









23年6月乔治亚理工的论文“ToolQA: A Dataset for LLM Question Answering with External Tools”。
语言大模型(LLM)在各种 NLP 任务中表现出了令人印象深刻的性能,但它们仍然面临着幻觉和弱数字推理等挑战。 为了克服这些挑战,可以使用外部工具来增强LLM的问答能力。 然而,目前的评估方法并没有区分可以使用LLM内部知识回答的问题和需要通过工具使用外部信息回答的问题。 为了解决这个问题,引入一个名为 ToolQA 的新数据集,该数据集旨在忠实评估LLM使用外部工具回答问题的能力。 ToolQA 涉及一个可扩展的自动化数据集管理流程,以及 13 个专门为与外部知识交互以回答问题而设计的专用工具。 重要的是,尽量减少基准数据与LLM预训练数据之间的重叠,从而能够更精确地评估LLM的工具使用推理能力。 该数据和代码可在 GitHub 上免费使用:
github.com/night-chen/ToolQA
一项研究集中在检索增强语言模型 [50, 2, 15, 24, 27, 70, 30, 63],其中使用稀疏 [46] 或密集检索 [20, 14] 来提取相关知识 来自语料库。 这些工作主要集中在利用自由文本,而不考虑多种类型的任务解决工具。 另一方面,Program-of-Thought [5]、PAL [11]、MathPrompt [13] 和 Code4Struct [55] 应用基于代码的工具来增强LLM回答问题的能力,重点是表格和数学。 其他几项工作[48,28,49]通过结合不同类型的基本工具(例如计算器、日历、机器翻译)来解决复杂的推理任务,从而扩大了工具的使用范围。 ART [39]、ReAct [66] 和 Reflexion [51] 利用语言大模型(LLM)自动生成中间推理步骤和动作,从而提高各种决策任务中的可解释性和解决问题的能力。 此外,一些方法已将这种学习范式扩展到其他模式 [64, 61] 和其他领域 [18]。
通过使用外部工具增强LLM来缓解幻觉和数字推理弱等问题,像检索增强 [50, 15]、数学工具 [48, 66, 28] 和代码解释器 [11, 55]。 例如,Wolfram 数学插件可以增强数字推理 [60],而经过验证的数据库可以通过提供最新的事实检查知识来减轻幻觉 [42]。 然而,现有的评估方法很难区分模型是简单地回忆预训练的信息还是真正利用外部工具来解决问题[32]。 出现这一挑战的部分原因是,用于评估的外部数据可能已经在预训练阶段提供给LLM[45]。 这种暴露可能会导致对LLM工具使用能力的有偏见评估,因为这些模型只能使用他们根深蒂固的知识和推理能力,绕过了对外部工具的使用。 因此,这些评估无法准确反映模型的真实能力。 需要一种公平而明确的方法来检查LLM是否真的擅长使用工具解决问题,或者他们是否只是使用他们记住的信息。
如图所示,LLM经过大量语料库的预训练,拥有广泛的知识,这些知识可能与评估数据重叠。 这种重叠对当前的评估方法提出了重大挑战,因为很难辨别模型是否只是回忆预训练的信息或真正采用外部工具来解决问题。
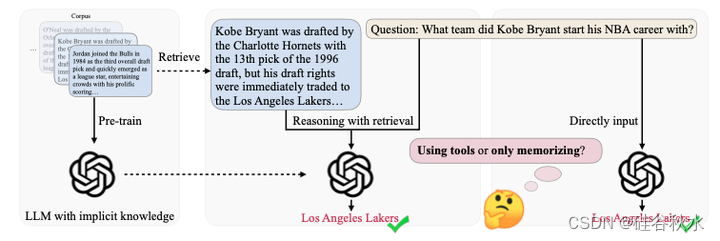
如图是ToolQA数据集的概览图。其旨在忠实评估LLM使用外部工具的能力,通过三个阶段整理数据:(a) 参考数据收集; (b) 人工引导问题生成; © 程序化答案生成。
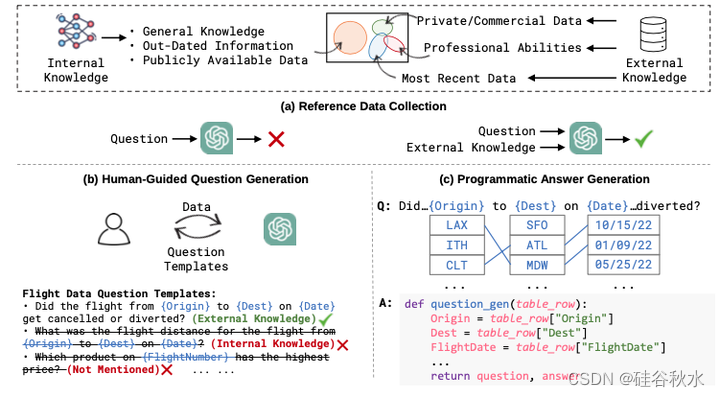
ToolQA 由来自 8 个不同领域的数据组成,每个实例都是一个元组(问题、答案、参考语料库和工具)。 参考语料库是可以查询的外部知识源,可以是文本语料库、表格数据库或图表。 为了能够从参考语料库中获取信息,开发了 13 种工具,用于文本检索、数据库操作、代码解释、数学计算等。 这些问题旨在模拟现实世界的信息寻找的查询。 然而,这些问题不能直接用LLM的内部知识来回答,而是需要LLM通过工具从参考语料库中获取信息。 ToolQA的详细统计数据如表所示。
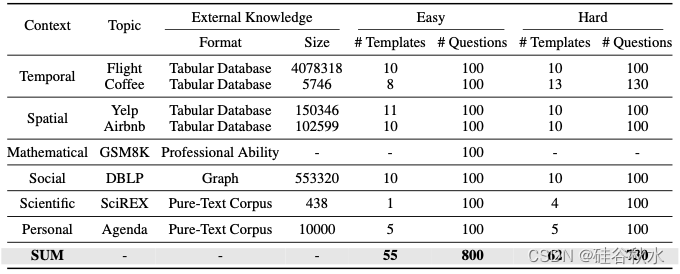
本文定义了 6 个上下文维度:时间、空间、社会、科学、数学和个人。 收集参考语料库,可以根据 6 个维度的一个或多个产生特定于上下文的问题。 具体来说: 1)沿时间维度,收集 Flights 和 Coffee 语料库,其中包含超出 LLM 预训练数据时间范围的最新信息。 2)沿空间维度,收集Yelp 和 Airbnb,这是两个可以产生具有空间上下文问题的非文本语料库。 3)沿数学维度,收集GSM8K中ChatGPT凭借自身数学推理能力无法正确回答的问题; 4)SciREX强调科学领域的详细模型性能[16],其中GPT模型很容易产生幻觉[36]。 5)为了合并个人数据并避免隐私问题,用虚拟姓名和事件与 ChatGPT 合成个人Agenda语料库。 6)此外,还从最新的DBLP数据库中选择数据,并在作者和论文之间创建图表,这是目前LLM无法理解的社会关系知识。
ToolQA定义了13个工具,如表所示:文本2个,数据库3个,图4个,代码2个,数学和系统各一个。

本文提出一种人工指导的 LLM 生成方法,该方法使用问题模板来连接人工指导和自动 LLM 生成 [59, 69]。 首先要求 ChatGPT 根据参考数据生成候选问题模板,使用诸如“根据给定信息生成一些模板问题并提供相应答案”等提示。 获得的响应是包含潜问题模板的数组。 然后,进行人工验证,选择无法用LLM内部知识回答但可以用参考语料库回答的模板。
之后从参考数据中采样值,自动填充到模板中以生成具体的问题。 根据问题的难度,分为两类——简单和困难。 简单的问题主要侧重于从外部知识中提取单个信息,因此需要更少的工具来参与解决方案。 相反,困难的问题需要对从参考语料库中提取的多个信息片段进行复杂的运算(例如平均)和推理(例如比较),需要更多的工具和复杂的推理。
最后一步是为生成的问题创建准确的答案。 为了保证这些响应的有效性,要实现的是:1)运算符,它们是与预定义工具相对应的函数; 2)工具链,是针对不同问题模板组成不同运算符的模式。 对于每个问题,填充到问题模板中的真实参数,可以使用相应的参数运行工具链,以编程方式从参考数据中提取答案。 此过程可以自动生成问题的正确答案,即使对于涉及多步推理的问题也是如此。 当用采样值回答生成的问题时,编写 Python 代码来实现对参考数据的操作,包括数据库加载、数据过滤和 get-value函数。 然后,编程流水线运行这些运算符的工具链,自动生成正确的答案。















 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









