







对比与Python多线程无法操作多核,Java的多线程只会一味的占用所有核数计算。C/C++在Visual Studio 2005推出OpenMP的支持的,更能够精准地控制用多少核数去运算,而且写法简单,做到真正地多核多线程编程。比起Python、Java多线程无法实质上提升程序速度,C/C++的OpenMP是从CPU核数入手,提升程序速度。众所周知,现在双核、i3、i5、i7都是多个cpu并行的,我们写出来的程序,如果不进行设置,是无法利用到所有cpu,而且仅用单核计算,对于四核cpu的计算机,其余的核就是在闲置,更不要说高性能的计算机了。利用OpenMP能够很高的解决这点。
一、在Visual Studio 2005以上的版本开启OpenMP
以vs2010为例,新建一个C/C++项目之后(其它语言的项目是没有的),在源文件中新建一个cpp文件之后如下图,对项目点击属性,然后在属性页上左侧选择“配置属性”->“C/C++”->“语言”,然后在右侧“OpenMP支持”后选择“是(/openmp)”,如下图所示:
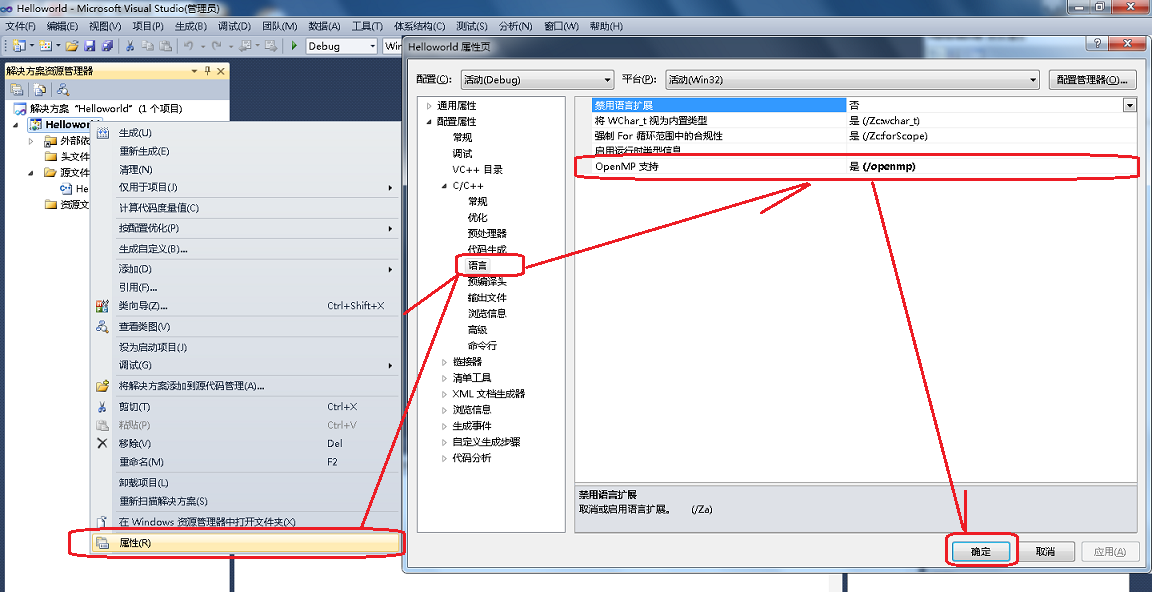
值得注意的是,如果你新建项目之后,没有在源文件添加一个cpp文件,是没有C/C++配置的。
二、OpenMP的Helloworld
这样就可以在你的项目使用OpenMP了。只要在你想要多核计算的地方,补上# pragma omp parallel num_threads(参与计算的CPU核数),则可以利用OpenMP,榨取相应核数的CPU来进行运算。注意,#与pragma之间是否有空格,关系不大,同时变量声明之前不能用这句,不然不能过编译。如果是在for之前,请写成:# pragma omp parallel for num_threads(参与计算的CPU核数)。比如如下的程序:
#include <omp.h>
#include <iostream>
#include <time.h>
using namespace std;
void hello(int i){
if(i==0){
# pragma omp parallel num_threads(2)
cout<<"HELLO!";
}
else{
# pragma omp parallel num_threads(4)
cout<<"hello!";
}
cout<<endl<<"finish!"<<endl;
}
int main(){
hello(0);
hello(1);
return 0;
}运行结果如下:
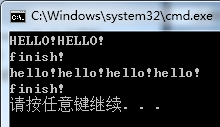
根据得到的参数不同,hello函数进入不同的循环。# pragma omp parallel num_threads(参与计算的CPU核数)影响的范围也仅仅限于其出现至结构体结束为止,也就是到第一个右大括号}。当参与计算的CPU核数为2与4的时候,分别进行了2次与4次输出。每一个cpu都要完成cout<<"hello"这条语句。然而finish!的输出仅有一个cpu参与,因此每个hello执行仅有一条。
你完全可以用多线程的理念去理解这个东西,但是它不同多线程仅仅是同资源下的分时片操作,OpenMP是真正的cpu参与计算。
这里需要注意,如果你的电脑的CPU仅有2核,那参与计算的CPU核数仅能为1、2,不能超过CPU的核数。
三、OpenMP的意义何在?
上述例子可能有人说根本就没有任何意义,完全可以用一个for循环搞完的事情,非要扯上OpenMP干嘛?
那么下面我们做一个0到2,000,000,000(40亿)的自增运算来说明这个问题,且记录运行时间。
#include <iostream>
#include <time.h>
using namespace std;
int main(){
clock_t t_start=clock();
for(int i=0;i<2000000000;i++){
}
time_t t_end = clock();
cout<<"Run time: "<<(double)(t_end - t_start) / CLOCKS_PER_SEC<<"S"<<endl;
return 0;
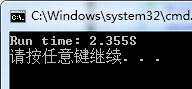
}如果不用OpenMP的话,在我的计算机上,上述的程序运行时间如下:
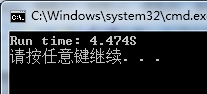
运行期间的CPU占用率如下:
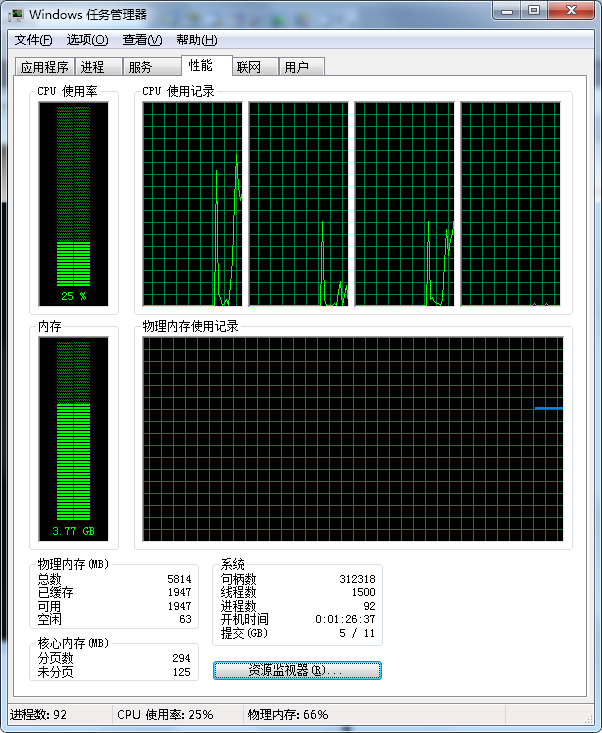
可以看到四核CPU仅有1个CPU被占用,引用使用率为25%!
如果使用OpenMP,要求参与运算的cpu核数为2的话:
#include <omp.h>
#include <iostream>
#include <time.h>
using namespace std;
int main(){
clock_t t_start=clock();
# pragma omp parallel for num_threads(2)
for(int i=0;i<2000000000;i++){
}
time_t t_end = clock();
cout<<"Run time: "<<(double)(t_end - t_start) / CLOCKS_PER_SEC<<"S"<<endl;
return 0;
}
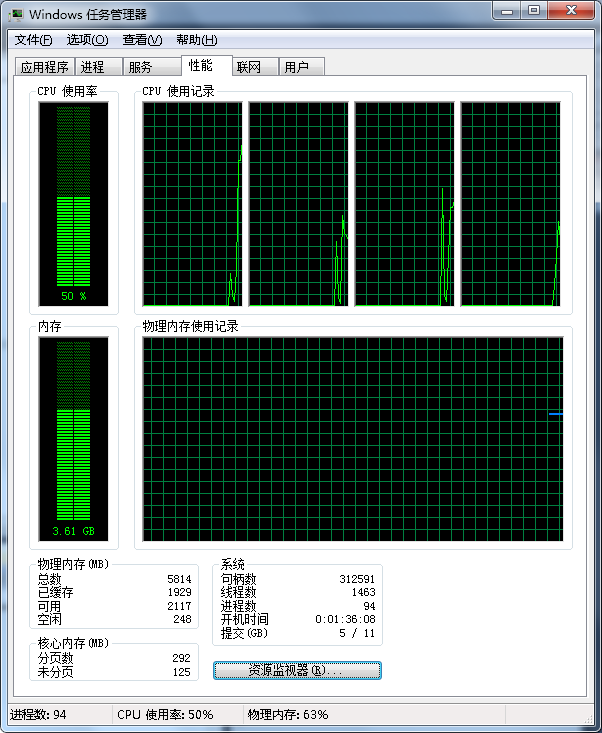
运行期间的四核CPU占用率也去到了50%:
那么如果设置用尽四个核的CPU运行呢?
#include <omp.h>
#include <iostream>
#include <time.h>
using namespace std;
int main(){
clock_t t_start=clock();
# pragma omp parallel for num_threads(4)
for(int i=0;i<2000000000;i++){
}
time_t t_end = clock();
cout<<"Run time: "<<(double)(t_end - t_start) / CLOCKS_PER_SEC<<"S"<<endl;
return 0;
}
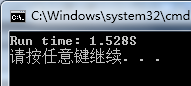
CPU占用率:
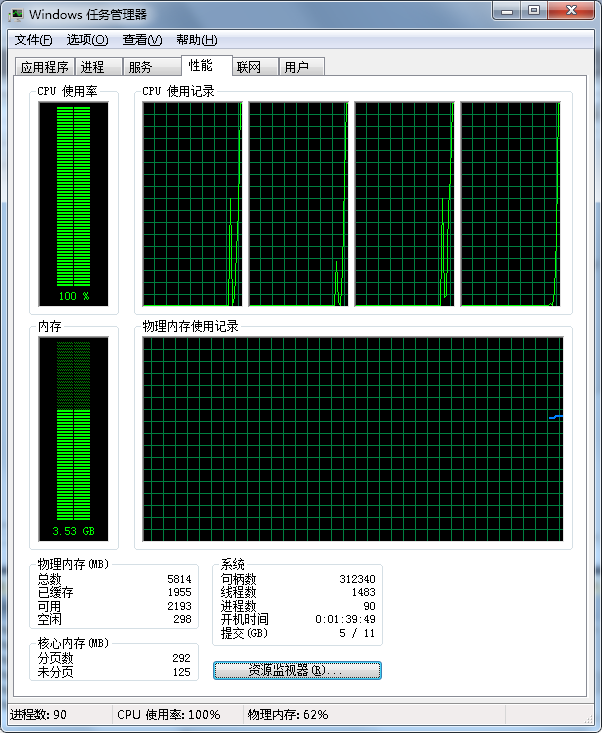
因此,可以看到,如果你的程序要进行一个大规模的运算,使用OpenMP能够彻底地用尽CPU资源计算,提升你的程序运行速度!















 3598
3598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









