









ST3D: Self-training for Unsupervised Domain Adaptation on 3D Object Detection
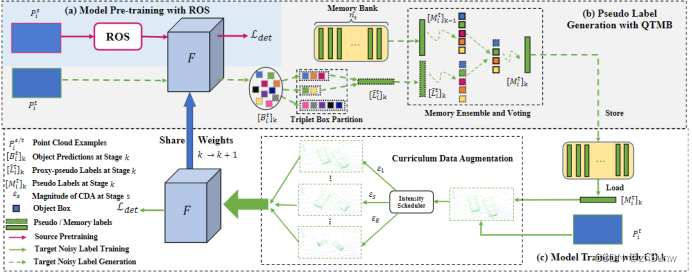
Algorithm
算法:
输入:源域的点云Ps和标签Ls,目标域的点云Pt
输出:目标域的三维目标检测模型。
1.使用ROS在{Ps,Ls}上预训练目标检测器
2.利用当前模型为每个目标域样本Pti生成预测框[Bti]k(k为生成的次数)
3.在给定[Bti]k的情况下,使用Triplet Box Partition生成伪标签[Lti]k
4.通过memory ensemble-and-voting (MEV)使用[Lti]k更新[Mi]k-1(第i个目标域样本的label memory bank,初始状态为空),维护[Mi]k的状态
5.在{Pti,[Mi]}上使用CDA训练模型。
6.回到步骤2直到模型收敛。
Main Method
ROS
问题:目标大小的偏差对 3D 目标检测有直接的负面影响,导致伪标记目标域边界框的大小不正确。
将Box内的点都转换到以目标的中心为原点,长宽高为x,y,z轴的坐标系下:
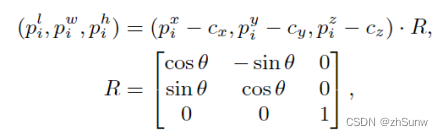
转换后的坐标分别乘上缩放因子,并逆操作还原到原坐标系下: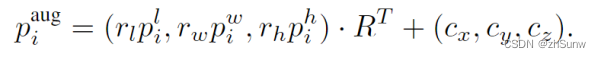
有效地模拟了具有不同大小的目标以解决大小偏差,有助于训练大小鲁棒的检测器。
Triplet Box Partition
除了Bounding Box本身的属性外,每一个伪标签还具有(u, state, cnt)三个属性,分别代表IoU预测值、状态,未匹配计数值。
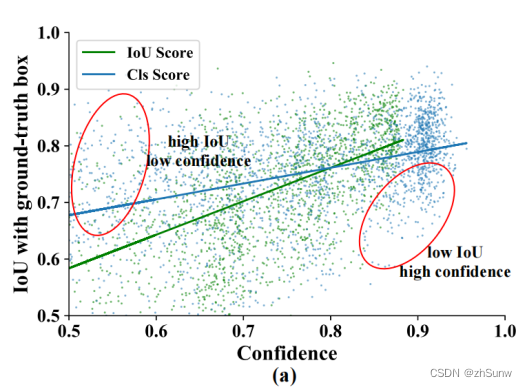
为什么要额外添加一个IoU回归头来进行预测,而不直接使用Confidence:
这两个值并不完全相同,更需要IoU值作为伪标签的一个评估手段。
对于每一个伪标签,根据u的大小将状态置为Positive、Ignored和Discard:
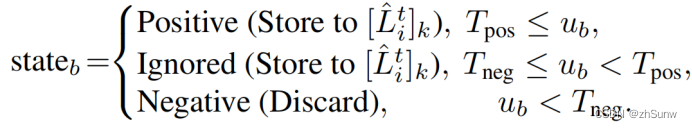
前两者将存入到L中,第三者直接丢弃。
(Ignored的伪标签巨有高度不确定性,所以仅暂存到[Lti]k等待被高度匹配时修改state唤醒)
Memory Ensemble-and-Voting (MEV)
使用[Lti]k更新上一个状态的Memory bank [Mi]k-1:对每一个[Mi]k-1内box,在[Lti]k内找IoU最大的进行匹配,若最大的IoU仍然<0.1则将这一对Box的未匹配计数值+1。否则:
将u大的更新为新的伪标签:
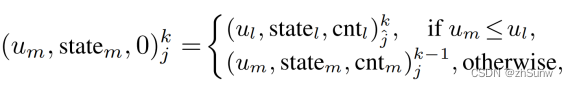
最后将所有未匹配计数值<阈值的伪标签存入Memory bank,完成更新得到[Mi]k
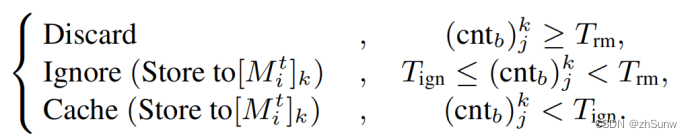
CDA
问题:模型容易过度拟合这些具有高IoU的简单目标,无法进一步挖掘困难目标以改进检测器。强数据增强是生成多样化和潜在困难示例的方法。但是对初始阶段的模型训练有害。
方法:逐步增加数据增强的强度,并逐渐生成越来越难的目标,以促进模型的改进并确保早期阶段的有效学习。
确定增强因子,每过一个阶段(若干个epoch)进行一次数据增强的强度增加:
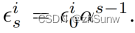
s为阶段数。
增强的随机采样值范围随着强度增加而变大:
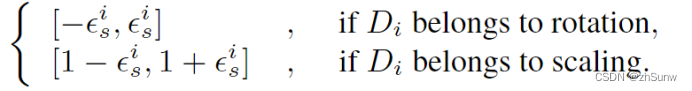
Experiments
closed gap表示域适应模型的提升比例
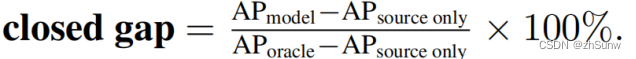
(w/SN)表示为使用了弱监督方法SN
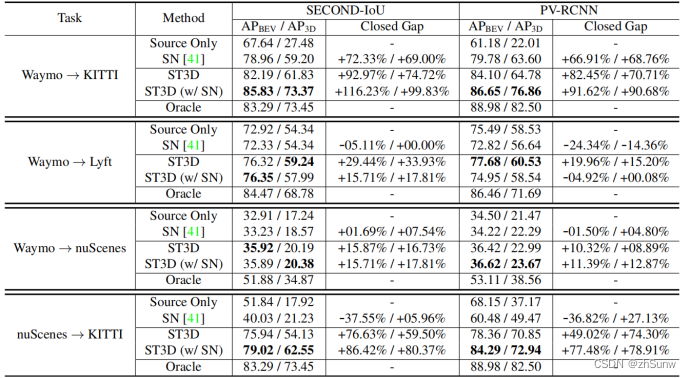
性能相较于Source Only的模型在目标域上都有了不小的提升,并且在弱监督的设置中ST3D(w/SN)甚至超过了有直接在目标域上训练的模型精度。
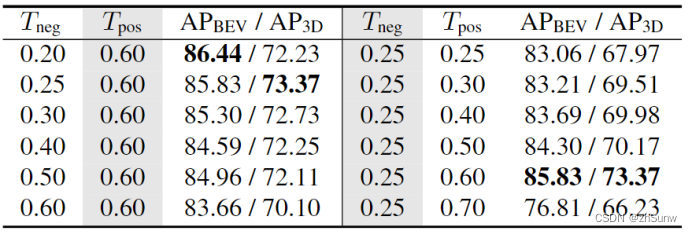
IoU阈值超参数设置的实验:

















 2368
2368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









