









23年12月论文“LARP: Language-agent Role Play For Open-world Games“,来自上海妙世界科技有限公司。
语言智体在规定的环境和短暂的时间内表现出了极强的解决问题技能。然而,随着开放世界模拟的复杂性不断加大,迫切需要能够灵活适应复杂环境并持续保持长期记忆以确保连贯行动的智体。为了弥合语言智体和开放世界游戏之间的差距,作者引入了角色扮演语言智体(LARP),包括一个记忆处理和决策助手的认知架构,一个具有反馈驱动可学习动作空间的环境交互模块,以及一种促进各种个性协调的后处理方法。LARP框架细化了用户和智体之间的互动,预定义独特背景和个性,最终增强开放世界环境中的游戏体验。此外,它还强调语言模型在娱乐、教育和各种模拟场景等一系列领域的不同用途。
智体系统通常分为三个部分:记忆、规划和动作(工具使用)[Weng,2023]。记忆系统是事实、思考等储存库,具有存储和检索的能力。因此,记忆方面的工作主要涉及输入/输出功能,包括记忆压缩[Hu,2023]、存储和检索[Park2023,Zhong2023,Huang2023]。规划组件负责与智体的行为和语言相关的决策方面。智体的能力很大程度上取决于这一部分。规划能力[Yao2023,Liu2023b,Yao2022,Shinn2023,Liu2021 3c,Wang2023f]和推理能力[Wei2022,Madaan2023]在这个组件中实现,相关工作通常围绕这两种能力展开。最后一个组成部分是工具的使用和操作,这意味着智体的能力得到了增强,有助于它们执行更复杂、更困难的任务。
本文的工作包括使用工具[Nakano2021]和学习新动作[Schick2023]。如图是LARP的概览图:认知架构是开放世界游戏中角色扮演语言智体的基本组成部分。它提供了一个逻辑框架,并实现了智体的自我识别。认知架构如图所示,它包括四个主要模块:长期记忆、工作记忆、记忆处理和决策。长期记忆模块用作包含具有大存储容量的存储仓库。工作内存充当临时缓存,内存空间有限。记忆处理模块是认知结构中最重要的单元。然后,决策模块基于检索的信息来导出智体的后续动作。
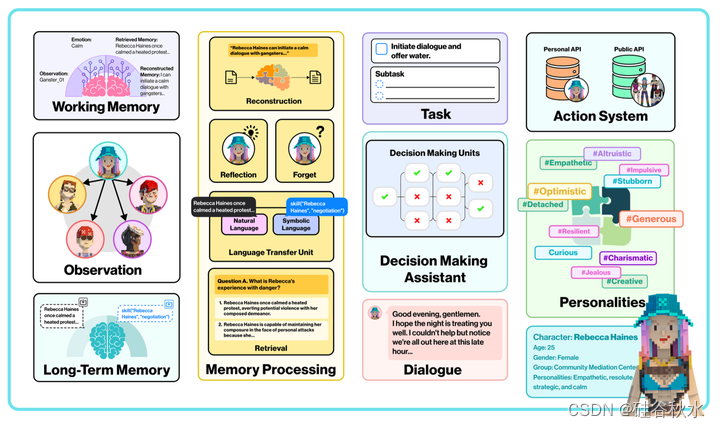
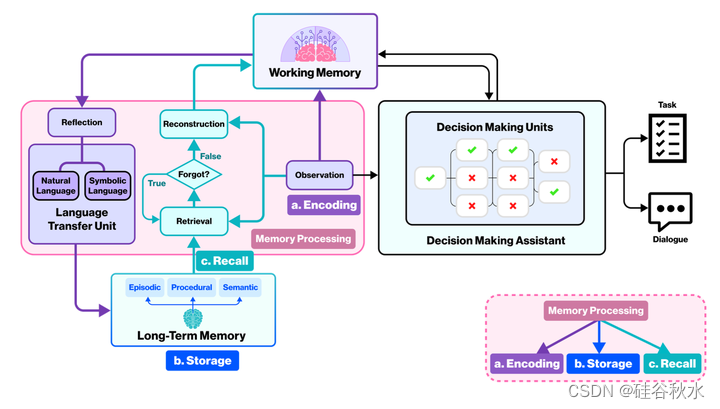
如图是LARP的认知工作流。这代表一个循环:来自长期记忆和观察的信息在记忆处理模块中进行处理,并传输到工作记忆模块。工作记忆模块中的信息与观察到的信息一起被输入到决策助手中,决策助手最终生成决策或对话。记忆处理有三个主要阶段:编码、存储和回忆。编码是将信息转换为可以存储在内存中形式的过程。存储是将信息保存在内存中的过程。回忆是从记忆中检索信息的过程。
在认知科学中,长期记忆由两种类型的记忆组成:陈述性(declarative)记忆和过程性(procedural)记忆。陈述性记忆又分为语义(semantic)记忆和情景(episodic)记忆[Laird2019,Tulving1972]。语义记忆是指通过对世界的概念知识和事实知识而获得的一般知识记忆。在开放世界游戏的背景下,它可以被认为是封装了与相关世界观一致的游戏规则和记忆的部分。在系统中将语义记忆分为两部分。一个是用外部数据库实现的,因为它的内容不经常更改。同时,一些语义记忆以符号语言存储在长期记忆模块中。情节记忆是指对个人经历的特定事件记忆。这些可能是与其他玩家或智体有关的记忆。在记忆系统中,长期记忆模块中采用矢量数据库来存储和检索这些记忆。相关的衰减参数被引入,因为记忆可能会被遗忘,相关性分数会随着时间的推移而降低。当使用LLM进行推理时,可以向量查询轻松检索此类内存内容。
过程性记忆是指可以在无意识思考的情况下进行的动作或技能[Roediger1990],如游泳、骑自行车等。这些具有动作属性的技能在系统中被表示为动作空间中的API。动作空间分为公共API和个人API。个人API可以通过学习[Sumers,“Cognitive architectures for language agents“,2023]进行扩展。
在长期记忆模块中,将所有感知记忆分别存储在语义记忆区和情景记忆区。一种名为“基于问题的查询”的方法,将自提问生成为可通过向量相似性和谓词逻辑在搜索中利用的查询。这种方法便于在回忆模块中检索语义记忆和情节记忆,从而提高了记忆利用的整体效率。
工作记忆主要保存执行复杂认知任务(如推理和学习)和交互任务所需的观察信息和检索的长期记忆[Badeley2003,Miller2017]。这些信息通常通过智体的观察作为游戏方提供的自然语言数据而获得。顾名思义,短期记忆代表了一个记忆阶段,它在短时间内保留信息,通常只持续几秒到一分钟[Atkinson&Shiffrin1968]。对人类来说,在短期记忆中保留条目的平均能力约为7±2,保留时间约为20至30秒[Miller1956]。在这项工作中,这两个概念被实现为同一个模块,统称为工作记忆。在体系结构中,它作为一个数据缓存存在,从中提取信息并将其放入提示的上下文中。
记忆处理模块主要处理已经存储和将要存储的记忆。记忆的三个主要阶段是编码、存储和回忆[Melton,1963]。具体而言,感知输入信息被编码并转化为长期记忆中的内容,使其能够在长期记忆的空间中被回忆。在LARP中,处理游戏中提供的所有结构化观测信息,将其与检索的内容相结合,并将其存储在工作记忆中,模拟这一过程。该信息作为决策模块中一系列逻辑处理单元的输入,不断更新工作记忆中的内容。一旦工作记忆的长度达到一定的阈值,就会触发反思,在此过程中,无效记忆被过滤掉,处理后的自然语言记忆和符号语言记忆分别作为情景记忆(episodic memory)和语义记忆(semantic memory)存储。
记忆编码的核心是语言转换系统。通过调整语言模型和概率模型,自然语言被转换为概率编程语言(PPL)[Wong 2023]和逻辑编程语言。PPL主要处理概率推理,而逻辑编程语言主要涉及事实推理。此外,记忆编码也应受到先前知识一致性的影响,这意味着过去的知识将影响当前的理解[Bartlett1995]。
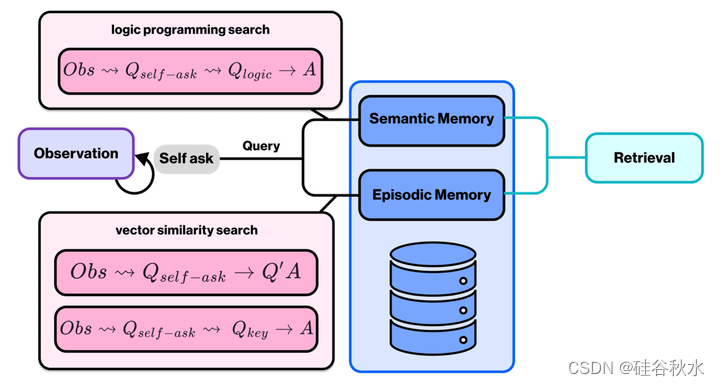
对人类来说,回忆是指从过去获取信息的心理过程。而在本文的架构中,它是从长期记忆中检索信息的过程。它首先涉及从长期记忆中进行复合检索,包括通过向量相似性和谓词逻辑进行检索。首先,采用自问策略来形成查询,促使LLM提出关于智体的观察、个性和经验的问题。在获得查询后,采用了3种方法进行检索。对于逻辑编程搜索,LLM使用逻辑编程语言生成一个查询,该查询根据可用的规则和事实回答自问问题。对于相似性搜索,有两种方法可用。一种方法是用自提问作为向量相似性搜索的查询,与情景记忆向量数据库中的问答对进行匹配。另一种方法是使用自提问中提取的关键词与同一数据库中的自然语言记忆相匹配。这个过程将被重复,直到获得最终答案,这也可以被视为语义检索[Press et al.2022]。如图显示了回忆心里过程的详细控制流程:首先对观察结果进行自提问,得到自提问的问题;使用自提问作为查询,采用三种不同的检索方法;Qself−ask是指用作查询的自提问,Qlogic代表谓词逻辑查询语句,Qkey是提取的关键字,Q′A代表问答对。
基于回忆能力,该文架构采用CoT[Wei et al.,2022]对检索的内容和观察的信息进行推理,并进行记忆重建,即使用先验知识在一定程度上影响观察的事实[Lovtus&Palmer,1974],尽管重建的记忆可能会失真。此外,还模拟了回忆工作流程中人类遗忘的过程。当检索系统运行时,引入由Wickelgren幂律(power law)表示的衰减参数σ来标记这种记忆的遗忘概率[Wixted&Carpenter,2007]。通过多轮记忆重建和遗忘过程,这个认知架构最终可以模拟记忆曲解的情况。
决策模块在观察和工作记忆的共同作用下产生最终决策。决策模块的核心部分是可编程单元的有序集群。每个单元将处理工作记忆和上下文中的内容,实时将结果更新到工作记忆中。这些单元可以是简单的信息处理单元,例如进行情感计算的单元,也可以是配备有专门微调LLM模型的复杂单元,例如意图分析和输出格式化。这些单元是无限可扩展的,可以处理所有类型的内存处理任务。当每个单元与工作记忆通信时,它会实时更新工作记忆,使智体能够在过程中观察到变化时及时做出反应。这些单元的执行顺序将由语言模型助理确定。决策模块的最终输出可以是NPC的任务或对话内容。
对于开放世界游戏中的角色扮演语言智体来说,通过认知架构基于当前观察生成任务,只能在智体内实现目标。然而,在动作自由、游戏内容丰富的开放世界游戏中,智体需要通过连接内部和外部与游戏环境进行互动。在使用语言智体与开放世界游戏环境交互方面有各种工作[Wang2023d,Zhu2023,Yang2023e,Wang2023e]。例如,Voyager使用了自动课程的概念,向GPT-4提供环境观测的内容和状态来获得目标。然后,GPT-4被提示生成功能代码以达到目标。本文还提出技能库(skill library)方法,该方法将生成的代码描述嵌入为KEY,将代码嵌入为VALUE,通过添加K-V对来实现引入新技能的高可扩展性。Octopus利用视觉-语言模型(VLM)来获取观测结果。然而,这种方法可能导致数据特征分布的高维度,导致可控性差。此外,VLM的操作成本很高,并且在游戏中收集数据集的先验知识很有挑战性。
如图显示了基本的交互过程。内部是指由观察和认知架构产生的工作记忆和基于当前情况需要执行的任务。动作空间是智体在游戏世界中的可执行动作API,包括公共API和个人API。个人API库存储任务-API对,而公共API是基本操作。个人API可以是一系列基本动作,有助于API的快速决策和重用。
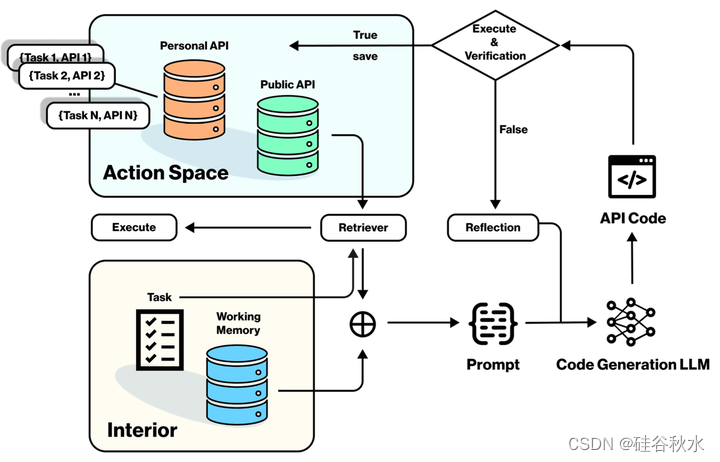
一旦在决策模块中生成了相应的规划,首先会尝试将总体任务目标分解为几个子任务目标。这些子任务目标呈现为严格有序序列-敏感的安排。对于每个任务目标或子任务目标,整个系统都会将其与工作内存集成。然后,它将使用检索器在个人API库和公共API库中分别进行搜索。如果与任务相对应的动作已经存在于个人API库中,则立即执行该动作。否则,系统将用整个动作空间和内部内容完成相应的提示,用微调LLM生成结构化代码。在生成的代码块成功执行和验证后,它们以(Task,API)的形式作为新接口存储在个人API库中以供将来使用。如果验证失败,则激活反思单元以生成新的代码块[Shinn2023]。同时,还收集成对的提示和生成代码,作为微调代码生成LLM的训练集[Patil2023]。在成功执行和验证后,通过RLHF反馈结果,增强模型的能力。
在角色扮演中,不同的个性对于提高语言智体的认知能力至关重要。将不同的个性结合起来,可以让语言模型更好地理解不同的观点,描绘不同的文化和社会群体。在复杂场景中扮演不同角色的语言模型,必须以其独特的方式深刻理解、回应和表达。这就要求模型拥有具有广泛个性的类人思维过程。理解不同语言表达的产生,处理多元文化内容,展示不同的思想、观点、情绪和态度,所有这些都需要模型来适应这些不同的个性。
LARP采用模拟一组模型的策略,这些模型经过各种调整,解决智体的多样化观点。这些模型可能应用于不同的模块中。在训练阶段,预训练几个不同规模的基础模型。预训练数据集包含不同文化和群体的观点。预训练后,这些基础模型在一系列角色和角色的指令数据集上进行监督微调(SFT),增强指令跟随和角色扮演能力[Chen2023b,Dong203]。该指令数据集是基于SOTA模型生成的问答对,通过数据蒸馏建立。然后,基于人类反馈,通过评估、修改和调整,对数据集进行优化。
可以创建多个数据集,并针对反思、代码生成和意图分析等功能采用LoRA进行微调。LoRA可以与不同规模的基础模型动态集成,创建具有不同能力和个性的模型集群。这些功能涵盖了语言风格、情感、动作生成、反思、记忆重建等任务。
然而,微调语言模型构建用于角色扮演的不同LoRA,其主要挑战之一是获取高质量的数据。成功的微调需要高质量的自定义数据集,这些数据集需要仔细构建,捕捉角色的各个方面,包括语言风格、行为风格、性格特征、习语、背景故事等。数据集的构建需要广泛的文学创造力、脚本汇编和角色研究,确保生成的语言不仅符合角色的个性和特征,而且以适当的方式与用户互动[Wang2023b]。
为了丰富智体的多样性,设置几个后处理模块,包括动作验证模块和冲突识别模块。动作验证模块是环境交互模块的一部分,用于检查生成的动作是否能在游戏中正确执行。相反,在认知架构中,冲突识别模块检查决策和对话是否包含与角色关系、个性和游戏世界观的冲突。当检测到此类冲突时,模块将采取诸如拒绝结果或重写结果之类的操作,防止智体不符合角色特点。

















 3497
3497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









