









23年10月来自北航等高校的论文“RoleLLM: Benchmarking, Eliciting, And Enhancing Role-playing Abilities Of Large Language Models“。
大语言模型(LLM)的出现为角色扮演等复杂任务铺平了道路,角色扮演使模型能够模仿各种角色来增强用户交互。然而,最先进LLM的闭源性质及其通用训练限制了角色扮演优化。本文介绍RoleLLM,一个做基准测试、引出和增强LLM中角色扮演能力的框架。RoleLLM包括四个阶段:(1)Role Profile Construction的100个角色;(2) Context-Based Instruction Generation(Context Instruction)的特定角色知识提取;(3)Role Prompting用GPT(RoleGPT)进行说话风格模仿;以及(4)Role-Conditioned Instruction Tuning(RoCIT)和角色定制用于微调开源模型。通过Context Instruction和RoleGPT,作者创建RoleBench,一个系统化、细粒度的角色扮演基准数据集,共有168093个样本。此外,RoleBench上的RoCIT生成RoleLLaMA(英语)和RoleGLM(中文),显著增强了角色扮演能力,甚至实现了与RoleGPT(使用GPT-4)相当的结果。
RoleLLM如下图所示。

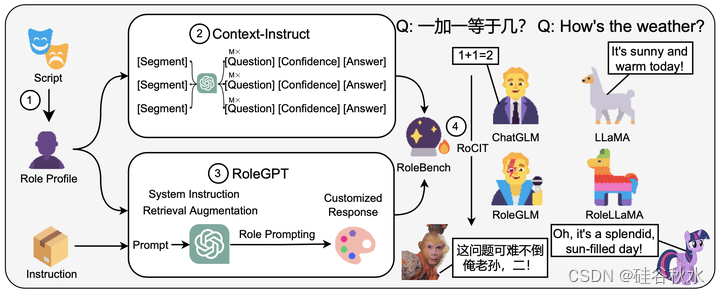
在实验中,用三个基于Rouge-L(Lin,2004)的指标来评估说话风格模仿、回答准确性和特定角色知识捕获的模型。基于GPT的评估器也被使用,与AlpacaEval(Li,2023c)一致。主要发现是:(1)对话工程比提示工程更受RoleGPT评估者的青睐;(2) RoleBench显著提高了模特的角色扮演能力,甚至在某些情况下与RoleGPT取得了有竞争力的成绩;(3) RoleLLaMA在说话风格模仿和对未见过角色的准确性方面表现出强大的泛化能力,只需要角色描述和流行语(catchphrases)即可进行有效的适配,允许用户无缝定制新角色;(4) 基于系统指令的方法在角色定制的有效性和上下文效率方面优于检索增强;(5) Context Instruction显著增强了模型对其角色的了解,用含噪的角色配置文件时优于基于检索增强的方法。
方法
先介绍角色扮演方法。
设计原则
说话风格模仿。为了模仿特定角色的说话风格,模型对指令的反应应符合设计的两个标准:(1)词汇一致性:模型的反应应包含角色常用的流行语或惯用语,确保词汇与角色独特的语言风格相一致;(2) 对话保真度:该模型应该产生的反应不仅在上下文上合适,而且在风格上与角色的示例对话相似。例如,海盗角色的词汇一致性包括频繁使用“aweigh”等航海术语以及“matey”或“ahoy”等钟爱的短语。此外,对话的忠实性应该捕捉到角色独特的句法和语气(例如,口语表达、粗鲁的说话方式以及唤起冒险和不法的语气)。
角色特定知识和记忆注入。角色扮演的另一个关键方面是融入特定角色的知识和情节记忆。有考虑两类不同的知识:(1)基于脚本的知识,它涉及脚本中记录的明确细节,如详细的角色背景、情节记忆和角色经历的特定事件;(2) 脚本不可知知识,包括角色可能拥有的一般知识或专业知识。例如,当扮演钢铁侠时,LLM应包含基于脚本的知识(例如,被囚禁在洞穴中时,托尼·斯塔克创作第一套钢铁侠套装)和与企业家相关的脚本不可知知识(例如商业头脑、领导素质和技术专业知识)。
RoleGPT
考虑到微调的限制,根据OpenAI的Chat Markup Language(ChatML)指南,为角色扮演,定制GPT通常包括提示,如零样本自定义指令和少样本提示工程(即上下文学习)(Brown2020;Dong2023)。然而,对于上下文学习能力换取对话历史建模(Fu,2022)的ChatGPT和GPT-4来说,传统的少样本提示工程不足以充分激发角色扮演能力。
具体来说,首先用审核的GPT-4生成字符描述和流行语,作为自定义指令(即系统指令)的核心。然后,包括一个总体角色扮演任务指令,如“请像[role_name]一样说话”,并用BM25(Robertson&Zaragoza,2009)检索角色简介中的前5对相关对话作为少样本演示。通过这样做,RoleGPT的回答可以捕捉角色的说话风格,并包括一些特定角色的知识。然而,profile中的稀疏性和噪声限制检索增强进行知识发现的有效性。
Context-Instruct
为了提高合成指令数据集中特定角色知识的密度,引入上下文指令来提取长文本知识和指令数据生成。角色专用指令数据生成包括三个步骤:(1)分割角色档案;(2)问题 生成-置信度-答案三元组的候选;以及(3)对低质量数据进行滤波和后处理。
角色档案分割。考虑到GPT的上下文大小有限,仔细地将角色配置文件划分为更易于管理的部分。角色简介包括(a)角色描述和流行语,以及(b)结构化对话。(a)用于获得与脚本无关的指令,而(b)用于获得基于脚本的指令。
指令和响应生成。在特定角色指令数据生成候选的过程中,考虑三个要素:给定片段(即上下文)相关的问题(Q)、相应的答案(a)和基本原理的一个置信度得分(C)。LLM用于为每个角色和片段生成这些三元组。初步试验表明,在没有置信度得分的情况下,生成QA对会造成质量较低的问题,通常由于先验知识假设导致基于脚本的指令出现不完整性,或者由于缺乏上下文脚本-不可知指令造成幻觉。为了解决这一问题,受(Lin2022)和(Xiong2023)的启发,该模型会被提示生成基本原理的一个置信度得分,评估问题的完整性或真实性。提示模板包括角色描述、流行语、少样本示例以及用于模仿说话风格和生成三元组的任务指令。生成过程通过多次模型运行为每个角色生成至少400个候选。
数据过滤和后处理。滤波过程包括基于置信度分数的过滤和重复数据消除,确保数据质量和多样性。
RoCIT
有两种类型的增强数据:一种用于RoleGPT生成的通用域指令,另一种用于上下文指令生成的角色特定指令。对这些数据的微调不仅改善模型的说话风格,而且将特定角色的知识嵌入到权重中。将其应用于英语的LLaMA和汉语的ChatGLM2,可获得RoleLLaMA与RoleGLM。与普通监督微调相比,采用角色为条件微调,该微调集成了角色定制的特定策略,包括系统指令和检索增强。
系统指令定制。在RoCIT中,预置系统指令与RoleGPT中的角色名称、描述、流行语和角色扮演任务指令一起做输入。继Alpaca(Taori et al.,2023)之后,RoleLLaMA的chat markup language是“###Instruction:\n{系统指令}\n###Input:\n{用户输入}\n###Response:\n{model Response}</s]”;对于RoleGLM,翻译成中文。只监督蓝色显示的响应和特殊tokens。在推理过程中,用户可以通过系统指令轻松修改LLM的角色,与检索增强相比,最大限度地减少上下文窗的开销。
RoleBench
下面介绍基准。
数据
RoleBench数据集构建包括五个步骤:(1)角色的选择;(2) 角色profile的构建;(3) 一般指令的抽样;(4) 生成原始RoleBench数据;以及(5)RoleBench数据集的清理。
数据分析
用GPT-4 API获得RoleBench-general-en(英文)和RoleBenchgeneral-zh(中文)。Context-Instruction基于GPT-3.5 API生成RoleBench-specific-en和RoleBench-specific-zh。角色选择、描述和流行语生成,都用GPT-4 API执行。
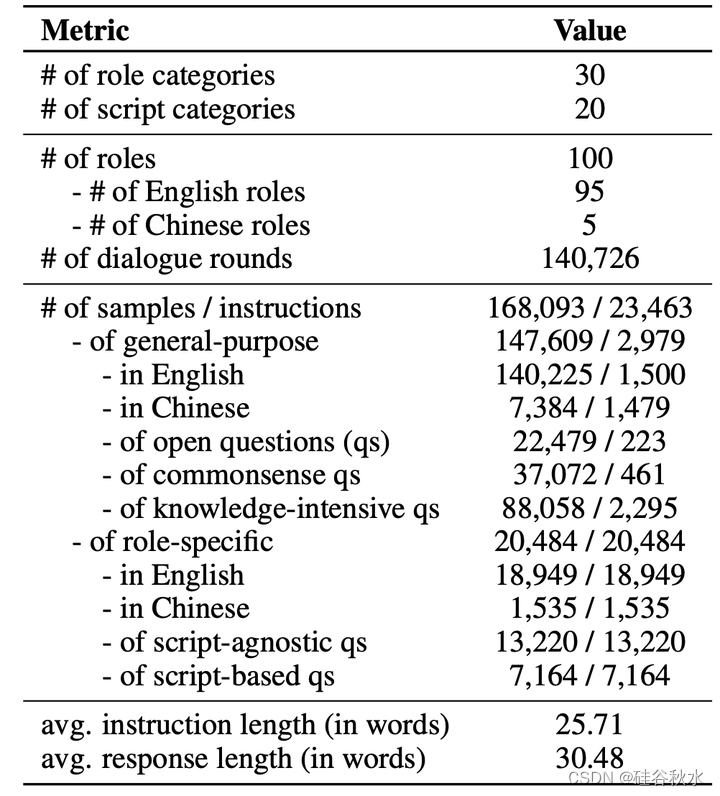
统计和质量。下表1提供RoleBench的基本统计数据。分别从一般子集和特定角色子集中随机抽取100个实例来评估RoleBench的质量,然后请专家标注从三个方面评估质量。下表2的结果表明,大多数显得高质量。

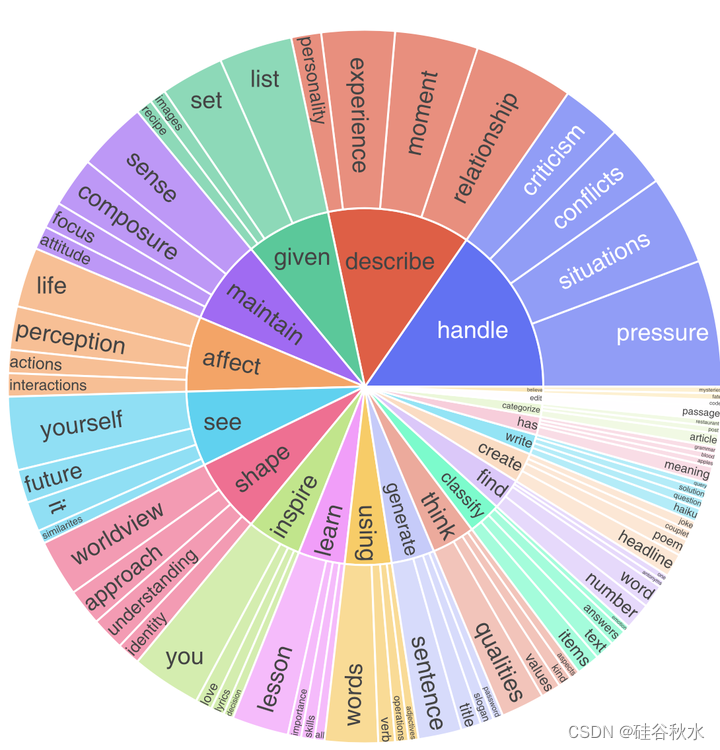
多样性。分析RoleBench的全面性和多样性。下图显示RoleBench-en指令的动名词结构,其中描述了前10个动词(内圈)及其前4个直接名词宾语(外圈),占指令的5.6%。
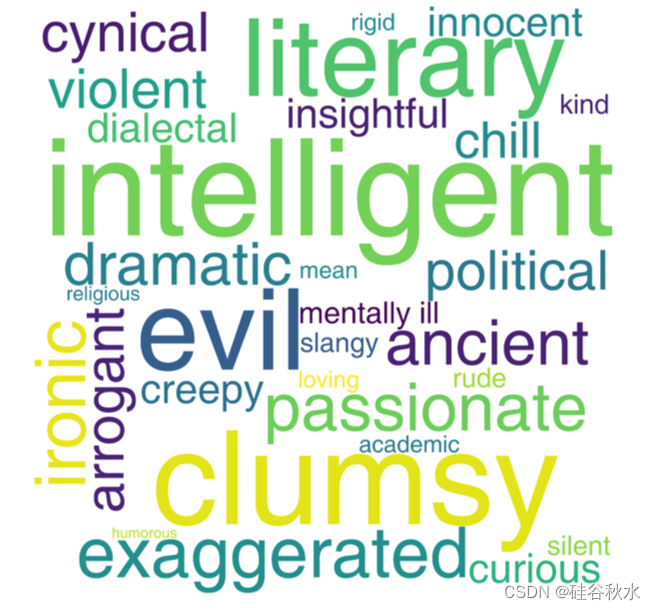
此外,将RoleBench角色分类为多个类,并构建一个单词云(如图所示——来显示它们的多样性。
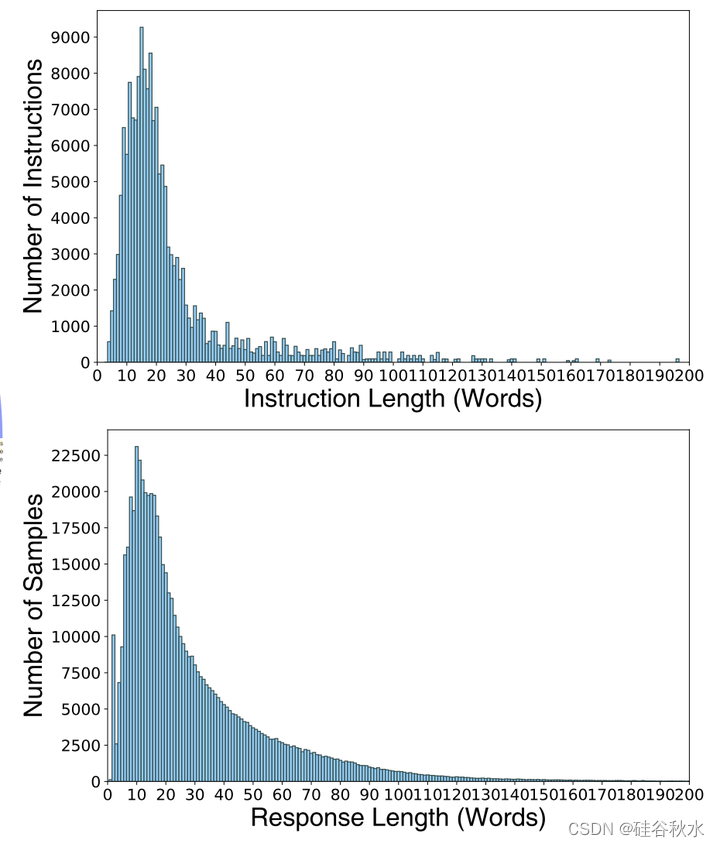
指令和响应的长度分布如图所示。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









