









23年2月Meta AI的论文“Toolformer: Language Models Can Teach Themselves to Use Tools”。
语言模型 (LM) 可以仅通过几个示例或文本指令来解决新任务,尤其是大规模任务。 矛盾的是,它们还难以实现基本功能,例如算术或事实查找,而更简单和更小的模型在这些功能上表现出色。 Toolformer,一个经过训练的模型,用于决定调用哪些 API、何时调用它们、传递哪些参数以及如何最好地将结果合并到未来的token预测中。 这是通过自监督的方式完成的,只需要为每个 API 进行少量演示即可。 其整合了一系列工具,包括计算器、问答系统、搜索引擎、翻译系统和日历。 Toolformer 在各种下游任务中显着提高了零样本性能,通常可以与更大的模型竞争,而无需牺牲其核心语言建模能力。
基于最近的想法,即用大型 LM 和上下文学习(Brown,2020)从头开始生成整个数据集(Schick & Schütze,2021b;Honovich ,2022;Wang et al., 2022):仅给出一些关于如何使用 API 的人工编写示例,让 LM 通过潜API 调用来标注巨大的语言建模数据集。 然后,用自监督损失来确定哪些 API 调用实际上有助于模型预测未来的tokens。 最后,根据 LM 认为有用的 API 调用对 LM 本身进行微调。 如图是Toolformer 的示例性预测。 该模型自主决定调用不同的 API(从上到下:问答系统、计算器、机器翻译系统和维基百科搜索引擎)来获取对完成一段文本有用的信息。通过这种简单的方法,LM 可以学习控制各种工具,并自行选择何时以及如何使用哪种工具。

给定一个纯文本数据集 C = {x1,…,x|C|},首先将该数据集转换为通过 API 调用增强的数据集 C*。 这分三个步骤完成,如图所示:首先,利用 M 的上下文学习能力对大量潜API 调用进行采样。 然后执行这些 API 调用,最后检查获得的响应是否有助于预测未来的tokens; 这用作滤波的标准。 滤波后,合并不同工具的 API 调用,生成增强数据集 C*,并在此数据集上微调 M 本身。
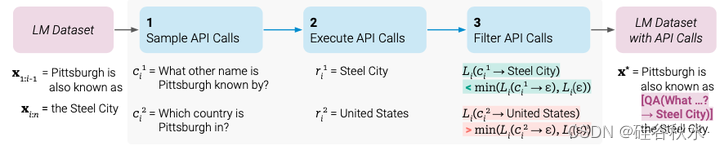
该图以问答工具为例。给定输入文本 x,首先对位置 i 以及相应的 API 调用候选 c1i 、 c2i 、 。 。 。 , cki 进行采样。然后,执行这些 API 调用并过滤掉所有不会减少下一个token损失 Li 的调用。 所有剩余的 API 调用都与原始文本交错,生成新文本 x*。
对于每个 API,编写一个提示 P(x),鼓励 LM 通过 API 调用来标注示例 x = x1,…,xn。 问答工具的此类提示示例如图所示:

设 pM (zn+1 | z1, …, zn) 为 M 分配给token zn+1 作为序列 z1, … zn延续的概率。 首先,对于每个位置 i ∈ {1,…,n},计算M 指定在位置 i 处启动 API 调用的概率 pi = pM( | P(x), x1:i−1) ,采样用于进行 API 调用最多 k 个的候选位置。给定采样阈值 τs,保留所有位置 I = {i | pi >τs}; 如果还有超过k个这样的位置,只保留前k个。
给定序列 [P (x), x1, … , xi−1, ] ,对每个位置 i ∈ I,从M 中采样,获得最多 m 个 API 调用 c1i, …, cmi,作为前缀,而 作为序列结束token。
下一步,执行 M 生成的所有 API 调用以获得相应的结果。 如何完成完全取决于 API 本身——例如,它可能涉及调用另一个NN、执行 Python 脚本或使用检索系统在大型语料库上执行搜索。 每个 API 调用 ci 的响应,都需要是单个文本序列 ri。
直观地说,相比于根本不接收 API 调用或仅接收其输入来说,如果向 M 提供此调用的输入和输出,使模型更容易预测未来的tokens,那么 API 调用对 M 是有帮助的。这也是API调用滤波的标准。
对所有 API 的调用进行采样和滤波后,最终合并剩余的 API 调用并将它们与原始输入交错。 也就是说,对于输入文本 x = x1,…,xn 以及位置 i 处相应 API 调用和结果 (ci , ri ),构造新序列 x* =x1:i−1, e(ci, ri), xi:n; 对具有多个 API 调用的文本进行类似处理。 对所有 x 执行此操作会生成API 调用进行扩充的新数据集 C*。 用这个新数据集来微调 M ,使用标准语言建模目标。 至关重要的是,除了插入API 调用之外,增强数据集 C* 包含与原始数据集 C 完全相同的文本。 因此,在 C* 上微调 M,采用在 C 上微调相同的内容。此外,由于 API 调用恰好插入到这些位置,并且正是那些帮助 M 预测未来tokens的输入,因此在 C* 的微调使语言模型完全根据自己的反馈来决定何时以及如何使用哪种工具。
当微调后使用 M 生成文本时,执行常规解码,直到 M 生成“→”token,表明它接下来期望 API 调用的响应。 此时,中断解码过程,调用适当的 API 来获取响应,并在插入响应和 token后继续解码过程。
探索各种工具来解决常规 LM 的不同缺点。 对这些工具施加的唯一限制是(i)它们的输入和输出都可以表示为文本序列,并且(ii)可以获得它们预期用途的一些演示。 具体来说,探索以下五个工具:问答系统、维基百科搜索引擎、计算器、日历和机器翻译系统。 如表显示了与每个工具关联API 的潜调用和返回字符串的一些示例。

- 问答(QA)。第一个工具是基于另一个 LM 的问答系统,可以回答简单的事实问题。 具体来说,用 Atlas(Izacard ,2022),这是一种在Natural Questions进行微调的检索增强型 LM(Kwiatkowski,2019)。
- 维基百科搜索。第二个工具是一个搜索引擎,给定一个搜索词,它会从维基百科返回简短的文本片段。 与问答工具相比,这种搜索使模型能够获得有关主题的更全面的信息,但需要它自己提取相关部分。 作为搜索引擎,用 BM25 检索器(Robertson,1995;Baeza-Yates,1999)对 KILT (Petroni,2021)的维基百科转储进行索引。
- 计算器。第三个工具。
- 机器翻译系统。第四个工具是基于 LM 的机器翻译系统,可以将任何语言的短语翻译成英语。 更具体地说,用 600M 参数 NLLB(Costa-jussà et al., 2022)作为多语言机器翻译模型,适用于 200 种语言(包括资源匮乏的语言)。 使用快速文本分类器自动检测源语言(Joulin,2016),而目标语言始终设置为英语。
- 日历。最后一个工具是日历 API,在查询时,它会返回当前日期,而不需要任何输入。 这为需要一定时间意识的预测提供了时间背景。
Toolformer训练中,每个 API 最多使用 25,000 个示例。 最大序列长度 1,024。 有效批量大小为 128。所有模型均使用 DeepSpeed 的 ZeRO-3 进行训练(Rasley,2020)。 用 8 个 NVIDIA A100 40GB GPU 和 BF16。 训练最多 2k 步骤,在 CCNet 的小型开发集上评估 PPL,其中每 500 个步骤包含 1,000 个示例。 选择表现最好的检查点。















 1032
1032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









