









23年5月清华、腾讯和香港中文大学的论文“GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction”。
本文旨在有效地使语言大模型(LLM)能够使用多模态工具。 高级专有LLMs(例如 ChatGPT 和 GPT-4)通过复杂的提示工程显示出工具使用的巨大潜力。 然而,这些模型通常依赖于高昂的计算成本和不可公开访问的数据。 为了应对这些挑战,提出基于自我指导的GPT4Tools,使LLaMA和OPT等开源LLM能够使用工具。 它通过给高级教师提示各种多模态上下文来生成遵循指令的数据集。 通过使用低秩适应(LoRA)优化,该方法有助于开源LLM解决一系列视觉问题,包括视觉理解和图像生成。 此外,还提供了一个基准来评估LLM使用工具的能力,该基准以零样本和微调的方式进行。 大量的实验证明GPT4Tools在各种语言模型的有效性,不仅显着提高了调用见过的工具的准确性,而且还实现了未见过工具的零样本能力。 代码和演示可如下获取
https://github.com/StevenGrove/GPT4Tools
在自然语言处理(NLP)社区中,一些方法[7-11]试图赋予语言模型使用工具的能力。 例如,Komeili [7]建议根据搜索引擎的结果生成对话响应。 LaMDA [9] 创建了一套工具(包括信息检索系统、计算器和翻译器)来避免看似合理的输出。 Lazaridouetal.[10]在 Gopher-280B[14] 上采用少样本提示,使搜索引擎能够根据事实和当前信息来输出结果。 同样,Visual ChatGPT [5] 和 MMREACT [6] 提示 ChatGPT 调用视觉基础模型。 此外,ToolFormer [11] 使用自我指导和自举来教GPT-J (6B) [15]使用五种工具,其中包括问答系统、计算器、搜索引擎、机器翻译系统和 日历。 相反,专注于使用 GPT-3.5 模型作为强大的老师来蒸馏现成的语言模型,并使它们能够访问许多视觉模型。如表是GPT4Tools与以前方法的比较:
如图是GPT4Tools的流程图:给 ChatGPT 提示图像内容和工具的定义,获得与工具相关的指令数据集。 随后,采用 LoRA [38] 在收集的指令数据集上训练开源LLM,从而使LLM能够使用工具。
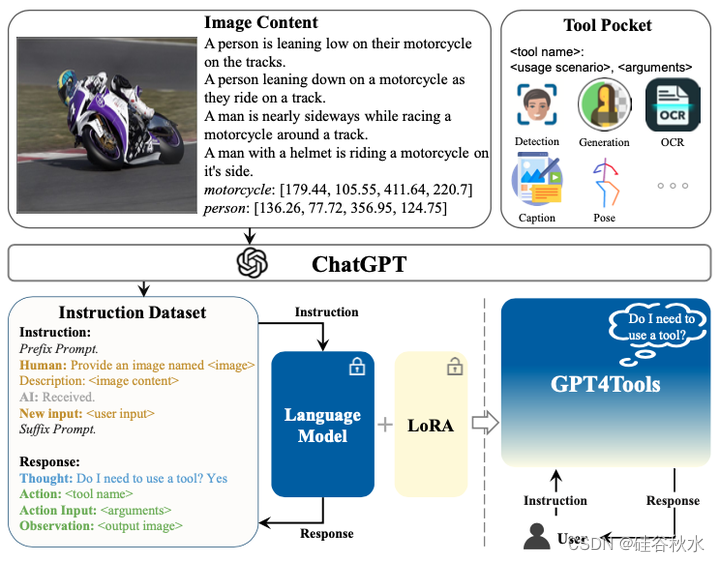
生成工具相关指令数据集的过程:给定图像,根据字幕和边框构造图像内容 XC,这是在图像和语言模型之间建立连接的直接方法[16, 17]。 以XC为条件,为ChatGPT [3] (MT)提供一个工具相关的提示Pt,从而获得大量的指令跟踪数据Y。

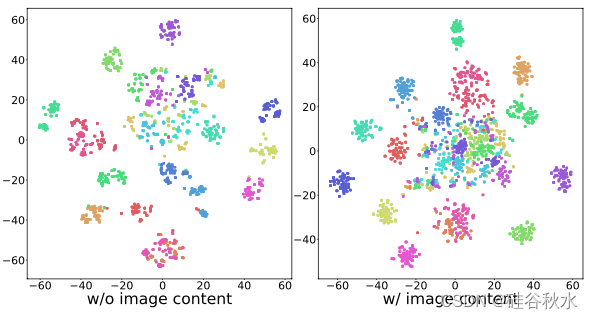
提示Pt 包括系统消息、工具的定义(:、)以及鼓励 ChaptGPT(MT)生成可视化指令和期望输出的后缀提示。 Y 是 MT 的结果,由 N 个指令输出对 {y1, y2, …, yN } 组成,其中 yi 的格式为“,,”,N 为 已定义工具的数量。 由于 MT 的每个输入都落地到图像内容 XC ,因此生成的指令本质上与图像相关,从而避免了随意生成。 此外,图像的丰富可变性导致,指令与想象的相比具有更高的多样性。 为了提供对比,收集没有图像内容的指令后续数据 XC ,这与 ToolFormer [11] 类似。
如图所示,在没有 XC 的情况下,生成的指令之间观察到的高度相似性凸显了它们的单调性和缺乏多样性。 相反,由于图像内容的变化,使用图像条件提示生成的指令信息更加丰富且多样化。
根据收集的原始数据集(70K条),应用过滤过程来删除类似的指令,从而保留 41K 条。 随后,利用标准化模板将保留的数据转换为指令响应格式。此过程会生成一个新的数据集,表示为 YS+。 YS+的指令组件包含系统消息和工具定义的前缀提示(prefix prompt)、表示图像内容、替换为生成的视觉指令、以及旨在提示语言模型的后缀提示(suffix prompt),通过给定的工具回复用户输入。 YS+ 的响应组件包括调用工具的Thought和一系列动作。 每个动作都涉及一个Action和Action Input,分别由 和 后接。 Observation反映了调用工具的结果。 如图(a) 显示了 YS+ 的示例。
不过这种简单的格式在指令和响应方面都缺乏复杂性和深度。 为了缓解这个问题,从两个角度增强生成的数据:
负样本。 生成的指令主要关注工具的使用,即Thought之后的决定始终是“Yes”。 因此,微调模型存在过拟合此类决策的潜在风险。 当用户指令与工具使用不相关时,微调模型可能会通过调用不必要的工具来错误地执行不相关的动作。 为了缓解这个问题,从现有数据集 [40] 中选择对话数据并将其转换为所需的模板来合成负样本 YS−,如图 (b) 所示。 通过使用 YS+ ∪ YS− 调整模型,它可以决定何时使用工具。
上下文样本。 生成的指令采用标准且固定的single-tune格式,缺乏上下文结构。 因此,切断动作链来增强数据集,如图 © 所示。 此外,从 YS+∪YS− 中随机选择多个指令,并将它们重新格式化为多轮对话数据。 通过这种方式,合成了上下文指令跟踪数据 YSc,这使微调的模型能够在给定上下文中调用工具。
至此,已经构建了工具相关的教学数据集,包括正样本、负样本和上下文样本:YS = YS+ ∪ YS- ∪ YSc 。

基于 YS,用其原始的自回归训练目标来调整现有(off-the-self)语言模型。 为了微调可行,利用 LoRA [38] 优化,它冻结语言模型并优化 Transformer 层的秩分解组件。 对于具有 L 个tokens的序列,通过以下方式计算目标响应 Xr 的概率:

其中 Xinst 表示指令tokens; θ 是可训练参数。 在实际应用中,也会涉及前缀提示(prefix prompt)和后缀提示(suffix prompt)。
许多基准[42,43,8]通常利用人工标注的数据集来评估模型的性能。 为了测量语言模型的工具使用能力,同样构建了一个评估数据集,并人工验证每条的准确性。 该评估数据集分为两个部分:第一部分(验证集)与训练集具有相同的成分,包含 23 个工具; 第二部分(测试集)包含训练集中没有的 8 个新工具。 将使用验证集来验证模型在训练集上微调后是否能够正确遵循用户命令。 测试集将用于验证模型在微调后是否可以推广到新工具。 基于包含N条指令的人工标注评估数据集,设计一个从三个方面衡量模型性能的成功率:思维成功率、动作成功率和参数成功率。
最后,成功率等于
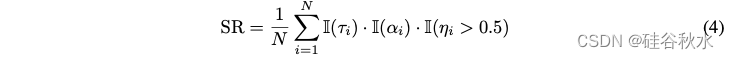
其中参数成功率
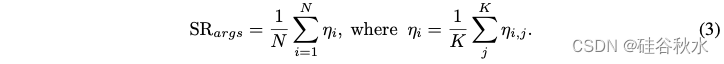
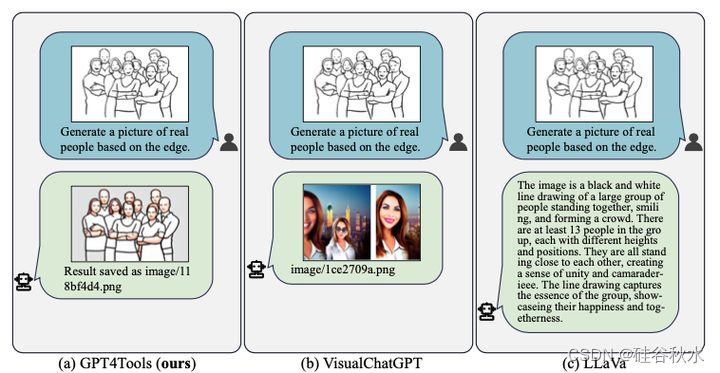
还有,GPT4Tools 和 Visual ChatGPT [5] 和 LLaVa [36]的比较图:
以及Vicuna-13B [12] 在GPT4Tools 上微调的调用工具案例
















 3813
3813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









