









23年9月清华和中关村实验室的论文“Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf”。
探讨将大型语言模型(LLM)应用于通信游戏,并提出一个无微调的框架。使LLM保持冻结状态,并依赖于对过去通信和经验的检索和反思来进行改进。对具有代表性且被广泛研究的通信游戏“狼人杀”的实证研究,在不调整LLM参数的情况下有效地玩狼人杀游戏。对于游戏中的每个角色,通过提示实现一个基于LLM的个体智体。
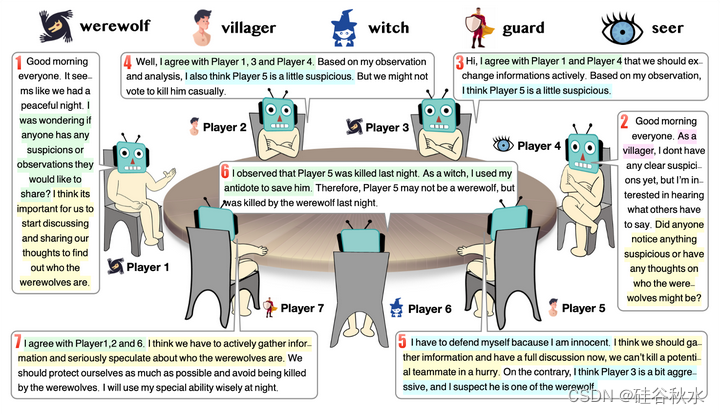
狼人杀游戏概要:共有5个角色和7名玩家,每个角色都由LLM自主扮演。如下图所示:每次说话前的数字表示说话顺序。一些社会行为主要可以在这个图中观察到,包括信任、对抗、伪装和领导。
如图所示是响应生成的提示概要,由四个部分组成:
(1)游戏规则、指定的角色、每个角色的能力和目标,以及有效游戏策略的一些基本人类先验知识;
(2) 最近的K个消息、一组启发式选择的信息化消息和智体的反思,主要挑战是LLM的上下文长度有限;
(3) 从过去的经验中提取的建议,不微调模型情况下,从经验中学习;
(4)引发推理的思维链IoT。


















 8061
8061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









