










24年5月来自苹果公司的论文“Revisiting MoE and Dense Speed-Accuracy Comparisons for LLM Training”。
混合专家 (MoE) 通过增加模型容量同时保持计算成本不变来提高性能。在MoE 与密集模型比较时,通常采用以下设置:1) 使用 FLOPS 或激活参数作为模型复杂度的衡量标准;2) 所有模型训练相同数量的 tokens。这种设置有利于 MoE,因为 FLOPs 和激活参数不能准确衡量稀疏层中的通信开销,从而造成 MoE 的实际训练预算更大。
这项工作重新审视该设置,采用步时间(step time)作为模型复杂度更准确的衡量标准,并确定 Chinchilla 计算最优设置下的总计算预算。为了在现代加速器上高效运行 MoE,采用3D 分片方法,将密集-到- MoE 的步时间增加保持在健康范围内。在一组 9 个 零样本、2 个 单样本 英语任务以及 MMLU 5-样本 和 GSM8K 8样本 评估了 MoE 和密集 LLM模型,规模分别为 6.4B、12.6B 和 29.6B。实验结果表明,即使在这些设置下,MoE 在速度-准确度权衡曲线上的表现也始终优于密集 LLM,并且差距明显。
今后实现和分片策略将在 https://github.com/apple/axlearn 上发布。

架构
密集 LLM 架构通常遵循 LLaMA2(Touvron [2023])。具体来说,采用以下 Transformer 架构修改:1)预归一化和 RMS Norm(Zhang & Sennrich [2019]);2)SwiGLU(Shazeer [2020])作为激活函数;3)RoPE(Su [2023])作为位置嵌入。由于实验侧重于训练,因此不使用分组查询注意(Ainslie [2023])。
MoE 架构与密集 LLM 共享相同的架构,只是在 MoE 层中用稀疏的层替换 FFN。另外还做出以下设计决策:
稀疏层数。稀疏层越多,模型稀疏度越高,性能通常越好。另一方面,它增加模型的总参数量和计算成本。此超参的典型选择包括 Every-K(Jiang [2024]、Zoph [2022]、Du [2022])或 Last-K(Ruiz [2021]、Komatsuzaki [2023])。在实验中采用 Every-4 设置,因为它提供了更好的速度-准确度权衡。具体来说,用稀疏层替换每 4 层中的最后一个密集层。
专家数。专家越多,模型容量就越大,同时保持模型的激活参数不变。现有研究(Du et al. [2022]、Fedus et al. [2022]、Clark et al. [2022])表明,使用更多专家可带来单调的性能提升,当专家数超过 256 时,这种提升会逐渐减弱。尝试了不同数量的专家,在3D 分片策略中,更多专家可带来更好的性能,而不会影响步时间。
路由方法和专家量。在所有实验中采用 Top-K 路由(Shazeer et al. [2017])进行自回归建模,其中 K = 2,专家量 C = 2。其他常见的路由方法包括 Top-1(Fedus et al. [2022])和专家-选择路由(Zhou et al. [2022])。
辅助损失。为了鼓励更好的专家负载平衡以实现 Top-K 路由,采用系数为 0.01 的负载平衡损失(Lepikhin[2021]、Du[2022])。还采用了 ST-MoE(Zoph[2022])中提出的路由器 z-loss,系数为 0.001,这有助于稳定大型 MoE 训练。
3D分片和MoE实现
由于用步时间作为模型复杂度的度量,因此优化稀疏 MoE 的分片策略是基础。这项工作采用跨 3 个度量轴的 3D 分片策略:(数据、专家、模型)。
数据。数据轴仅用于数据并行。沿着此轴,数据被均匀划分,模型权重被完全复制。此轴通常用于片间并行,其中通信通常发生在较慢的数据中心网络 (DCN) 上。
专家。专家轴旨在对稀疏 FFN 中的专家进行分片。为了优化计算与内存的比率,每个核最多放置一个专家。专家轴在保持步时间不变的同时扩展一个模型中的专家数时,提供了灵活性和效率。请注意,对于密集层,专家轴用作全分片数据并行(FSDP)(Zhao[2023])(FSDP)的网格轴,它将模型参数分片到数据并行核。
模型。 Model 轴用于分片注意头和 FFN 隐维度。此轴在所有轴之间产生最重的通信,通常用于片内模型并行,其中通信通过快速核间互连 (ICI) 进行。
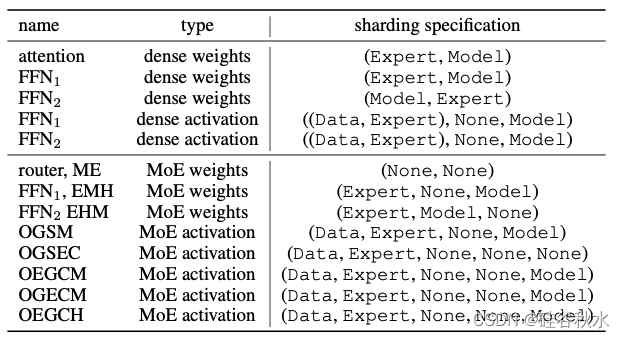
GShard (Lepikhin[2021]) 提供了一种高效的 MoE 层实现,广泛使用 Einsum 符号来表达门控、调度和组合操作。这项工作采用了 Praxis 库(https://github.com/google/praxis)中提供的 GShard 实现,以及 Mesh-Tensorflow (https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py)中使用的外批次技巧。具体而言,MoE 层的输入tokens被均匀地分成 O 个外批次,从而在所有激活中产生一个额外的形状主导维度 O。然后,沿数据轴外批次维度分片以获得最佳效率。下表概述MoE Transformer分片规格。
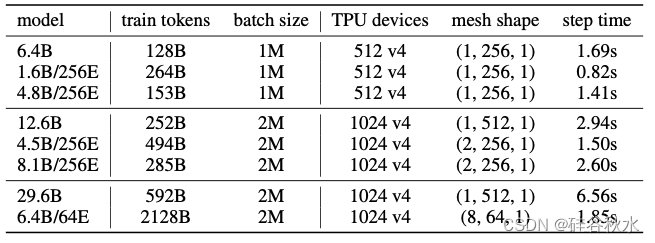
训练计算预算和模型设计
主要评估MoE 和密集 LLM 在 6.4B、12.6B 和 29.6B 三个规模上的速度-准确度比较。在每个规模上,采用 Chinchilla 的tokens-对-参数比 (Hoffmann[2022]) 20:1 来确定相应密集模型的训练tokens数。总计算预算由密集模型的训练步骤时间和总训练步骤数相乘确定。根据这个预算,设计 MoE 并确定步骤时间和训练步骤,固定批次大小和硬件加速器。与之前从相同规模的密集主干构建 MoE 的工作不同,用模型大小换取训练tokens,并从较小的主干设计 MoE。下表提供了实验中使用的所有模型最终训练预算。
实验设置
用与 LLaMA2 (Touvron[2023]) 类似数据混合的训练语料库。所有模型均使用 AdamW 优化器 (Loshchilov & Hutter [2019]) 进行训练,其中 β1 = 0.9、β2 = 0.95 和 ε = 10-5。采用余弦学习率进度,预热步为 2000,衰减至峰值学习率的 10%。用 0.1 的权重衰减和 1.0 的梯度剪裁。用 SentencePiece token化器 (Kudo & Richardson [2018]) 和字节-对编码算法 (Sennrich[2016])。在 TPU-v5e 设备上训练小规模模型,在 TPU-v4 设备上训练大规模模型。
MoE 和密集 LLM 在广泛的基准上进行评估:
核心英语任务 (CoreEN)。对常识推理、阅读理解和问答基准上的性能进行评估,包括 ARC Easy 和 Challenge (0-样本) (Clark et al. [2018])、HellaSwag (0-样本) (Zellers et al. [2019])、WinoGrande (0-样本) (Sakaguchi et al. [2019])、PIQA (0-样本) (Bisk et al. [2019])、SciQ (0-样本) (Sap et al. [2019])、LAMBADA (0-样本) (Paperno et al. [2016])、TriviaQA (1-样本) (Joshi et al. [2017]) 和 WebQS (1-样本) (Berant et al. [2013])。在实验中,报告了七个 0 样本测试任务(表示为 CoreEN (0样本))的平均性能和全部九个任务(表示为 CoreEN (all))的平均性能。
MMLU。MMLU 上的 5 样本测试性能(Hendrycks et al. [2021])。
数学推理。GSM8K 上的 8 样本测试性能(Cobbe et al. [2021])。
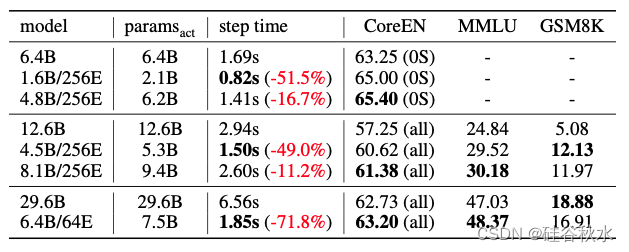
下表给出预训练的结果比较:















 7571
7571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









