






一、复杂背景
二、无人机红外遥感图像
1、遥感技术
遥感(RS-Remote Sensing)——不接触物体本身,用传感器收集目标物的电磁波信息,经处理、分析后,识别目标物,揭示其几何、物理性质和相互关系及其变化规律的现代科学技术。
遥感技术是从远距离感知目标反射或自身辐射的电磁波、可见光、红外线,对目标进行探测和识别的技术。遥感技术利用各种平台(如卫星、飞机、无人机等)上的传感器探测地球表面或大气层的信息,并将这些信息转化为图像数据。遥感图像广泛应用于地理信息科学、环境监测、资源管理等领域,帮助我们了解地球表面和大气层的各种属性和变化。
2、无人机遥感技术
无人机遥感(Unmanned Aerial Vehicle Remote Sensing), 即利用先进的无人驾驶飞行器技术、遥感传感器技术、遥测遥控技术、通讯技术、GPS差分定位技术和遥感应用技术,能够实现自动化、智能化、专用化快速获取国土资源、自然环境、地震灾区等空间遥感信息,且完成遥感数据处理、建模和应用分析的应用技术。无人机遥感系统由于具有机动、快速、经济等优势,已经成为世界各国争相研究的热点课题,现已逐步从研究开发发展到实际应用阶段,成为未来的主要航空遥感技术之一。无人机遥感技术_百度百科![]() https://baike.baidu.com/item/%E6%97%A0%E4%BA%BA%E6%9C%BA%E9%81%A5%E6%84%9F%E6%8A%80%E6%9C%AF/3632548?fr=aladdin
https://baike.baidu.com/item/%E6%97%A0%E4%BA%BA%E6%9C%BA%E9%81%A5%E6%84%9F%E6%8A%80%E6%9C%AF/3632548?fr=aladdin
3、遥感图像
遥感图像是通过遥感技术采集的地面或地表对象的影像数据。为了更清晰地展示地表信息,通常需要对遥感图像进行处理和分析。随着遥感技术的进步,遥感图像的分辨率越来越高,甚至达到亚米级别。
遥感图像主要包括六个种类:可见光遥感图像、全色遥感图像、多/高光谱遥感图像、红外遥感图像、Lidar遥感图像、合成孔径雷达遥感图像。
4、红外遥感器(图像)
红外遥感(infraredremote sensing)是指传感器工作波段限于红外波段范围之内的遥感。
红外遥感器是一种利用红外波段进行探测的设备,主要用于远距离测量和监测。其工作波段通常在0.76至1000微米之间,通过红外敏感元件量测地物的红外辐射能量,从而获得红外图像。红外遥感器的主要类型包括多光谱红外扫描仪、红外热像仪和单通道红外辐射计等,这些设备能够探测远距离外的物体所反射或辐射的红外特性差异,进而确定地面物体的性质、状态和变化规律。
红外遥感图像通常使用红外光谱仪进行采集。具体来说,SIGIS 2遥感遥测成像红外光谱仪是一款用于远距离气体鉴定、定量和化学成像的仪器。它无需外部光源或反射光学元件,通过在视频图像上设定测量区域,自动测试和分析测试结果,并将化学成像叠加到视频图像上。SIGIS 2的特点包括各种软件包、扫描式气体成像系统、自动鉴定和定量各种气体、高光通量、低噪声、被动式远距离探测等。此外,EM 27遥感傅里叶红外谱仪也是一种先进的遥感设备,利用傅里叶变换红外光谱技术进行高精度的光谱测量。它具备高分辨率、高灵敏度和宽光谱范围等特点,广泛应用于环境监测、气象观测、农业调查和地质勘探等领域。EM 27能够检测大气中的温室气体浓度、监测大气污染物、监测农作物生长状态等。
因为红外遥感在电磁波谱红外谱段进行,主要感受地面物体反射或自身辐射的红外线,有时可不受黑夜限制。又由于红外线波长较长,大气中穿透力强,红外摄影时不受烟雾影响,透过很厚的大气层仍能拍摄到地面清晰的像片。但是,它仍存在分辨率差、对比度低、信噪比低、视觉效果模糊等缺点。
(1)红外热成像技术原理
为了满足人能看到这一需要,将红外热转化成图像。对于目标检测算法来说,并不一定要“看到图像”,它可以检测红外辐射能量分布图形(波或电信号),也可以检测红外热像图。红外热成像技术原理与发展![]() https://blog.csdn.net/maopig/article/details/80856900
https://blog.csdn.net/maopig/article/details/80856900
(2)红外视觉1:近红外与中远红外图像
红外摄像头与红外热成像的区别!!!_近红外相机能对人体热成像嘛?-CSDN博客![]() https://blog.csdn.net/YUNZHUO666/article/details/142364726?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~Ctr-5-142364726-blog-80856900.235%5Ev43%5Epc_blog_bottom_relevance_base6&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~Ctr-5-142364726-blog-80856900.235%5Ev43%5Epc_blog_bottom_relevance_base6红外视觉1:近红外与中远红外图像_近红外图像-CSDN博客
https://blog.csdn.net/YUNZHUO666/article/details/142364726?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~Ctr-5-142364726-blog-80856900.235%5Ev43%5Epc_blog_bottom_relevance_base6&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~Ctr-5-142364726-blog-80856900.235%5Ev43%5Epc_blog_bottom_relevance_base6红外视觉1:近红外与中远红外图像_近红外图像-CSDN博客![]() https://blog.csdn.net/qq_40985985/article/details/127497451?ops_request_misc=%257B%2522request%255Fid%2522%253A%252281b8af1019ae8cebf669e6c4157ab091%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=81b8af1019ae8cebf669e6c4157ab091&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-4-127497451-null-null.142%5Ev100%5Epc_search_result_base9&utm_term=%E7%BA%A2%E5%A4%96%E5%9B%BE%E5%83%8F&spm=1018.2226.3001.4187
https://blog.csdn.net/qq_40985985/article/details/127497451?ops_request_misc=%257B%2522request%255Fid%2522%253A%252281b8af1019ae8cebf669e6c4157ab091%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=81b8af1019ae8cebf669e6c4157ab091&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-4-127497451-null-null.142%5Ev100%5Epc_search_result_base9&utm_term=%E7%BA%A2%E5%A4%96%E5%9B%BE%E5%83%8F&spm=1018.2226.3001.4187
(3)不同种类遥感图像汇总——红外遥感图像
不同种类遥感图像汇总 !!-CSDN博客![]() https://blog.csdn.net/leonardotu/article/details/136218540
https://blog.csdn.net/leonardotu/article/details/136218540
5、相关数据集
(1)NUDT-SIRST数据集
一个专门为红外弱小目标检测设计的数据集,包含了1327张训练数据和验证数据。NUDT-SIRST数据集是由国防科技大学(National University of Defense Technology, 简称NUDT)的研究人员开发,旨在为红外弱小目标检测领域提供丰富的资源。该数据集包含了1327张图像,这些图像经过精心筛选和标注,确保了数据的质量和多样性。
在红外弱小目标检测中,由于目标信号弱、像素少,且容易沉浸在高噪声和杂波背景中,因此检测难度较大。NUDT-SIRST数据集的设计正是为了应对这些挑战,通过提供多样化的图像数据,帮助研究人员和开发者改进和评估他们的检测算法。
红外弱小目标数据集-NUDT-SIRST1-CSDN博客![]() https://blog.csdn.net/gitblog_09787/article/details/143005147
https://blog.csdn.net/gitblog_09787/article/details/143005147
(2)IRSTD-1K数据集
一个专注于红外小目标检测的数据集,提供了1000幅图像及精细像素标注。该数据集包含了1000幅具有不同形状、尺寸及场景的真实图像,背景具有精确的像素级注释。这些图像涵盖了各种目标形状、大小和丰富的杂波背景,为红外小目标检测算法的研究提供了丰富的资源。IRSTD-1K数据集分为两个文件夹,IRSTD1k_Img存放真实图像,IRSTD1k_Label存放标签mask。mask指的是与图像对应的标签掩码,用于标注图像中的目标区域。
超经典!分割任务数据集介绍。_irstd-1k-CSDN博客![]() https://blog.csdn.net/jijiarenxiaoyudi/article/details/128042741 (3)NUAA-SIRST数据集2021
https://blog.csdn.net/jijiarenxiaoyudi/article/details/128042741 (3)NUAA-SIRST数据集2021
一个高质量的红外弱小目标检测数据集,包含427幅真实图像和相应的标签。NUAA-SIRST数据集包括427幅高质量真实红外图像及其标签,共包含480个目标,其中许多目标非常微弱且嵌入在复杂背景中。这些图像被分为213幅训练图像和214幅测试图像,以支持算法的训练和评估过程。数据集中的红外弱小目标具有“弱”和“小”的特点。“弱”指的是在复杂背景下,目标与背景特征相似,易被淹没在背景中,一般对比度小于15%,且在远距离成像中耗散了较多能量以致其信杂比(Signal-to-Clutter Ratio, SCR)不大于3;“小”则是指远距离成像造成的成像大小在2×2−9×9像素之间,目标缺乏可区分的形状和纹理信息。
(4)WideIRSTD 数据集2024
这个数据集包含七个公开数据集,包括SIRST-V2, IRSTD-1K, IRDST, NUDT-SIRST, NUDT-SIRST-Sea, NUDT-MIRSDT, Anti-UAV等。它涵盖了多种目标形状、波长、图像分辨率和成像系统。数据集用于评估资源有限条件下的红外小目标检测性能。
(5)地/空背景下红外图像弱小飞机目标检测跟踪数据集2019
地/空背景下红外图像弱小飞机目标检测跟踪数据集![]() http://www.csdata.org/p/387/3/
http://www.csdata.org/p/387/3/
(6)DenseSIRST数据集2024
(7)SIRST Augment 数据集2023
(8)HIT-UAV数据集2024(重点看)
(9)SIRST-V2数据集2023
YimianDai/open-sirst-v2![]() https://github.com/YimianDai/open-sirst-v2
https://github.com/YimianDai/open-sirst-v2
(10)DMIST-60和DMIST-100数据集2024
(11)Anti-UAV410数据集2023
三、弱小目标
四、检测算法
1、研究思路
在确定好研究方向时,可以先测自己数据集的对比试验。经典且流行的对比试验有:SSD、Faster-RCNN、YOLO系列(如YOLOv3、YOLOR、YOLOX)、RTMDet、GOLD-YOLO、YOLO-MS、PP-YOLO系列、DETR系列等。
测试好自己的baseline(通常指的是一种标准的算法或方法,用作评估其他新算法或改进算法性能的参照点。),明白自己的一个大体方向,进而为自己的模型修改做出依据。【零基础保姆级教程】零基础如何快速使用YOLO算法进行科研?_yolov7保姆级教程-CSDN博客![]() https://blog.csdn.net/2401_84870184/article/details/138656646 红外小目标检测相关算法?1、2、3、4、5、6...基于小目标检测头的改进YOLOv5红外遥感图像小目标检测系统_small target detection in uav image based on lmpro-CSDN博客
https://blog.csdn.net/2401_84870184/article/details/138656646 红外小目标检测相关算法?1、2、3、4、5、6...基于小目标检测头的改进YOLOv5红外遥感图像小目标检测系统_small target detection in uav image based on lmpro-CSDN博客![]() https://blog.csdn.net/qunmasj89/article/details/134218290?spm=1001.2014.3001.5502
https://blog.csdn.net/qunmasj89/article/details/134218290?spm=1001.2014.3001.5502
2、yolov11算法
(1)学习模型结构并运行
Qunmasj-Vision-Studio/hnogwai203: 遥感红外小目标检测系统源码和数据集:改进yolo遥感红外小目标检测系统源码和数据集:改进yolo11-RevCol11-RevCol https://github.com/Qunmasj-Vision-Studio/hnogwai203?tab=readme-ov-file
https://github.com/Qunmasj-Vision-Studio/hnogwai203?tab=readme-ov-file
(2)相关性能指标
如何正确解读YOLO算法训练结果的各项指标 - 知乎![]() https://zhuanlan.zhihu.com/p/708351464 使用YOLO进行目标检测训练之后,会在runs\detect\train下生成一些训练过程和结论文件。
https://zhuanlan.zhihu.com/p/708351464 使用YOLO进行目标检测训练之后,会在runs\detect\train下生成一些训练过程和结论文件。
1)weights文件夹:最终的“仙丹”
里面有俩文件best.pt和last.pt。best.pt是整个训练过程中,性能最好的模型权重文件。最终我们要的就是这个文件。我们可以拿它进行实际业务的AI预测或继续微调。last.pt是最后一次训练的模型权重文件。一般来说,训练越久效果也越好。但有时它也会和best.pt不一致。这意味着最后一次训练的结果,并不是最好的。
2)results.png:训练总图要略
这张图片包含训练过程中的各种评估指标,比如损失函数、精度、召回率、mAP等的图表绘制。这个图表可以直观地看到模型训练过程中性能的变化情况。
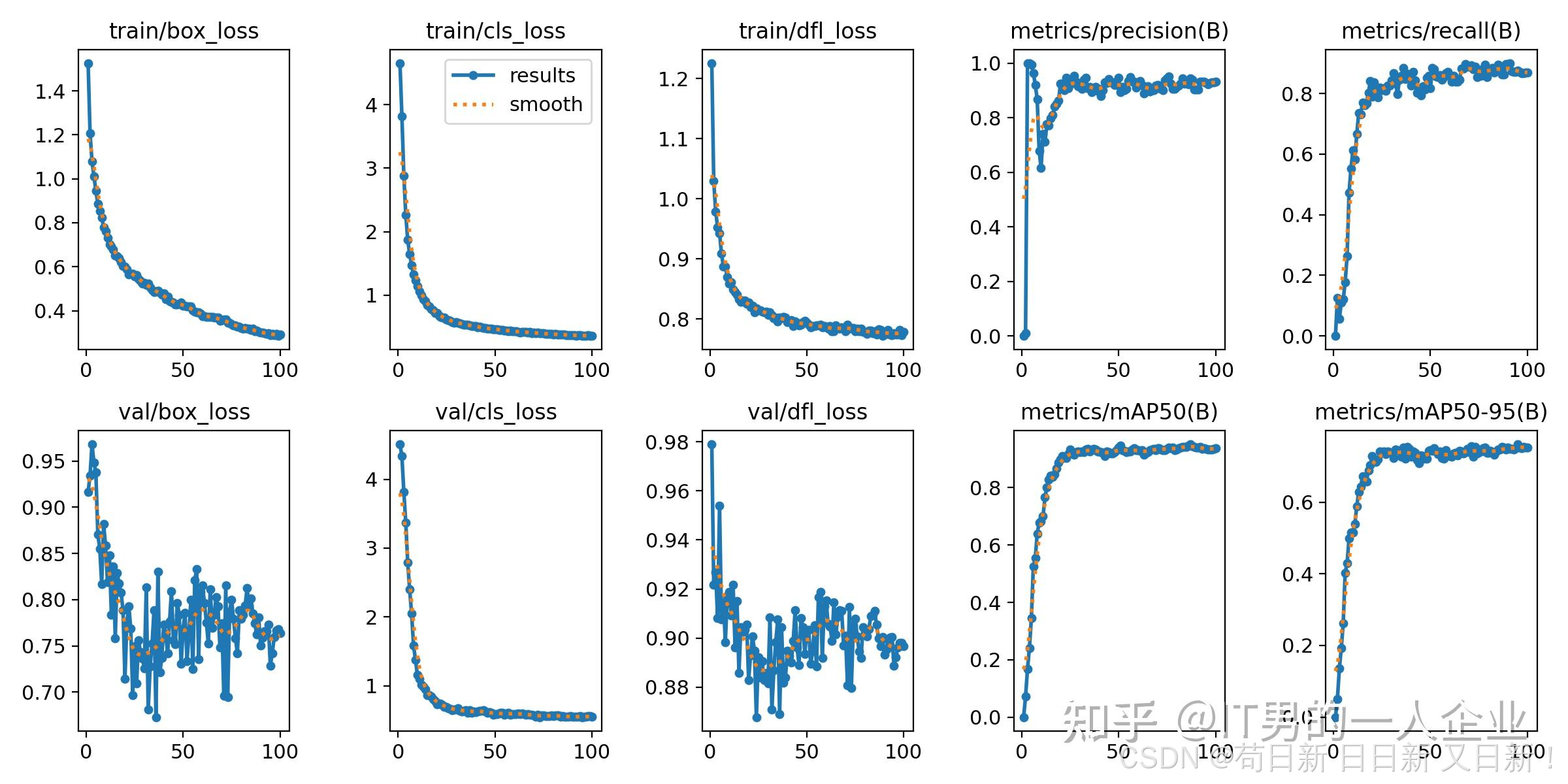
loss系列:打明牌的能力
我们先看前3列:train/box_loss和val/box_loss ,train/cls_loss和val/cls_loss,train/dfl_loss和val/dfl_loss。
这几组前面的train表示训练集,val是验证集。训练集是用于训练学习的,相当于书本的例题。而验证集则用于考试,相当于试卷的试题。学得好不一定就考得好,主要还得看考题是不是有关联性。不过他们更重要的相同点,好像在于都有loss。
在有监督训练中,我们是先标记再训练。其实这就是打明牌,本身就知道问题和答案。对于训练集和验证集,AI本身是知道这个区域标的是什么,位置在哪儿。因此,它会先猜测结论,然后跟正确答案做对比。它的猜测行为称为“推理”或者“预测”。它自己的推理结果和人工标记的答案之间的差异,称为“损失”。那么,损失越小越好,损失为0则说明AI的推理和正确答案之间没有差异,即预测100%命中。
我们看下图,这次训练过程也是如此。这几个train系列的loss都是降低的,X轴表示训练轮次,Y轴表示损失的值。我们看到loss的值都是降低,这说明很好。但是第一个box_loss好像还有下降的趋势。但是中间的cls_loss在50轮时就已经趋于稳定了,而dfl_loss好像在75轮附近才慢慢稳定。
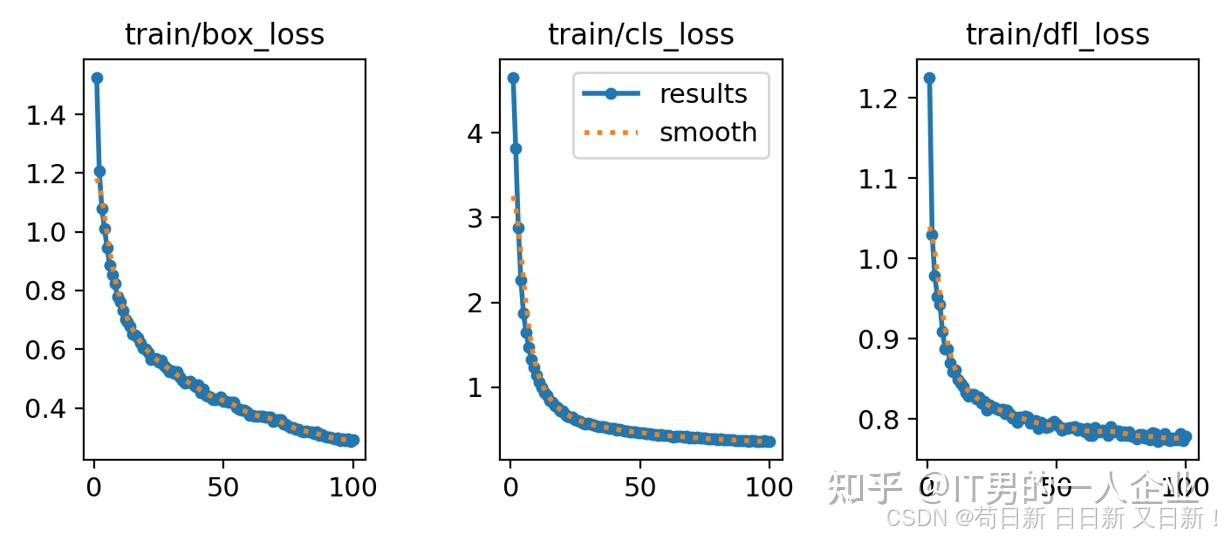
box_loss 边界框损失:衡量画框
box_loss全称是bounding box loss,表示边界框损失。它表明AI通过训练和学习之后,对于边界框的预测和标准答案之间的损失。正常情况下,随着训练的进行,损失是越降越低的。如果它是长期忽高忽低,或者一直不明显收敛,那说明训练存在问题。如果box_loss的损失不断降低,而后持续稳定,则说明训练没有问题,也没有必要再投入资源训练了。

但是box_loss表现优秀,仅仅说明它对物体区域(画框)的识别情况。就算这一项100分,整体效果也不一定就好。因为光会画框意义不大,我们还要知道框里的物体是什么。于是就引入另一个cls_loss指标。
cls_loss 分类损失:判断框里的物体
cls_loss全称为classification loss,表示分类损失。它衡量的是预测类别和真实类别之间的差异。我们看下面的图,它不但框出了物体。而且标注出了这个框里是人,那个框里是车,哪个是细菌,哪个是垃圾。

对于框里物体是什么的评价,就用到了cls_loss指标。从这里可以看出,其实目标检测技术已经包含了图片分类的技术。图片分类很基础,它的损失收敛得最快,仅仅训练几十次就稳定了。如果你认为它仅凭哪个区域、什么物体两项指标就结束了,那么确实是小看YOLO算法了。它还有第三项细化指标dfl_loss。
dfl_loss 分布式焦点损失:精益求精
dfl_loss全称是Distribution Focal Loss,中文名称为“分布式焦点损失”。 它辅助box_loss,提供额外的信息,通过对边界框位置的概率分布进行优化,进一步提高模型对边界框位置的细化和准确度。
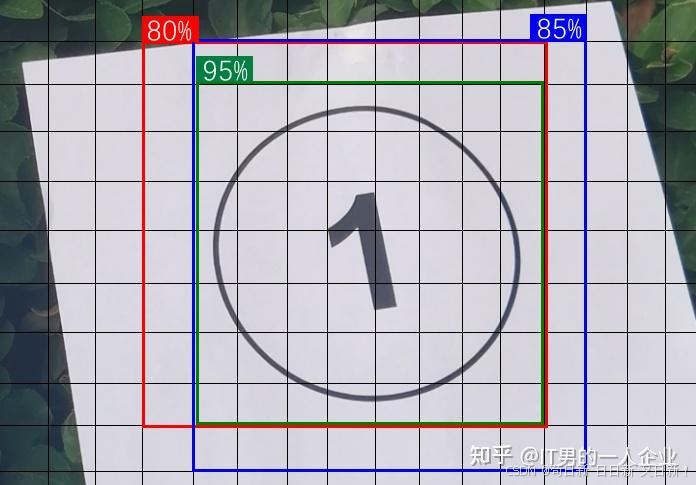
如上图所示,AI模型成功预测出了①的位置。但是红、蓝、绿3个框中的①,好像哪个都没错。因此dfl_loss提供了一个可信度,表明哪一个焦点跟标准答案相比,会更加精确。
验证集:学得好,不一定考得好
上面是训练集的loss。下面说说验证集的loss。从规范上讲,验证集和训练集是永远不见面的。这么做是为了验证AI是否真正学到了数据的特征和精髓,而非是靠死记硬背所见过的数据。也就是说模型在经过几番训练集数据的学习之后,将面对从来没有见过的验证集数据。它将给出预测答案,然后再去对照标准答案。两个答案的差异,就是验证集的损失。看下面这个验证集曲线的趋势。
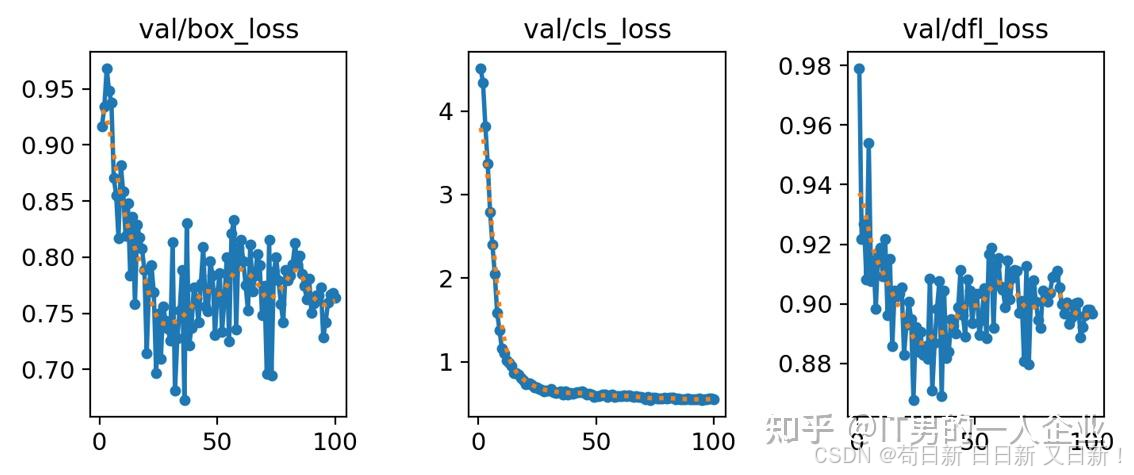
相比训练集的平滑趋势,验证集似乎是有些反复。其实,这是一种常见现象。只要验证集损失没有显著上升,整体趋势在变好,且与训练集损失的差距不是特别大,这一般是正常的。不过,要留意以下细节:
- 样本数据的变异:验证集可能包含一些与训练集不同风格的样本,这会导致损失不稳定。好比你拿着泰迪狗做识别训练,最后让模型去认识哈士奇狗,模型有点迷糊,拿不准。
- 模型的过拟合:如果验证集的样本数据正常。模型在训练集上的损失表现很好,但是验证集表现不稳定。那么可能是模型记住了训练集的细节,也就是过于死记硬背,只抓住形没有抓住神。这叫过拟合。
如果遇到比较严重的问题,或者你感觉有问题,该怎么办呢?
可以调整超参数,比如调小学习率,或者使用提前停止策略来防止过拟合。也可以调整batch大小,增加一个批次数量,让它见多识广。同时,增加训练数据量或使用数据增强技术,可以使模型更好地泛化,减少验证损失的波动。
不要小看验证集的指标,这是衡量模型效果的第一道关卡。因为训练集的结果指标顶多算是自娱自乐,这有点像学校内部的月考、期末考试。而验证集则更像是高考。因此,对于验证集的检测,还有更多指标。
精度和召回率:又准又全的考量
results.png的后两列是同一类指标。metrics表示模型是在验证集上的评估指标。(B)在目标检测任务中表示Bounding Box,即边界框的检测结果。
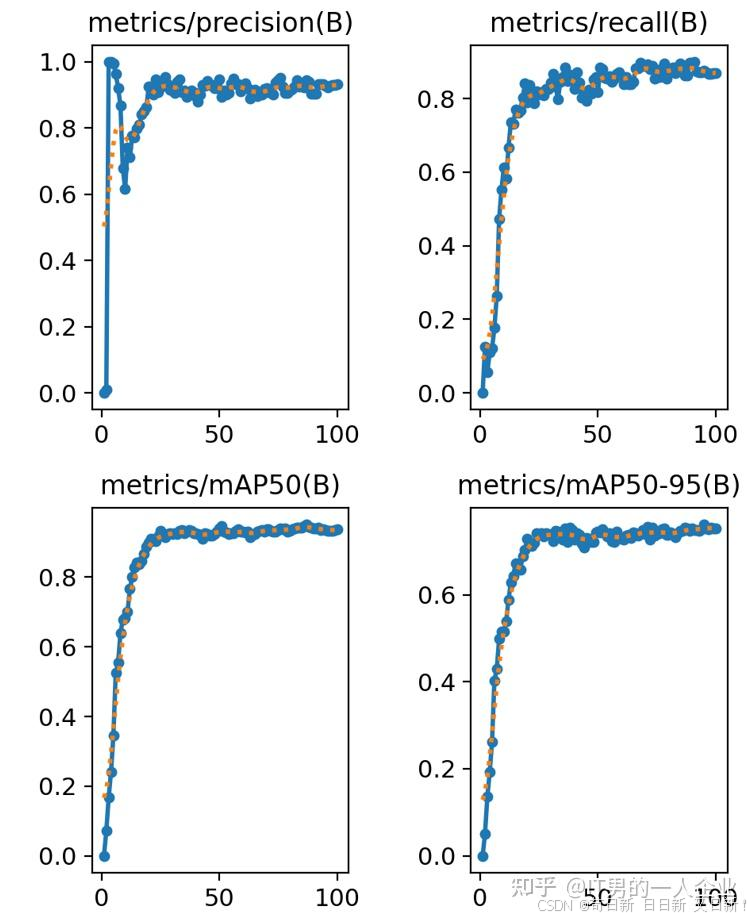
首先,左上角的第一个preciision是精度,或者称为“精确率”。请注意,是精确率,不是准确率。准确率有专门的名词accuracy。两者不一样。
准确率表示预测正确的占比。比如1000件产品中,900件合格。我的AI模型全都找出来了,这时准确率是100%。准确率存在一个问题,尤其对于少数个体而言不公平。比如预测绝症,100个人预测对了90个人是健康的,预测错了10个病危的人。虽然准确率是90%,但这属于严重事故。于是,精确率的可以解决这个问题。
精确率会从100个里随便抽出10条数据,如果预测错了5个,那么精确率就是50%。高准确率保证的是多数都正确,而高精确率是保证每一个都不出错。
我们看到第一个精确率的图表,大约30轮左右趋于稳定了,而且向1(100%)靠拢。这说明效果不错。精确率就没有问题吗?也有问题!精确率考核的是出错率,只要不出错,哪怕只干好一件事,也是100%。如果精确率指标它挑活干,那么就完犊子了。工作、生活中也有这类情况,就是拣着好做的工作去做,结果干得很漂亮。
因此,这时又引入了另一个指标,也就是第二幅图中的召回率recall。召回率的口号是:“宁可做错一千,绝不漏掉一个”。鼓励大家抢着做,谁眼里没活就打低分。这样就解决了那些少干活、拣活干的情况。其实召回率recall和精确率precision是矛盾的。两者的值很难都高。因为既要脏活、累活、杂活都揽下,还要不允许出错。这对于机器或者人类都是很大的挑战。但是,考核指标就是要这样的。就要想尽一切办法堵住漏洞。我们看第二幅图中召回率也是在提高的,这说明检测范围在不断扩大,大约在0.8处浮动。因此从前两张图我们可以说,这次训练precision精度是0.9,召回率recall为0.8。
关于P(precision)和R(recall)之间的数据趋势,也有具体的图示。
runs\detect\train下面有P_curve.png,每项精度的曲线;R_curve.png,每项召回率的曲线;PR_curve.png则是两者互相妥协的曲线。这个PR图越接近正方形效果越好。都接近正方形,说明整体效果又准又全。
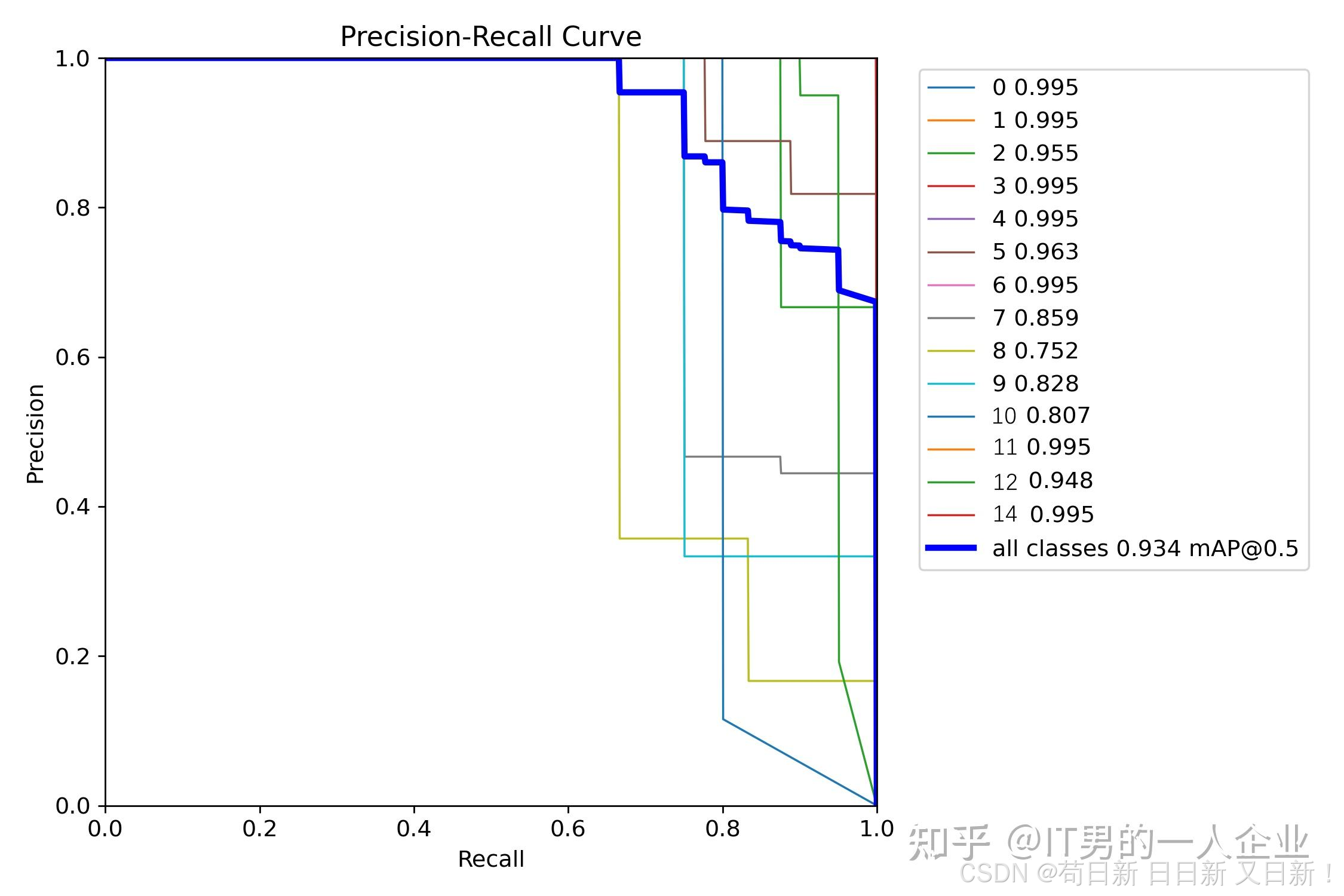
看上图,蓝色总线接近正方形。但是具体到分类为8的目标,有些拖后腿。
results.png系列还剩两张图片,mAP50与mAP50-95。mAP50要拆开看,拆成mAP-50,mAP表示mean Average Precision,称为平均精度;50则是在IoU阈值为50%的情况下的值。
IoU是Intersection over Union,是目标检测中用于衡量预测边界框与真实边界框重叠程度的指标。YOLO的特点,You Only Look Once(你仅需看一遍),这项优势也导致它出现很多备选框。这些预测出的框框儿,可能是物体的全部,也可能只是中心部分,还或许仅仅是物体的一个角。不管如何,这都是算法通过学习特征计算出来的。谁是谁非,看你怎么选择。如果预测出的面积(蓝框)能占到实际区域(红框)的50%以上,那么我们就说IoU为50。重合度能到50%,其实能说明AI大体猜中了。因为IoU为100就是完全重合。
mAP50是重合度以50%为界限的平均精度,指标相对宽松,能够展示模型在较低严格度下的整体性能。它更适用于那些对定位要求不是特别严格的应用场景。而mAP50-95则是IoU阈值从50%到95%范围内的平均值。这个更加严格一些。因此,我们看到图里面mAP50-95的值确实也低一些。意味着在严格的IoU条件下也能准确检测和定位目标。它适用于那些对定位要求较高的应用场景,如自动驾驶、医疗影像分析等。
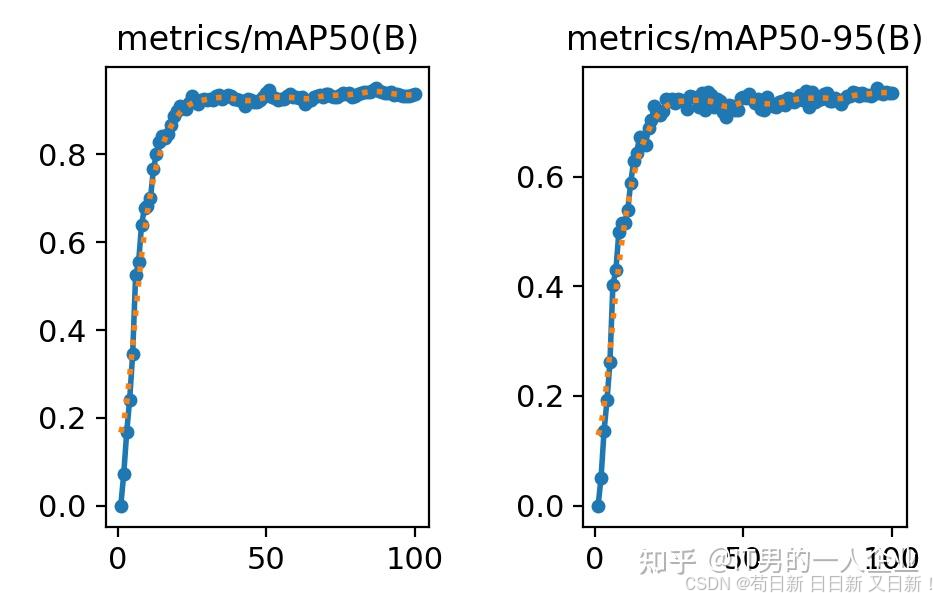
因此,如果觉得现在的模型识别效果不好,对精度要求又不高能大体定位就行,其实可以调低IoU的值。
3)results.csv:图表里的数据明细
runs\detect\train下有一个results.csv表格文件,是上面刚刚讲的很多图表的数字版本。如果你想查询某次训练某项指标的具体值,可以从这个表格中查找。
4)labels系列:分类标签的分布
上面说了,这里面是从0到14,共检测15项物体。那么关于这15项物体的分布情况,我们可以从labels.jpg查看。
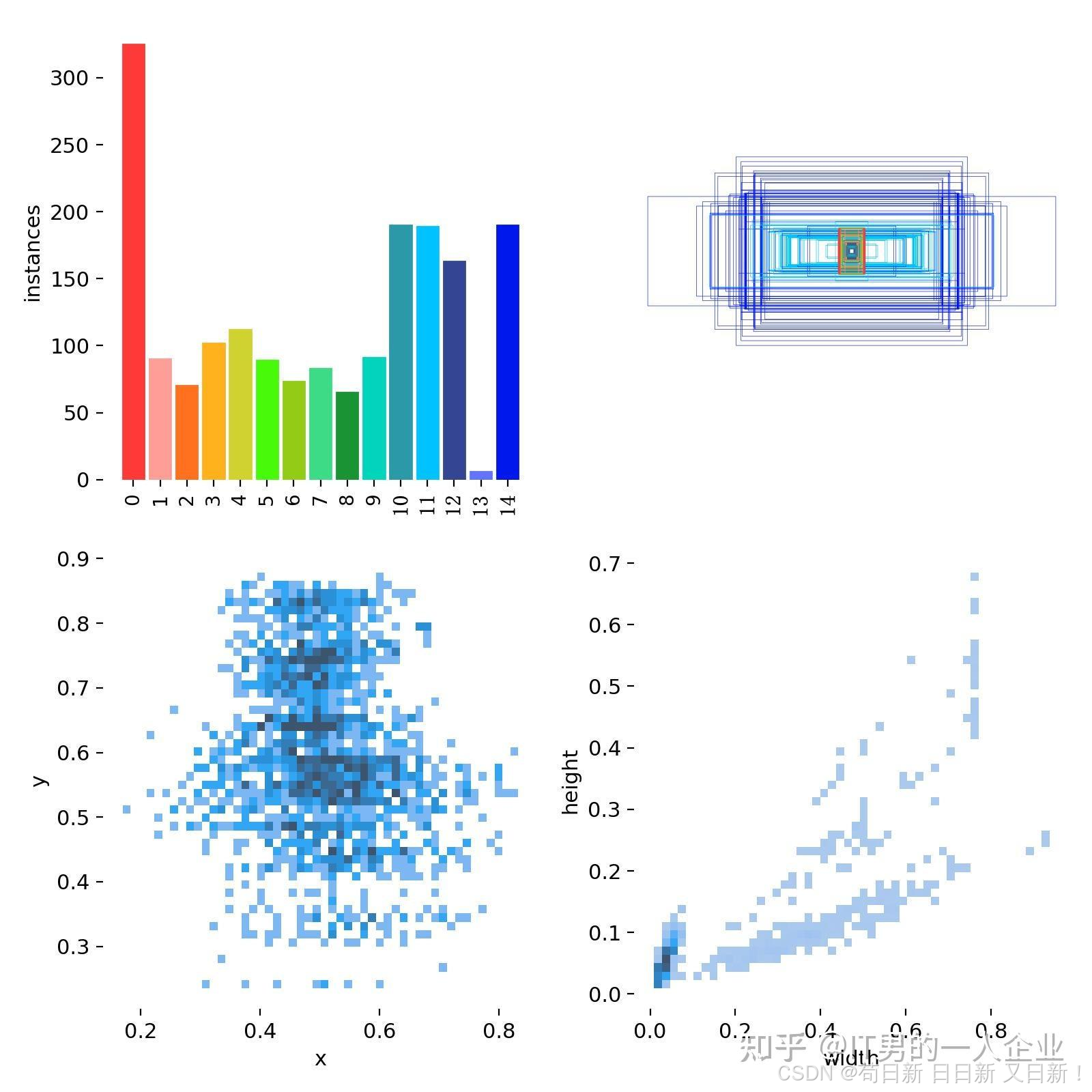
看上图第一项,很明显有一个问题。那就是第13分类的样本数太少。这也导致比如上面的P曲线、R曲线没有第13分类的信息(没注意可以滑上去再看看)。这是因为样本过少,被淹没、忽略了。
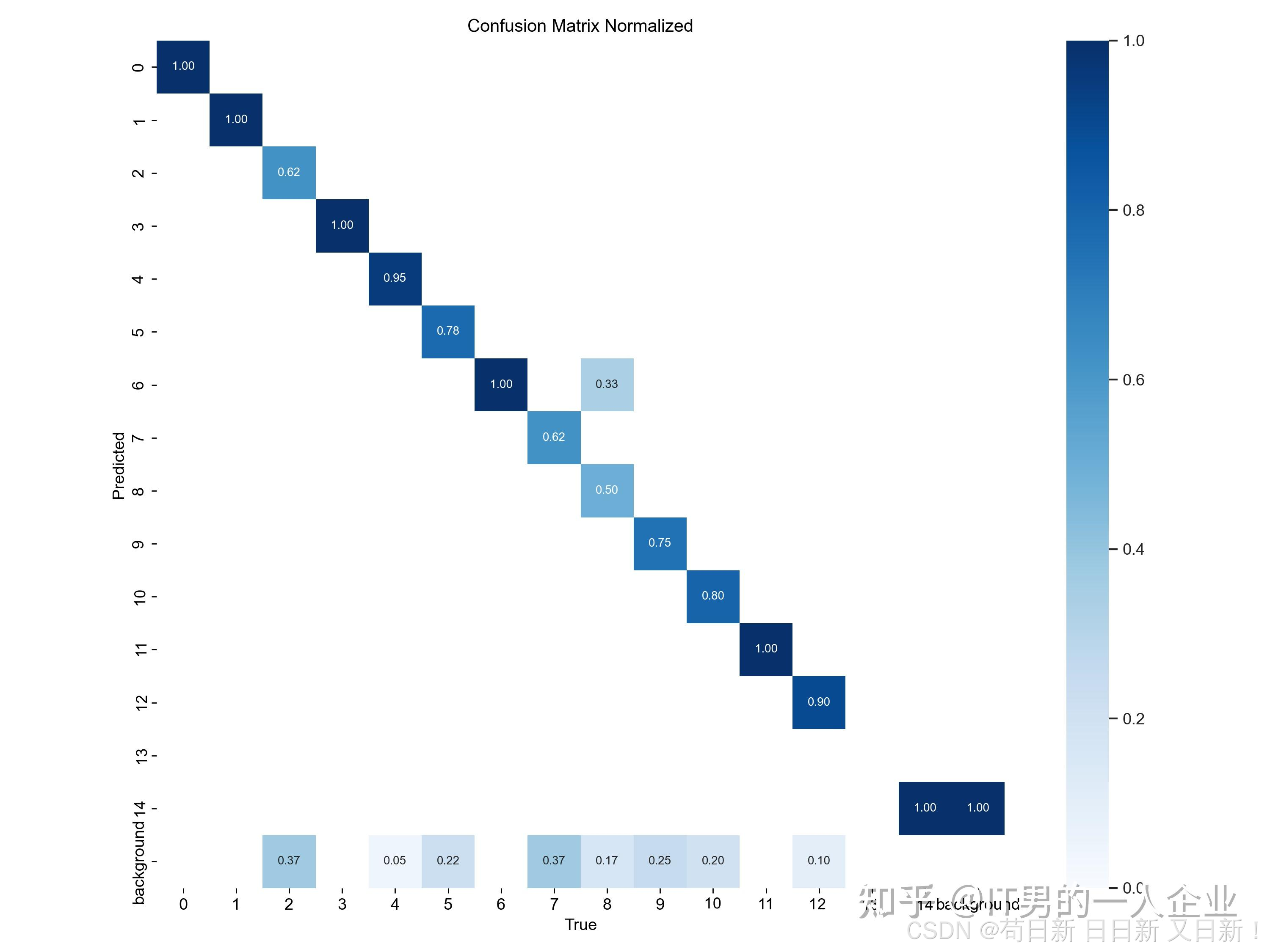
下面是是混淆矩阵的归一化版本,对应的图片是confusion_matrix_normalized.png。这里可以更清晰地展示模型在各类别上的性能表现。我们也可以看到第13类别数据为空。
(3)创新点
1、2、3、4、5、6、7......?

















 1882
1882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









