









24年4月上海交大、UCSD、杜克大学和Adobe的论文“Beyond Chain-of-Thought: A Survey of Chain-of-X Paradigms for LLMs”。
思维链 (CoT) 是一种被广泛采用的提示方法,它激发了大语言模型 (LLM) 的推理能力。受 CoT 顺序思维结构的启发,人们开发了许多 X-链 (CoX) 方法来解决涉及 LLM 不同领域和任务的各种挑战。对不同环境下 LLM 的 X-链方法进行了全面概述。具体来说,根据节点(即 CoX 中的 X)和应用任务对它们进行分类。还讨论现有 CoX 方法的发现和含义,以及潜在的未来方向。
CoT的本质是将复杂问题分解为一系列中间子任务。通过逐步处理这些子任务,LLMs能够关注重要的细节和假设,这大大提高了它们在广泛推理任务中的表现。此外,CoT的中间步骤提供了一个更透明的推理过程,便于对LLMs的解释和评估。
随着CoT的成功,开发了许多X链(CoX)方法。这些方法不仅限于推理思维,最近的CoX方法还构建了包含各种组件的链,如反馈链、指令链、历史链等。这些方法已被应用于解决涉及LLMs的多样化任务中的挑战,包括多模态交互、幻觉减少、基于LLM的智体规划等。
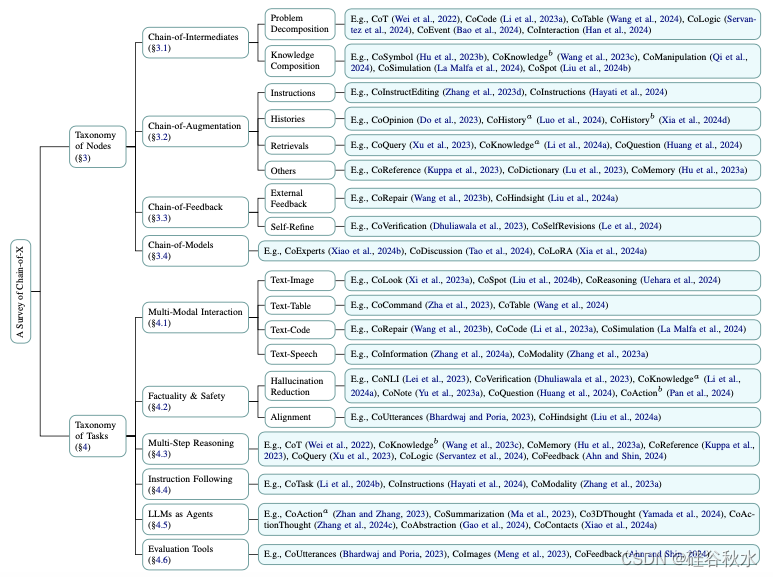
如图是按节点和任务分类对 Chain-of-X 进行综述的框架(仅列出代表性方法)。
思维链(CoT)提示是一种方法论,能显著增强大语言模型(LLMs)的推理能力。CoT由Wei(2022)引入,涉及以结构化的格式<input, thoughts, output>提示LLMs,其中“thoughts”包括通向最终答案的连贯中间自然语言推理步骤。CoT在需要复杂推理的任务中效果最为显著。传统的少样本学习方法在这类场景中经常会失败,因为它们倾向于直接提供答案而不包括必要的中间步骤。Rae(2021)强调了这一局限性,指出这些方法随模型大小增加而显得不足。相比之下,CoT提示通过融入中间推理步骤而表现出色。这些步骤通过逻辑推进引导模型,增强其解决算术、常识和符号推理等复杂问题的能力(Wang,2023d;Lyu,2023)。CoT的本质在于,将复杂问题分解为可管理的中间步骤来解决问题(Zhou,2023)。Kojima(2022)也展示了通过提示“一步步思考”的零样本CoT的强大性能。明确的推理步骤还为模型的思考过程提供了一个透明的路径,允许进一步的评估和纠正(Yu,2023b)。
CoX定义为CoT方法的一种广义形式,用于超越LLM推理的多样化任务。CoX中的X称为链结构的“节点”。除了CoT提示中的思考外,CoX中的X可以采取针对特定任务定制的各种形式,包括中间、增强、反馈甚至模型。
如图是四种类型节点的 Chain-of-X 范式说明:(a)CoT 中间,例如思维,(b)CoA增强,(c)CoF 反馈,以及(d)CoM 模型。
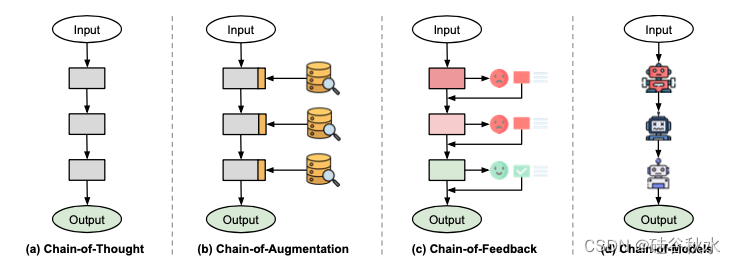
CoX的想法是构建一个与问题相关的组件序列,这些组件要么组合贡献解决方案,要么迭代精炼复杂任务的输出。同样,CoX定义一个结构化格式<input, X1, …, Xn, output>,其中n是链的长度。这种格式超越像CoT这样的提示策略,可以适应多种算法框架或结构,用于涉及LLMs的多样化任务。例如,验证链(Chain-of-Verification,Dhuliawala,2023)是一个幻觉减少框架,使用LLM生成初始响应,构建一系列验证问题,并根据这些问题修订其先前的响应。除了减少幻觉外,CoX方法还被应用于多种任务,包括多模态交互、事实性与安全、多步推理、指令跟随、LLMs作为智体和评估工具等。一个更详细的CoX分类框架如下:
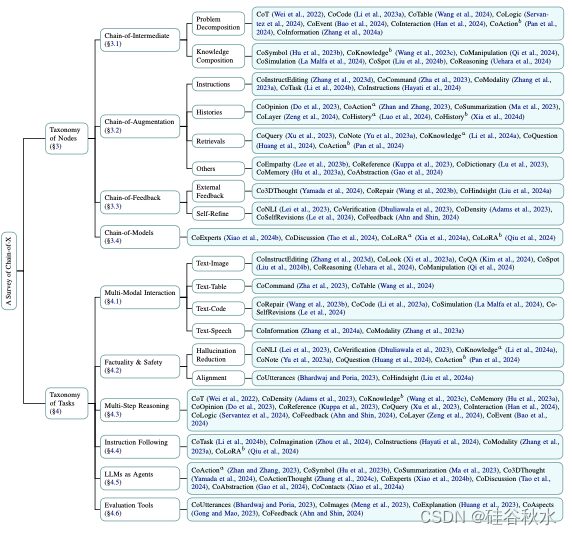
先说CoX的节点不同。
基于使用明确中间步的概念,CoT 的自然演变涉及用其他类型的中间组件(即中间链)替换推理思维。根据主要关注点,进一步将其划分为多个子类型,基于问题分解和知识组合形式。
CoX 方法的一个流行变体是增强链,其中链通过附加知识进行增强。根据增强数据的类型,分类如下:指令链、检索链和历史链等。
反馈链是 CoX 的另一种变体。与通常优于生成的增强不同,反馈贯穿整个生成过程,以增强和微调响应。根据反馈源,将其分为外部反馈和自我完善反馈。
以前的 CoX 方法大多是为单个 LLM 设计的。认识到不同的 LLM 可能具有不同的专业(Xiao,2024b;Xia,2024b),另一项工作提出构建一个模型链,以利用每个模型的不同优势。
再说CoX的任务不同。
尽管 CoT 最初是为文本生成而提出的,但已经开发了各种 CoX 方法来应对多模态性的挑战。包括文本-图像,文本-表格,文本-语音。
确保 LLM 输出中的事实一致性和安全性至关重要(Wang,2023e;Zhang,2023c;Dong,2024)。为了使 LLM 生成更符合事实和更安全的输出,最近的研究探索 CoX 方法在幻觉减少和对齐方面的应用。
推理是一个被广泛研究的课题,尤其是需要对上下文和逻辑有扎实理解的多步推理任务(Wei,2022)。CoX 方法的顺序性使其非常适合这项任务。例如,知识链(Wang,2023c)在每一步都引出显性知识证据,从而提高 LLM 在各种推理任务中的表现。同时,反馈链(Ahn & Shin,2024)将最初不正确的推理步骤分解为更小的单个任务,进行更扎实的推理,从而对其进行修改。
指令跟随是 LLM 的一项著名能力,它使人类能够为各种任务提供明确的指导(Zhang,2023b)。CoX 方法的发展也导致了各种增强此功能的方法。例如,任务链(Li,2024b)提供了一种结构化方法,其中每条指令都由中间原子任务组成,这些任务经过专门策划,微调电子商务 LLM 的响应,以更好地满足客户需求。
凭借强大的规划能力,LLM 已被用作各种任务中的智体(Xi,2023b)。人们已经探索了 CoX 方法,以进一步提高基于 LLM 智体的规划能力。在这方面,Chain-of-Action(Zhan & Zhang,2023)和 Chain-of-ActionThought(Zhang,2024c)利用一系列规划的行动来指导智体决策,确保每一步都受到前一步的影响。
随着 LLM 变得越来越复杂,评估 LLM 变得越来越具有挑战性(Chang,2023 年),这使得 CoX 方法成为评估目的的宝贵资产。话语链提示(Bhardwaj & Poria,2023)是 CoX 方法如何阐明特定关注领域的一个典型例子,例如 LLM 与潜在有害模型交互场景中的安全问题。这种方法揭示了可能导致 LLM 越狱的脆弱对话,为 LLM 安全性的稳健性提供了必要的见解。此外,反馈链 (Ahn & Shin, 2024) 方法也证明了提示对 LLM 性能的影响。通过反复向 LLM 提供“再试一次”等非信息性提示,研究人员发现答案的质量逐渐改善。
今后的方向:
- 中间链的因果分析
- 降低推理成本
- 知识蒸馏
- 端到端微调


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









