足够并且使用学习率warmup策略,解决了训练过程中出现null的情况;
使用混合精度之后,能够在原最大模型的基础上实现batch_size的翻倍。
相关知识:
-
Tensorcore:https://zhuanlan.zhihu.com/p/700036957
-
显存占用情况:
模型权重+优化器+梯度+激活值
对于llama3.1 8B模型,FP32和BF16混合精度训练,用的是AdamW优化器,请问模型训练时占用显存大概为多少?
模型参数:16(BF16) + 32(PF32)= 48G
梯度参数:16(BF16)= 16G
优化器参数:32(PF32) + 32(PF32)= 64G
不考虑激活值的情况下,总显存大约占用 (48 + 16 + 64) = 128G
参考资料:
- https://zhuanlan.zhihu.com/p/103685761
- MIXED PRECISION TRAINING
- 如何解决混合精度训练大模型的局限性问题:https://baijiahao.baidu.com/s?id=1757322130958431259&wfr=spider&for=pc
- soft上溢和下溢问题:https://blog.csdn.net/zx1245773445/article/details/86443099
- 一文讲明白大模型显存占用(只考虑单卡)https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247565072&idx=2&sn=1a94697ed9b5289968e6210214090be0&chksm=eaaa32e01615f923a29195e3109a9456bd6e3076757cea7201c8a8287135af84e5d753d7e96d&scene=27

















 1900
1900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









