









ST3D++: Denoised Self-training for Unsupervised Domain Adaptation on 3D Object Detection
如题,本文是ST3D的改进版。没看过ST3D的可以先去阅读一下: ST3D
主要介绍与ST3D的区别(改进之处):
1.添加了伪标签的分类信息
2.考虑了源域和目标域之间的数据分布问题设计了特定域的归一化和联合优化方式。
首先给出文章的总结:
- 在Waymo, nuScenes, KITTI, Lyft 四个流行的3D检测数据集上进行首次尝试域迁移。
- 兼顾定位质量和分类精度 提出source-assisted 训练策略:特定域的归一化和联合优化
- 对三维物体检测中的伪标签质量进行了研究,提出五个定量指标
- 探索利用时间信息通过融合的顺序点帧来进一步改进ST3D++
Method
Hybrid Quality-aware Criterion for Scoring
IoU和Cls在不同类别有着不同的效果:

为了同时评估定位和分类的质量,提出了一种基于IOU的标准,该标准进一步与基于置信度的标准相结合来评估预测质量,将ST3D中的u评分替换为o:
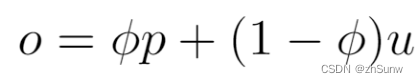
p,u分别为分类分数和IoU分数,作加权相加。
Source-assisted Self-denoised Training(SASD)
采用了特定领域的归一化(Domain Specific Normalization)方法和通过对源数据和伪标记的目标数据进行联合优化(Optimization Objective)来减少误差累积
Domain Specific Normalization:用一个非常简单的特定于域的归一化(DSNorm)层来替换每个BN层,它在归一化层分离了不同域的统计估计
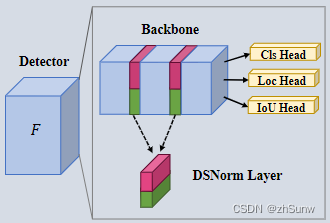
d ∈ {s, t}
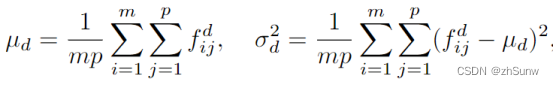
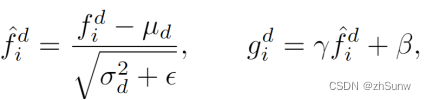
Optimization Objective:综合考虑这两个领域的联合
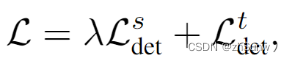
EXPERIMENTS
在Waymo->KITTI的结果最好,各个类别均超过了Oracle,其中改进在Pedestrian和Cyclist上效果明显:远高于ST3D
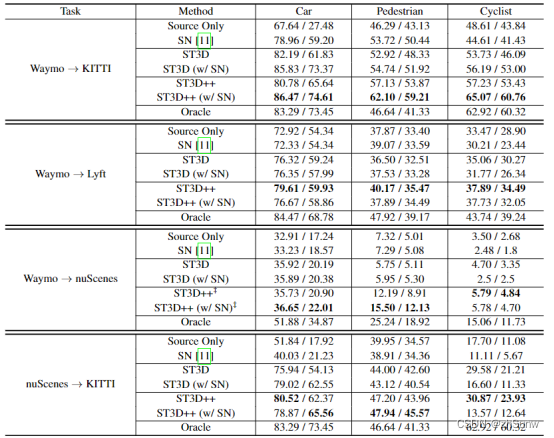
在Nusense->KITTI的多帧信息实验:
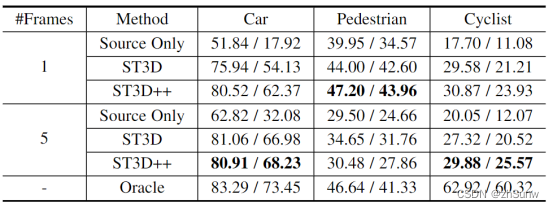
消融实验:
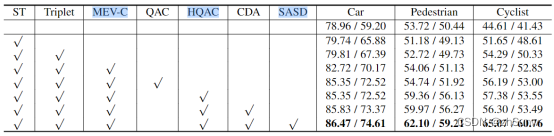
可以看到MEV、HQAC、SASD三个模块的提升较大















 1427
1427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









