







让GPT使用工具:NIPS最新论文《GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction》解读
本文是关于NIPS最新论文《GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction》的技术介绍。ChatGPT或者GPT4已经展现出巨大的潜力,但是存在高昂的计算成本以及无法处理的数据类型。GPT4Tools通过自我提示(self-instruction)实现大语言模型与现有工具(例如人脸检测、文字识别)的结合。此外,这篇文章还提出一套评价大语言模型使用工具的能力的基准。
本文写于2024年4月11日。
有关本专栏的更多内容,请参考大语言模型文献调研专栏目录
文章目录
1. 论文基本信息
1. 论文资源
论文题目:GPT4Tools: Teaching LLM to Use Tools via Self-instruction
代码链接:https://github.com/AILab-CVC/GPT4Tools
论文引用:
@misc{gpt4tools,
title = {GPT4Tools: Teaching LLM to Use Tools via Self-instruction},
author={Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, Ying Shan},
journal={arXiv preprint arXiv:2305.18752},
year={2023}
}
2. motivation
最近的大型语言模型(LLMs)如GPT-3、InstructGPT和GPT3.5在零样本学习和逻辑推理领域展现出巨大潜力。这些模型通常是在互联网级大量文本数据上进行训练。但是训练这些模型需要极高的计算成本(烧显卡),这限制他们在特定场景的应用。此外,这些模型通常依赖于特殊数据,如源代码和聊天记录,而这些数据难以获取。
近期研究尝试连接语言模型与多模态模型,如Visual ChatGPT和MMREACT通过复杂的提示工程来实现。他们利用预定义模板创建指令,以便视觉-语言基础模型执行。尽管取得了显著成果,但指令分解所需的GPT-3.5昂贵且不开源。赋予代理使用工具能力也需要大量数据。
作者重点研究这个问题:**如何让大语言模型能够高效地使用多模态工具?**作者提出的GPT4Tools,通过自我指导(self-instruct)从先进LLMs赋予开源LLMs使用工具的能力,有以下要点值得关注:
- 构建指令数据集: 使用先进教师模型(如GPT-3.5)生成的指令数据集,包含与视觉内容和工具描述相关的大量工具操作指令,利用视觉内容描述显著改善数据多样性。
- 采用LoRA进行微调: 利用生成的指令遵循数据集,采用低秩调整(LoRA)对Vicuna、LLaMa和OPT等原始语言模型进行微调。
- 扩展语言模型能力: 基于GPT4Tools的语言模型不仅具备固有语言能力,还可通过使用工具解决各种视觉问题,包括对象定位和分割、生成和指导图像以及视觉问答(VQA)等任务。
- 增强零样本容量: GPT4Tools方法不仅提高了LLMs调用已知工具的准确性,还能以零样本方式处理未知工具。
此外,作者提出了评测指标,用于评估LLMs在各种任务中利用工具的有效性。
2. 相关工作
2.1 视觉和语言模型
如何让语言更好的理解视觉?需要将图像转换为离散的文本表示,或将连续的图像特征投影到文本特征空间中:
- OFA设计了一个适用于语言和目标检测任务的统一序列解码架构。
- Pixel2Pixel将视觉理解任务的结果转换为一系列类似语言任务的离散标记。
- Gato将一系列视觉和控制任务聚集到一个序列预测问题中。
- UViM和Unified-IO主张通过学习的离散代码来统一各种视觉任务。
- GPT4Tools:为语言模型配备了各种专门的多模态工具,任务扩展性强且避免微调造成的灾难性遗忘。
2.2 指令微调
顾名思义,指令微调就是通过在特定的指令遵循数据上进行微调,预训练语言模型可以遵循自然语言指令并完成各种真实世界任务。
- 典型案例。InstructGPT, FLAN-T5, OPT-IML在使用指令数据进行微调后,在特定任务上表现出色。
- 自指导。Self-Instruction说明,语言模型的指令遵循能力可以通过启用其自动生成的指令数据来提升,并为提高语言模型的zero-shot和few-shot能力提供了可行手段。
- 用大模型制作指令数据集。通过使用强大的 GPT-3.5 或 GPT-4 的指令数据对现成语言模型进行提炼,可以改善它们的能力。这一方法激发了近期许多作品基于 LLaMA 构建优秀的语言模型,GPT4Tools也采用类似方法。
2.3 使用工具
让大模型使用工具也是令人关注的问题:
- Komeili等人 提出基于搜索引擎结果生成对话回复的方法。
- LaMDA等人 :开发了信息检索系统、计算器和翻译器等工具,以提高输出质量。
- Lazaridou等人 :使用少量样本提示Gopher-280B,使搜索引擎输出具有当前和事实信息。
- Visual ChatGPT和MMREACT: 利用视觉基础模型来提示ChatGPT。
- ToolFormer: 使用自我教导和自举技术来教授GPT-J (6B),使用了问题回答系统、计算器、搜索引擎、机器翻译系统和日历等工具。
- GPT4Tool: 利用GPT-3.5模型作为强大的教师模型,提炼现有语言模型,并使它们能够访问各种视觉模型。
3. GPT4Tool
3.1 制作数据集
第一,初步收集。
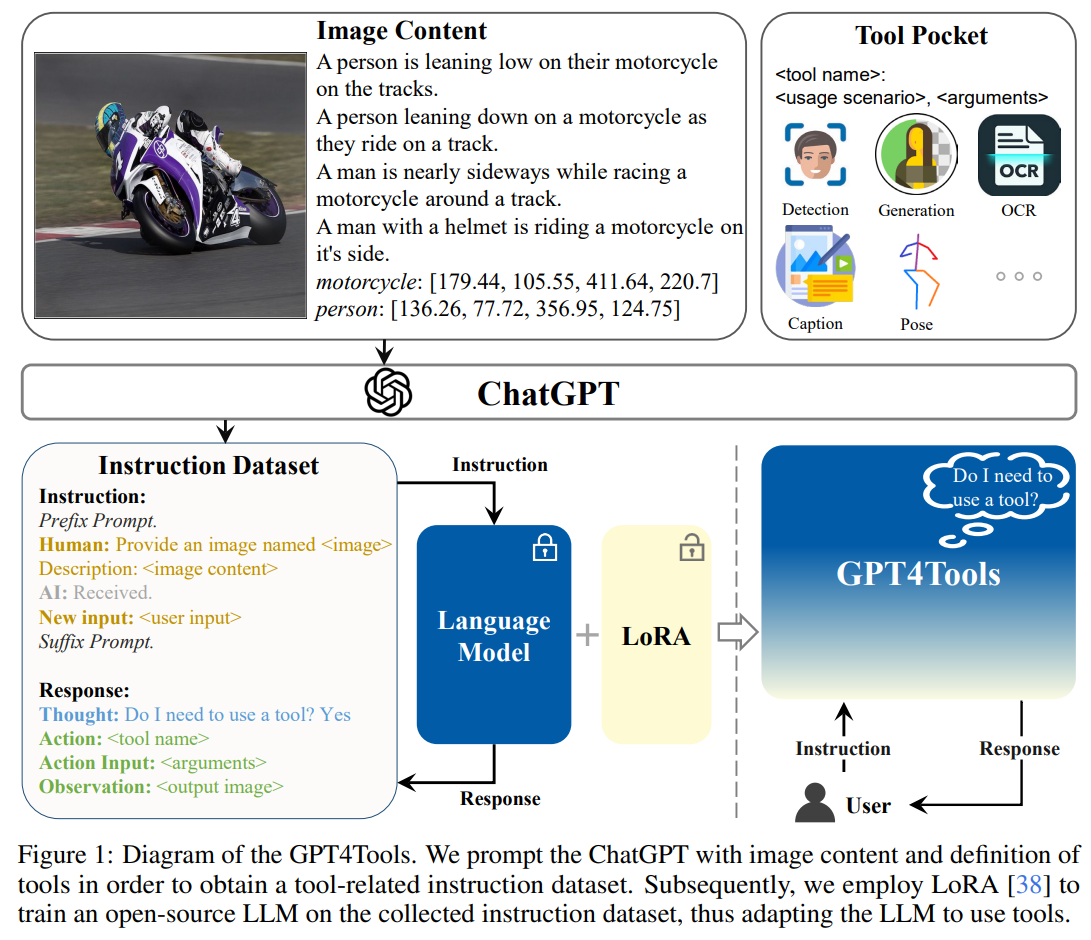
作者制作数据集的目的是微调大语言模型,使得大语言模型能够更好的使用工具,我们将要构建的数据集暂且称为工具指令数据集,有以下要点:
- 给定图片,根据图像描述和目标框构建图像内容Xc。
- 将Xc和工具相关提示词Pt(包含工具名,使用场景和工具参数)送到GPT3.5中,获取指令跟随数据(包含N个元组,每个元组中有指令、工具名和工具参数)。
- 每个生成的指令与图像相关,避免随意生成, 图像的丰富变化导致指令比想象中的情况更多样化。
- 加入图像描述后生成的指令信息更加丰富多样,且类内更聚集。

第二,数据形成过程。
针对以上收集的数据,需要做进一步处理,有以下要点:
- 原始数据集: 收集了70K条数据项。
- 过滤: 去除重复指令、格式错误的指令、使用了错误工具名称的调用以及格式错误的工具参数调用,保留了41K条数据项。
- 转换: 使用标准化模板将保留的数据转换为指令-响应格式。
生成的数据包含指令部分和响应部分,包含系统消息和工具定义的前缀提示,图像内容的表示被生成的视觉指令替换,以及一个后缀提示,用于提示语言模型输入用户输入。响应部分包括四个元素:
- 思考: 模型对工具使用的认知。
- 行动: 模型将使用的工具或将采取的行动。
- 行动输入: 所选工具的参数。
- 观察: 使用工具的结果。
第三,数据增强
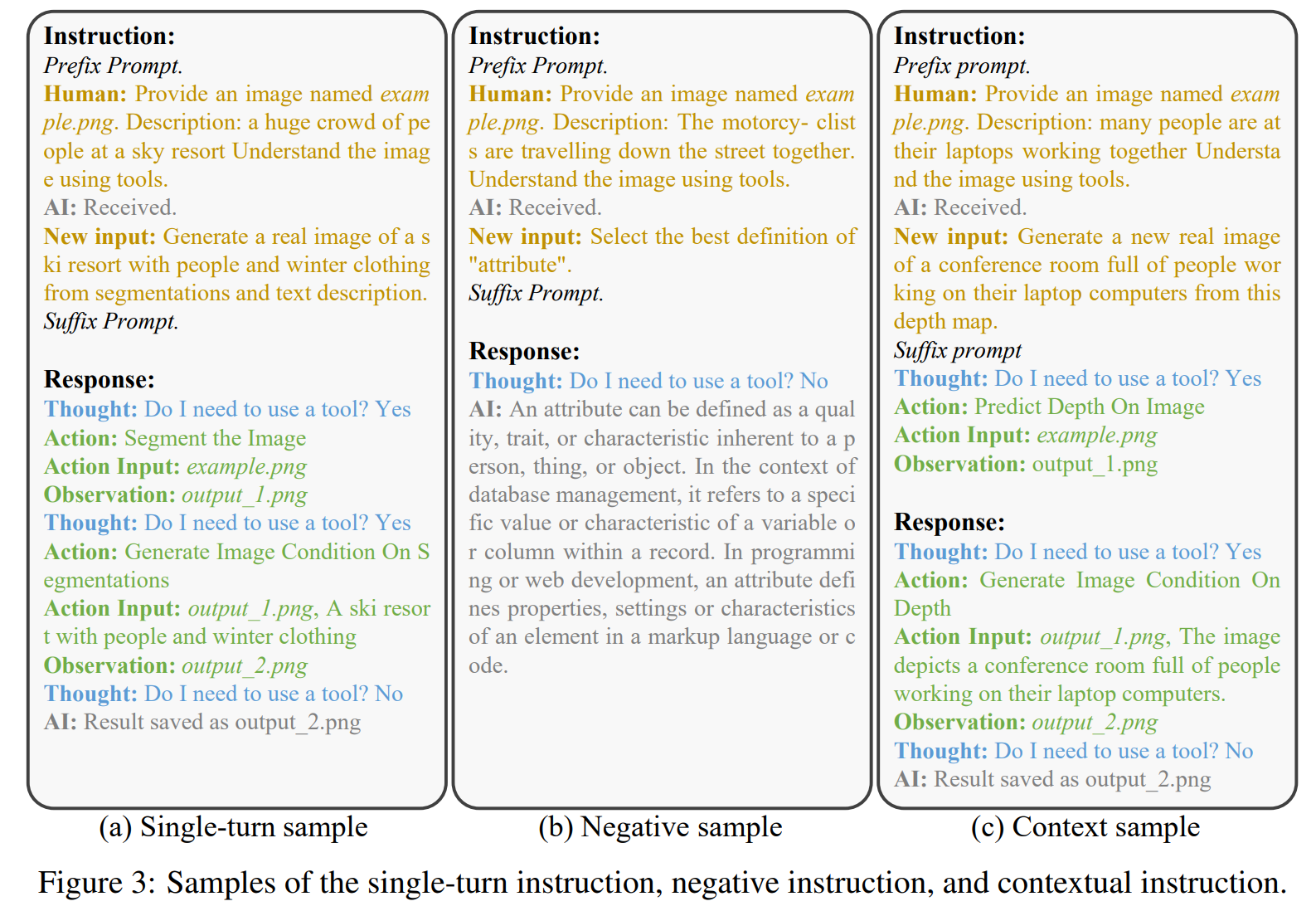
作者采用以下方式进行数据增强:
- 负样本: 为了解决指令和响应缺乏复杂性和深度的问题,生成的指令主要集中在工具使用上,即思考后的决定总是“是”。因此,微调模型存在过拟合这种决定的潜在风险。当用户指令与工具使用无关时,微调模型可能会通过调用不必要的工具而错误执行不相关操作。为了缓解这个问题,作者通过从现有数据集中选择对话数据并将其转换为所需的模板来合成负样本,并进行调整,模型可以准确判断何时使用工具。
- 上下文样本: 生成的指令采用标准且固定的单调格式,缺乏上下文结构。因此,作者截断行动链并将多个指令重新格式化为多轮对话数据。通过这种方式,合成了上下文指令跟随数据,使得调整后的模型能够在给定的上下文中调用工具。
3.2 指令微调
利用数据集YS,对现成的语言模型进行调整,使用其原始的自回归训练目标。 为了使调整变得可行,我们利用LoRA优化,冻结语言模型并仅优化Transformer层的秩分解组件。

3.3 评价
作者按照第上述操作步骤构建了一个评估数据集,以评估语言模型的工具使用能力。数据集中的每个项都经过人工验证确保准确性。
评估数据集包括两个部分:
- 验证集: 包含与训练集相同的工具(23个工具)。
- 测试集: 包括8个训练集中不包含的新工具。
评估指标:
- 使用验证集验证模型在与训练集调整后是否能正确遵循用户命令。
- 测试集用于验证模型在调整后是否能泛化到新的工具。
性能度量,基于N条人工注释的评估数据,我们设计了一个成功率来从三个方面衡量模型的性能:
- 指令准确率: 正确执行用户指令的百分比。
- 工具泛化能力: 正确使用测试集中新颖工具的能力。
- 上下文适应能力: 在不同上下文场景下适应的能力。
具体评测指标为:
- Thought成功率(SRt): 用于衡量预测决策是否与实际决策相符。
- Action成功率(SRact): 用于衡量预测的工具名称是否与实际工具名称一致。
- Arguments成功率(SRargs): 评估预测参数是否与实际参数匹配。可使用以下方程进行计算。
- 总体成功率(SR): 衡量一系列操作是否成功执行,需要同时保证思考、工具名称和工具参数的正确性。
4. 实验
4.1 实现细节
对于数据集,有以下要点:
- 教师模型:使用ChatGPT (gpt-3.5-turbo)生成原始的指令跟随数据。采用了Visual ChatGPT中概述的方法,着重于教授语言模型如何使用工具,而非进行提示工程。
- 工具: 工具包含31种工具,包括Visual ChatGPT中定义的23种工具和8种额外工具。
- 数据生成:在生成过程中,所有图像信息均来自COCO训练集。
- 训练集:生成了71K个指令-响应对,其中所有指导性数据与这23种工具相关。
- 评估数据集:分为验证集和测试集。验证集包含与训练集相同的工具,每种工具约有50个关联项目。测试集包括训练集中不存在的工具。
对于训练过程,有以下要点:
- 模型:消融实验中使用Vicuna-13B,采用LoRA技术,将投影层(查询、键、值、输出)配备了LoRA层,注意力维度和缩放因子α设为16。
- 优化器:使用AdamW优化LoRA层,同时保持语言模型冻结。
- 训练参数:模型进行了3个时期的微调,批量大小为512。学习率设为3 × 10−4,最大令牌长度限制为2048。
4.2 主要结论
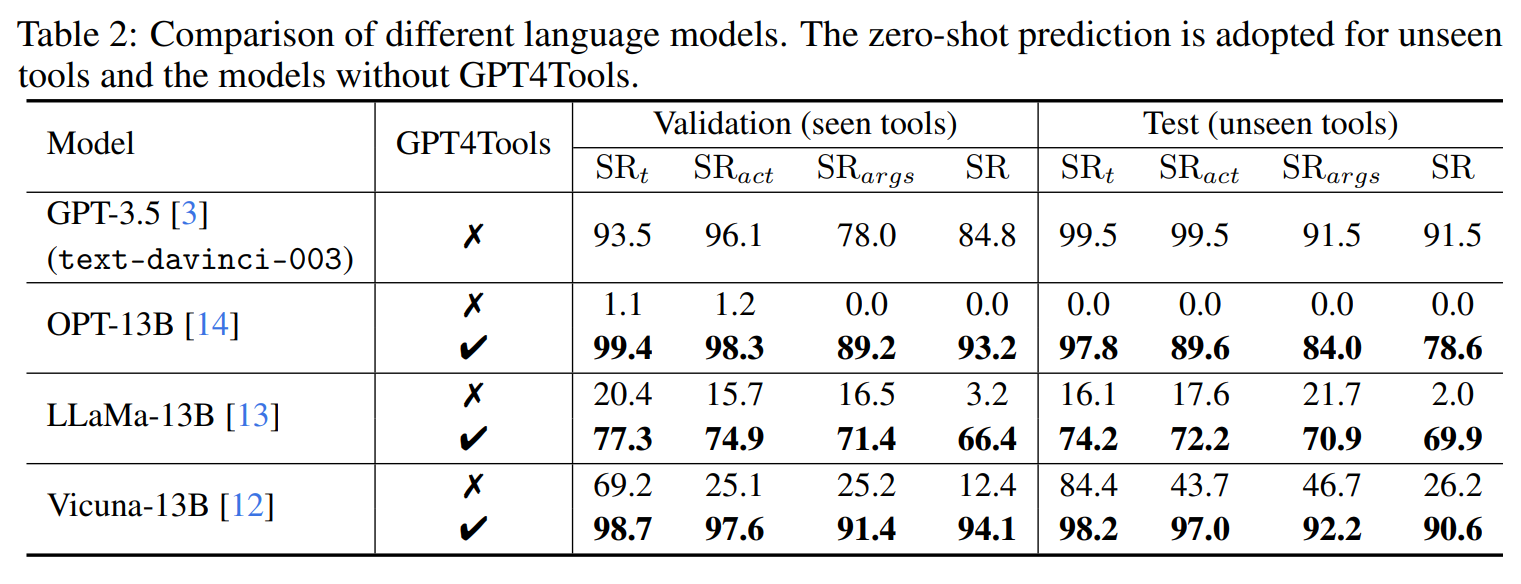
指令数据集可以使用工具教语言模型。作者展示了GPT-3.5、OPT13B、LLaMA-13B和Vicuna-13B的结果。在不使用GPT4Tools时:
- GPT-3.5类似于Visual ChatGPT。在以工具相关指令提示GPT-3.5后,它可以在验证集上达到84.8%的成功率,突显了其零-shot能力,能够遵循标准化格式并有效地使用工具。
- OPT-13B仅凭提示无法调用工具。
- LLaMA-13B和Vicuna-13B展现出一定程度的理解工具使用,但仍面临执行一系列动作的挑战。LLaMA-13B的成功率为3.2%,明显低于SRt,SRact和SRargs。Vicuna-13B的成功率比SRt低56.8%,这意味着在zero-shot设置下,Vicuna-13B在确定何时在给定上下文中使用工具方面表现出良好的洞察力。
经过与GPT4Tools的精细调整后,每个模型的工具调用能力发生了重大变化。PT-13B的成功率从0迅速增加到93.2%。类似地,LLaMA-13B的成功率从3.2%增至66.4%,Vicuna-13B的成功率从12.4%提高到94.1%。这些结果明确验证了本研究中开发的GPT4Tools确实有效地指导语言模型使用工具。
GPT4Tools对未见过的工具具有泛化能力:
- 在测试集上,GPT-3.5以零-shot方式达到91.5%的成功率。其他模型在未经GPT4Tools微调并直接利用提示调用工具时,结果与验证集上的类似。
- 经过GPT4Tools数据集微调的模型展现出一定程度的能力,可以调用之前未遇到过的工具(未出现在训练集中)。经过精细调整的LLaMA-13B模型在新工具上的成功率比原始模型高出67.9%。经过精细调整的Vicuna-13B模型在新工具上表现出90.6%的成功率,与GPT-3.5相当。
4.3 消融实验
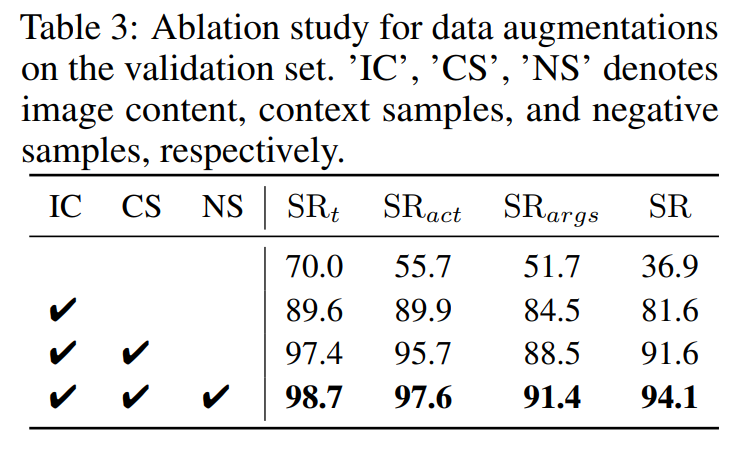
数据增强。
- 当指令与图像内容无关联时,在验证集上微调模型的成功率仅为36.9%。
- 当指令是根据图像内容生成时,验证集上的成功率大幅提升至81.6%。这种提升主要归因于生成指令的多样性和复杂性增加。
- 通过将上下文样本引入指令可以将成功率增强到91.6%。这一发现强调了将动作链划分并分配给指令和响应可以增强模型对工具的理解能力。
- 将负样本引入生成的指令后,成功率增加至94.1%。这一结果可以归因于模型在仅使用正样本训练时倾向于偏向工具调用,从而降低了辨别何时使用工具的能力。引入负样本使模型具备了确定何时使用工具的能力。
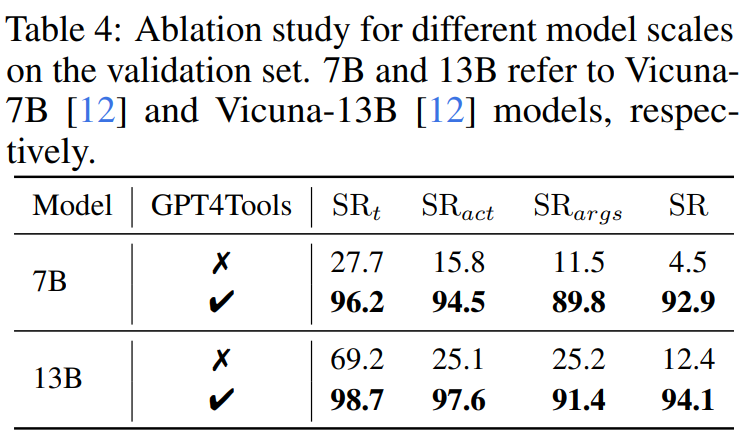
模型规模。在不同规模的模型上进行实验后发现,Vicuna-7B经过数据集的微调后能够以固定格式调用工具。具体而言,在零-shot设置下,Vicuna-7B只能达到4.5%的成功率;而经过微调后,可以达到92.9%的成功率。
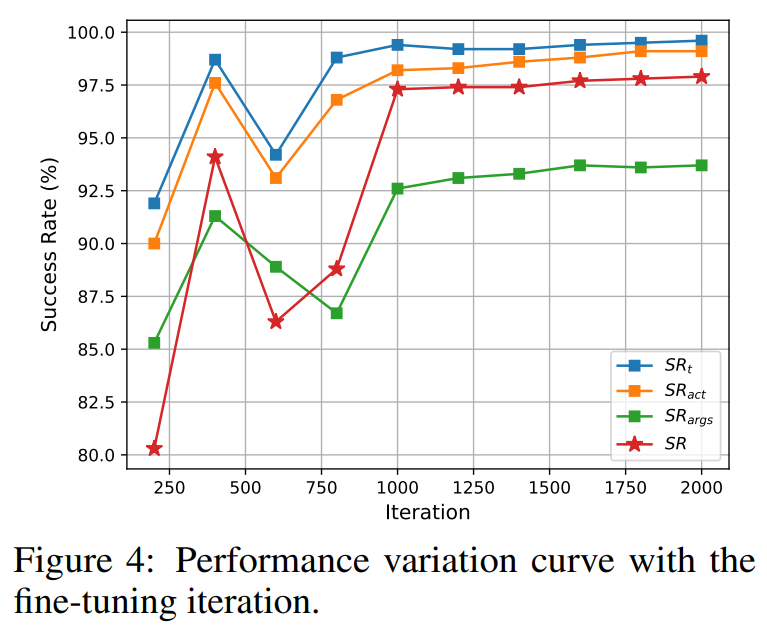
迭代次数。在400到800次迭代范围内,模型的性能在工具调用方面出现了显著波动。然而,在此范围之后,SRt、SRact、SRargs和SR稳步提升,这表明模型逐渐适应了数据集,增强了调用工具的能力。
4.4 案例
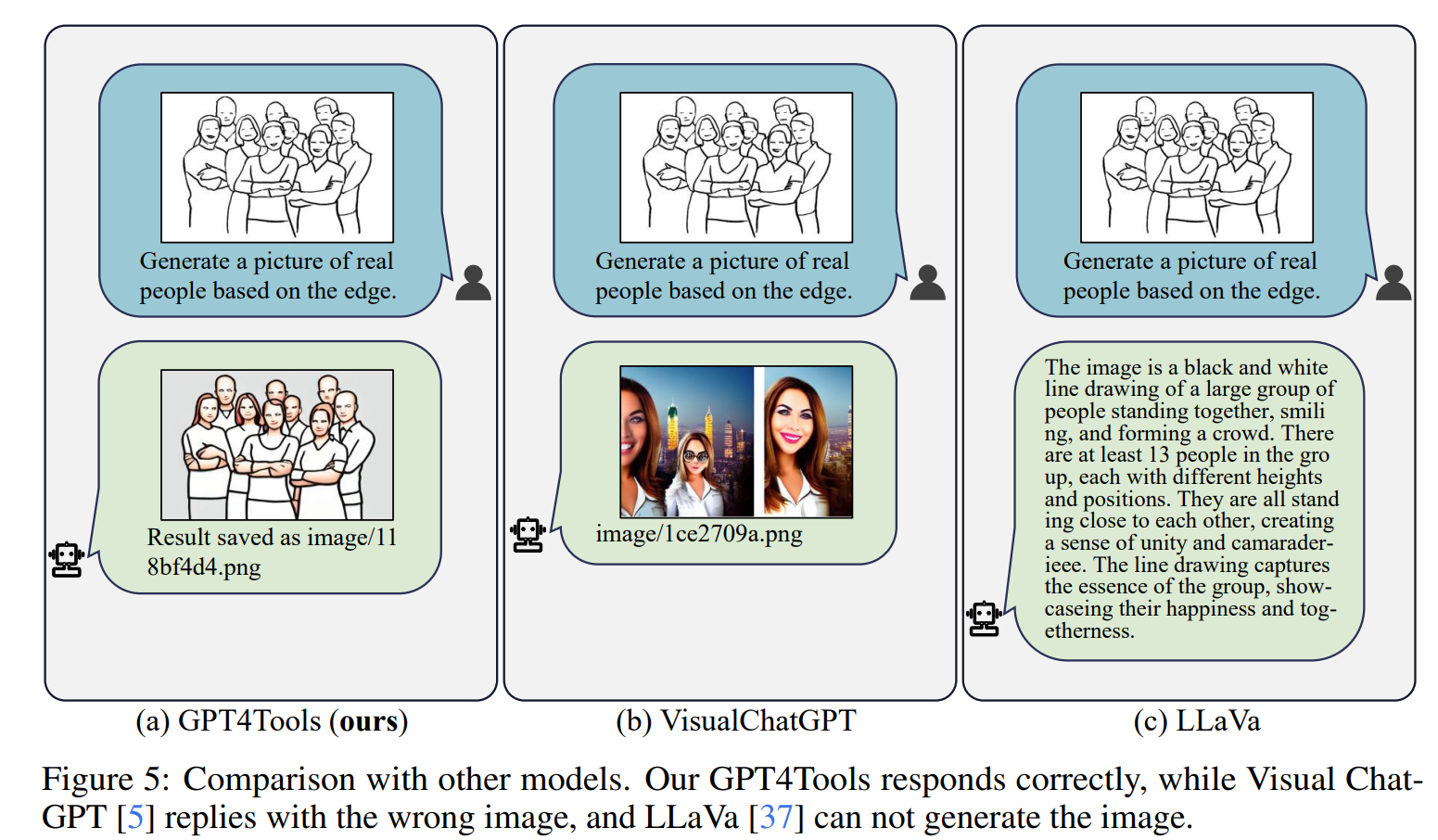
当用户提交一张图片和指令“根据边缘生成真实人物的图片”时,Visual ChatGPT生成的图像与指令关联性较弱。由于无法生成图片,LLaVa只返回了一个标题。相反,GPT4Tool产生了准确的结果,证明了本文提出的针对工具相关指令调整方法可以有效指导语言模型正确使用工具。
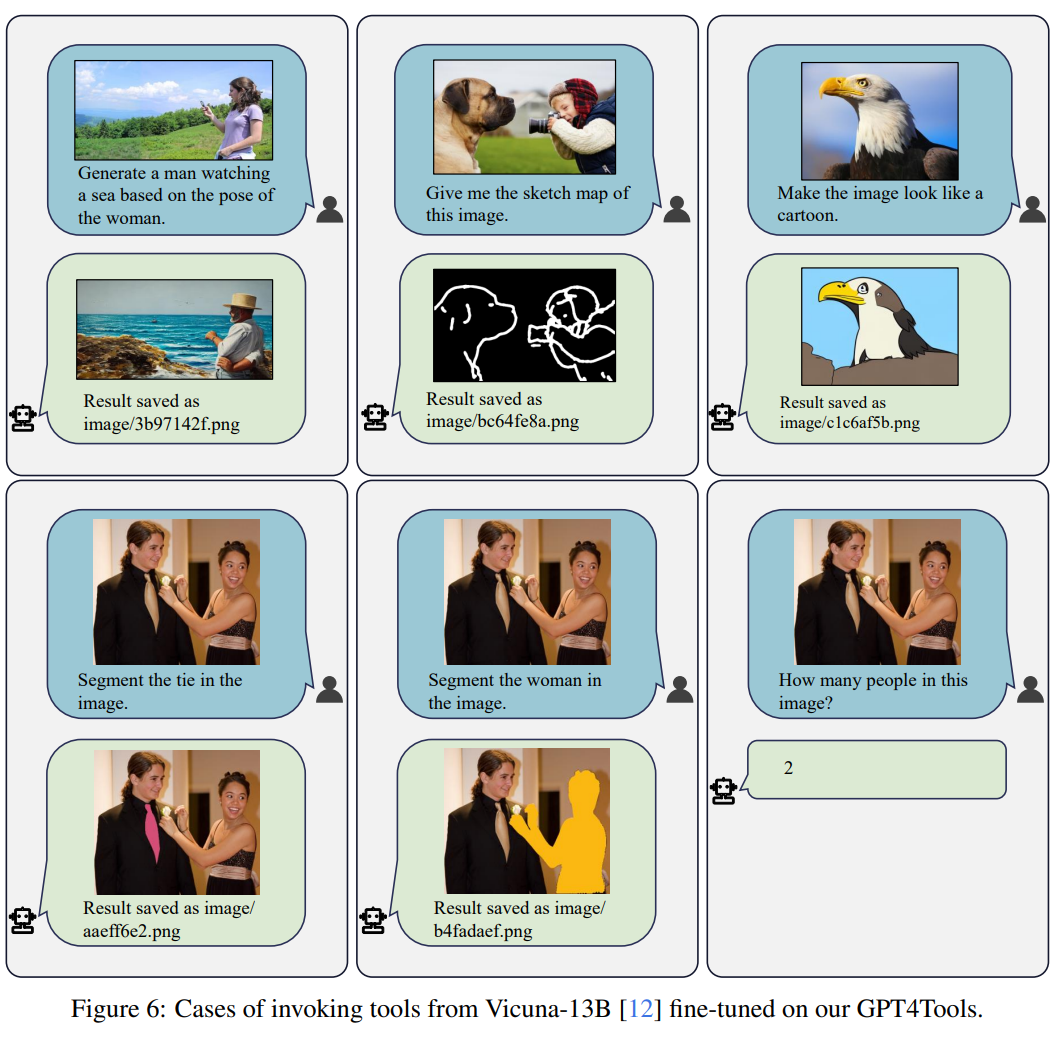
作者进一步展示了经过GPT4Tools微调的Vicuna-13B能够通过调用视觉工具完成一些视觉命令。这一发现表明向语言模型传授关于工具调用的知识可能是通往通用模型发展的途径。附录中还提供了更多案例研究。
4.5 限制
- GPT4Tools方法:虽然提出的GPT4Tools可以教导即插即用语言模型有效使用工具,但仍存在一些限制,所有模型的成功率并非都达到100%,因此对于实际应用还需要进一步改进。
- 计算效率问题:GPT4Tools教导模型显式调用工具时使用冗长且固定的提示,这种方法会降低计算效率,因为基于注意力的架构需要计算所有标记之间的关系。另外,随着工具数量的增加,提示长度可能会超过LLM的有限上下文长度。在这种情况下,可以利用工具检索技术来过滤出一个小型工具集,然后应用基于GPT4Tools的LLM进行工具选择和调用。
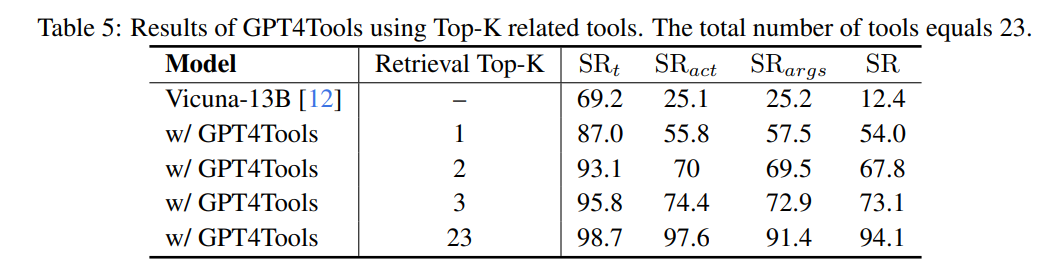
- 工具检索策略:通过BM25,根据用户输入从定义的23个工具中检索前K个工具。当检索到的工具数量增加到3个时,成功率提高到73.1%。尽管检索策略在一定程度上可以减少对长上下文模型大量工具的依赖,但其成功率无法匹配原始模型。这一结果归因于检索器的能力不足,因此在未来,建立专门的检索器用于工具名称检索是必要的。
- 未来展望:未来应探索如何使模型隐式调用各种工具而非使用复杂提示。总的来说,我们的GPT4Tools方法为使语言模型具备使用多模态工具的能力提供了可行的途径。
有关本专栏的更多内容,请参考大语言模型文献调研专栏目录
者自知才疏学浅,难免疏漏与谬误,若有高见,请不吝赐教,笔者将不胜感激!
softargmax
2024年4月11日

















 2845
2845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









