









23年11月来自日本京都大学、欧姆龙集团SINIC X 公司和东京大学的论文“Vision-Language Interpreter for Robot Task Planning“。
大语言模型(LLM)正在加速语言引导机器人规划器的发展。同时,符号规划器提供了可解释性的优势。本文提出了一个新的任务来桥接这两个趋势,即多模态规划问题规范。其目的是生成问题描述(PD),这是规划器用来查找规划的机器可读文件。从语言指令和场景观察中生成PD,可以在语言引导的框架中驱动符号规划器。本文提出了一种视觉语言解释器(ViLaIn),这是一种新的建模框架。ViLaIn可以通过错误消息细化生成的PD。生成的PD用最先进的LLM和来自符号规划器的视觉语言做反馈。目标是回答域知识问题:ViLaIn和符号规划器如何准确地生成有效的机器人规划?为了评估ViLaIn,引入了一种数据集,称为问题描述生成(ProDG)数据集。该框架采用四个重新提示(re-prompting)评估指标进行评估。实验结果表明,ViLaIn生成语法正确问题的准确率超过99%,有效规划的准确率超过58%。
自然语言是给机器人非专家直观指令的一种有前途界面[1]-[3]。早期的研究已经用递归神经网络[4][5]将抽象的语言指令映射到机器人的表示[1][6][7]。这里,语言指令表示期望的目标条件。最近的研究用大语言模型[8]-[10]直接根据指令[11]-[14]生成机器人规划。这些语言指导的规划器在没有经过训练的情况下,使用少样本提示来解决任务[15]。规划是完成任务的一系列离散象征性动作(例如,选择(a)和放置(a,b))。目标是在提高可解释性方面加强以语言为指导的规划器。可解释性对于获得用户的信任和深入了解机器人的决策过程至关重要[16]。例如,通过解释来识别故障原因,从而不断提高整体性能。
机器人任务规划传统上使用符号规划来解决[17]。现代符号规划器用规划域定义语言(Planning Domain Definition Language,PDDL)来描述规划问题。在PDDL中,规划问题定义为两个部分:定义变量和动作状态的域,以及定义感兴趣目标、其初始状态和期望目标状态的问题描述(PD)[18][19]。域和问题是规划器寻找最佳规划的输入,这是一系列象征性动作。
符号规划器提供了几个好处。域和问题描述是可读的,尤其直观地选择变量名。此外,所获得的规划保证在逻辑上是正确的。考虑到这些优势,将符号规划和语言引导规划相结合是实现可解释机器人的一个很有前途的研究方向。为此,作者提出了从自然语言指令生成PD。由于语言指令仅表示目标条件,因此需要关于环境的附加信息来生成初始状态(例如,表示当前环境的图像)。这些附加信息称为场景观测。
本文处理多模态规划问题规范任务,这是一项将语言指令和场景观测转化为逻辑和语义正确的PD任务。PD必须由符号规划器执行。本文研究在没有额外训练的情况下,如何用最先进的LLM[9]和视觉-语言模型[20][21]准确地生成这样的PD。
视觉-语言解释器(ViLaIn)框架如图所示。ViLaIn由三个模块组成,这些模块生成PD的每个部分。完整的PD连接这些部件来组装。此外,ViLaIn可以通过符号规划器的错误反馈来细化生成的PD。规划器用一对生成的PD和域描述来查找规划。本文用最先进的符号规划器Fast Downward[22]。
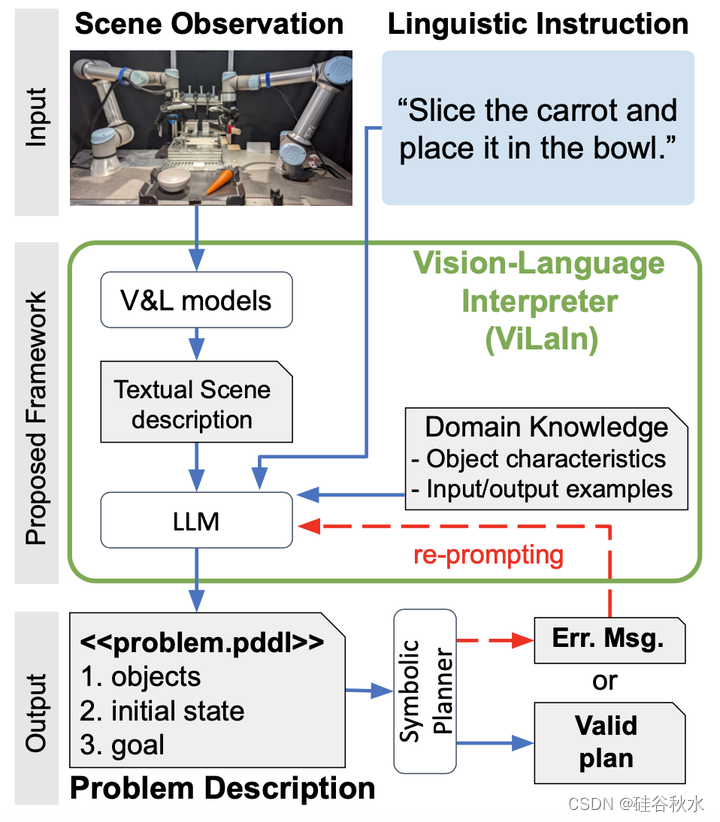
问题描述生成(ProDG)数据集包括语言指令、场景观测以及域和问题描述。PDDL[19]中有相关说明。该数据集涵盖三个领域:烹饪作为一个实用的机器人领域,块世界(blocks world)和河内塔(tower of Hanoi)作为经典的规划领域。
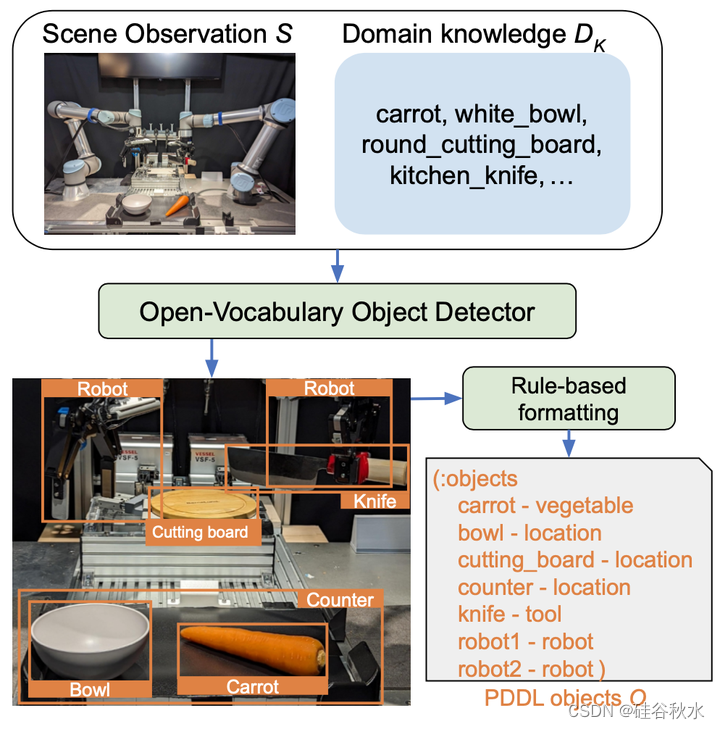
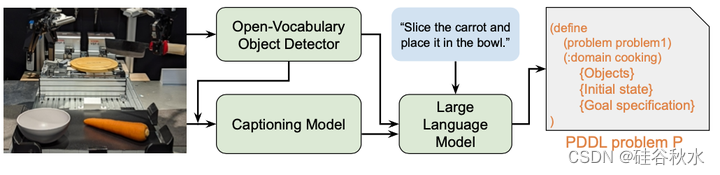
专注多模态规划问题规范,这是一项连接语言引导规划和符号规划的新任务。输入是四元组(L、S、DD、DK);语言指令L、场景观测S、领域描述DD和领域知识DK。L是描述任务的单词序列。S是描述环境初始状态的RGB图像。DD定义了所有问题共同的部分:目标类型(例如位置和工具)、谓词(例如at和clear)以及符号操作(例如slice和pick)。DK提供关于每个问题的更具体的信息来支持DD,例如目标特征(例如,盘子是圆形的,柜台是黑色的)和实际输入/输出示例。注意,DK中的示例使用了DD中定义的目标类型和谓词。
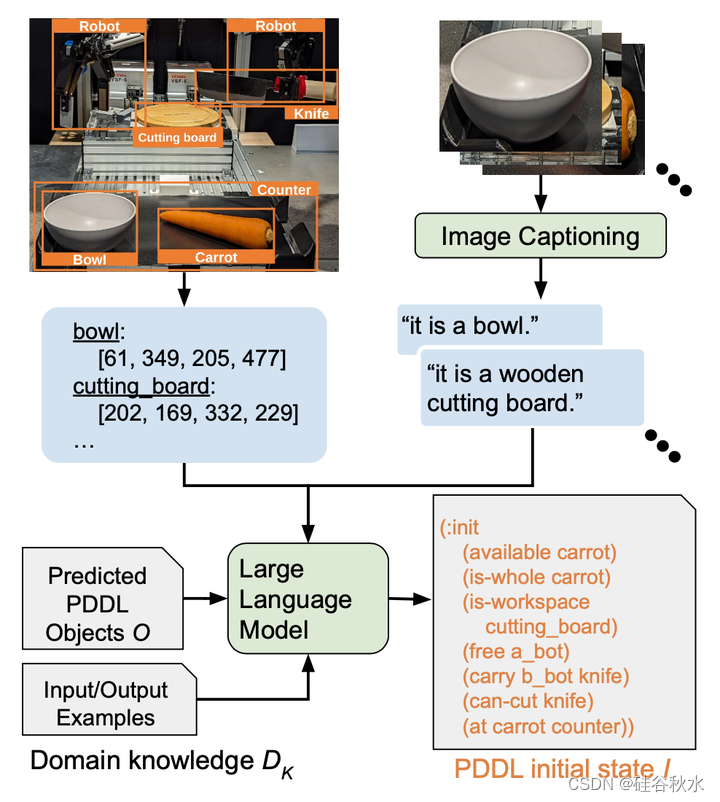
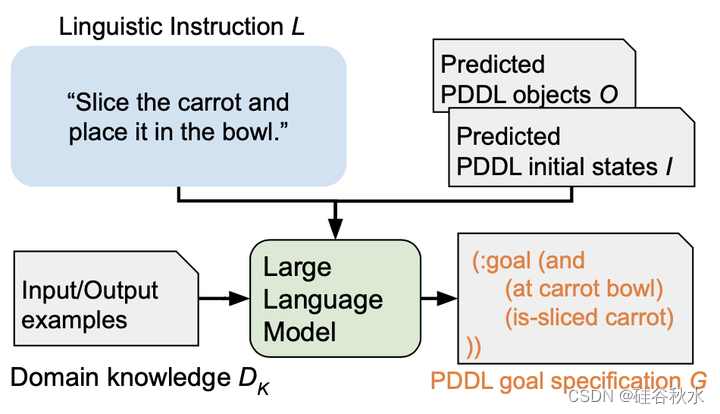
输出是由(O,I,G)组成的一个任务描述P:目标O、初始状态I和目标规范G。O由完成任务所需的目标组成(例如,胡萝卜和刀子)。I由一组表示环境初始状态的命题组成。(例如,在胡萝卜柜台)。一个命题是给谓词提供论据而形成的。例如,用(a1,a2)=(胡萝卜,切板)提供谓词(在?a1?a2)形成命题(在胡萝卜切板上),意思是“胡萝卜在切板”。G由一组表示环境期望目标条件的命题组成。例如,(和(在胡萝卜碗中)(是切好的胡萝卜))表示“胡萝卜应该切好,并且应该在碗中”的目标条件。按照之前工作[25][27],P和DD用PDDL[19]写。用PDDL(例如,PDDL目标)指代O、I或G。任务的目标是获得一个函数M:(L,S,DD,DK)→(O,I,G)。P必须是机器可读的,并且可以由符号规划器执行。
ViLaIn由三个模块组成:感知目标估计器、初始状态估计器和任务目标估计器,各个模块结构分别如下图所示。
规划器用生成的PD来查找规划。在以下两种情况下,规划可能会失败。一种是当PD在语法上不正确时。在O中生成具有未定义目标的命题或在DD中生成未定义谓词的命题会导致这样的PD。例如,创建(在cucumber柜台),但cucumber未在O中列出。另一种是当生成的O从生成的I不可达时。矛盾的命题产生了这样的PD,例如,命题(在红块-蓝块上)和相反的命题(在蓝块-红块上)都存在于I中。在这两种情况下,规划器都会停止规划并返回一条错误消息,这是完善错误部分的线索。如果系统通过错误消息自动细化PD,非常理想。
当规划失败时,ViLaIn会创建一个提示并重新提示GPT-4来细化PD。称为纠正性重新提示(Corrective Re-prompting,CR),遵循[12]。如图显示带有CR的ViLaIn。提示包括DK中的输入/输出示例、当前输入(L和S)、生成的问题P和错误消息。
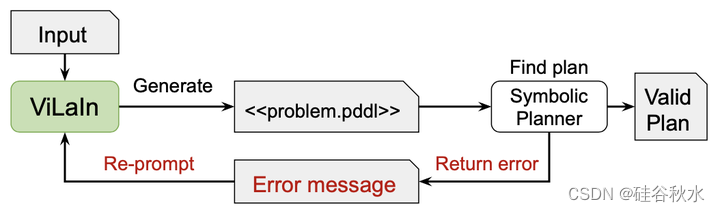
思维链提示:用思维链(CoT)提示[41]-[43]来进一步加强CR。CoT是一种通过LLM解决复杂推理任务的技术。CoT在生成最终输出之前引入了一个中间推理步骤。使用CoT,GPT-4会生成错误消息的解释,并带有提示模板“您认为PDDL问题的哪一部分导致了此错误?”。然后GPT-4将生成带有解释的细化问题。具有CoT的CR可以根据需要经常重复,直到规划器返回错误消息。注意,只有当规划器返回错误消息时,ViLaIn才使用CoT执行CR。
ProDG数据集由三个领域组成:烹饪、区块世界(Blocks world)和河内塔(Hanoi)。烹饪是一项简单的制作沙拉任务。规划比其他两个领域更简单,因为它只考虑将蔬菜切片并放入碗中。烹饪动作应该由安装在环境两侧的两个机械臂执行。在O中,左右机械臂分别命名为a机器人和b机器人。这个域比其他域处理更多种类的目标。G表示蔬菜的状态和位置。
区块世界是一个经典的规划领域[44]。与烹饪相比,出现的目标类型更少,但需要更长的范围规划。每个问题用七个没有重复的彩色块。机器人手臂一开始并不总是抓东西。G指定了块的关系。
Hanoi是一个经典的规划域[45]。与区块世界类似,需要用比烹饪领域更少的目标类型进行更长范围的规划。用十个六种颜色的圆盘和三个钉子。相同颜色的圆盘按宽度增加的顺序以数字命名(例如,蓝色盘1和蓝色盘2)。这三个钉子按从左到右的数字命名(例如,钉1、钉2和钉3)。I和G指定圆盘的位置。完成此任务需要正确识别圆盘大小,因为L只指示任务的规则,“下面是更大的圆盘”,但没有提到具体的目标。
每个域都有一个域描述和十个PD。下表显示了域描述中的目标类型、谓词和操作。每个问题都有一个语言指导和一个场景观测。

如图显示了语言指令L和场景观察S的例子。对于Hanoi域,L在所有问题中都是相同的。其旨在研究ViLaIn是否可以基于O和I来生成不同的G。烹饪域的描述是从头开始创建的,而Blocksworld和Hanoi域的描述基于pddlgym[46]中的PDDL文件创建。所有创建的PD在语法上都是正确的,并且用Fast Downward[22]和VAL(一种规划验证软件)的解决方案。

ViLaIn使用不同的模块生成PD的各个部分。如果一个模块可以一次生成整个问题,这将大大简化系统。这里考虑ViLaIn的一个变型,它一次生成整个PD,如图所示。此模型称为ViLaInwhole。生成与原始模型一样在少样本提示的情况下执行的。
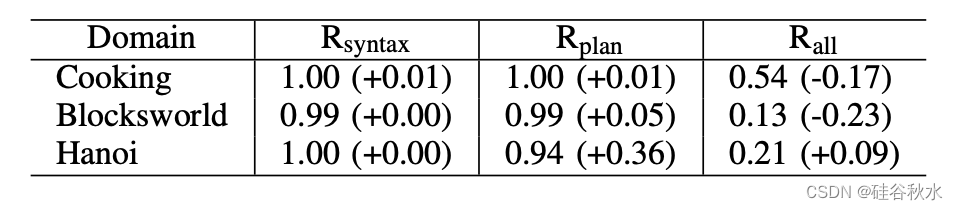
下表显示了Rsyntax、Rplan和Rall的结果。括号内的值表示ViLaIn的增益。在烹饪和Blocksworld域,ViLaInwhole略微提高了Rplan,但恶化了Rall。这意味着用三个模块对这些领域更有效。在Hanoi域中,ViLaInwhole在Rplan和Rall方面都优于ViLaIn。
下表显示了烹饪领域的结果。第一行与上表中的结果相同。首先,仅用CoT进行一次CR(第一行)会略微降低Rplan和Rall,这意味着重复CR是有效的。接下来,去除CoT(第三行)会使所有分数恶化。这表明CoT引入的中间推理步骤对性能有很大影响。最后,去除CR(第四行)会显著降低分数。该模型往往会产生幻觉[47],例如具有未定义目标的命题,例如,I中(在cucumber柜台),其中O没有定义cucumber。发现CR有效地细化了这些不正确的命题,并使PD保持一致。

















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









