









24年2月复旦大学和上海AI实验室的论文“LongWanjuan: Towards Systematic Measurement for Long Text Quality”。
训练数据的质量对于增强基础模型的长文本能力至关重要。尽管目前人们正在努力通过启发式规则和基于数据多样性和难度的评估来提高数据质量,但仍然缺乏专门用于评估长文本的系统方法。为了解决这一问题,评估三个基本语言维度来系统地衡量长文本的质量:连贯性、凝聚性和复杂性。从上述三个维度考虑,采取一套旨在评估长文本质量的指标,涵盖统计指标和基于预训练语言模型的指标。利用这些指标,构建LongWanjuan双语数据集,专门用于增强长文本任务的语言模型训练,拥有超过 1600 亿个tokens。在LongWanjuan中,将长文本分为整体、聚合型和混乱的类型,从而可以对长文本质量进行详细分析。此外,设计一种数据混合配方,可以策略性地平衡LongWanjuan中不同类型的长文本,从而显著提高长文本任务的模型性能。
代码和数据集开源下载 https://github.com/OpenLMLab/LongWanjuan
方法介绍
有效地处理长文本是语言模型的一项关键能力,最近已成为研究的焦点(Liu et al., 2023b; Peng et al., 2023; Pal et al., 2023; Han et al., 2023; Chen et al., 2023)。诸如长文档摘要(Zhong et al., 2021)、长文档问答(Dasigi et al., 2021)、存储库级代码任务(Liu et al., 2023a)和检索增强生成(Xu et al., 2023)等任务通常涉及处理数千甚至数万个tokens。
数据质量对于基础模型的长文本能力至关重要(Zha et al., 2023; Xiong et al., 2023; Rozière et al., 2023)。人们已经做出了努力来提高数据质量。一些方法采用启发式规则,例如重复数据删除和删除过短的数据条目(Soboleva,2023;Penedo,2023)。此外,其他一些方法基于预训练的语言模型考虑数据多样性和困惑度(Tirumala,2023;Marion,2023)。然而,这些过滤规则是针对一般训练数据设计的,没有考虑到长文本的独特特征。
为了系统地评估长文本的质量,遵循语言学基本原理,从三个维度进行评估:连贯性(Wang and Guo,2014)、凝聚性(Halliday and Hasan,2014;Carrell,1982)和复杂性(Pallotti,2015),如图所示。
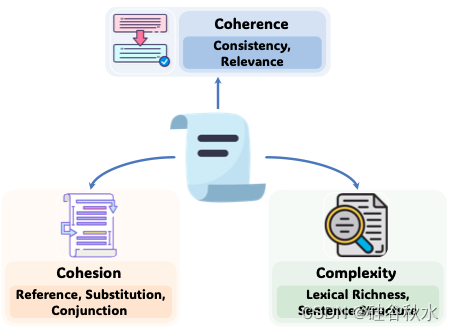
鉴于长文本通常包含更广泛的内容,因此需要提升这些特征的水平,以便有效地传达信息和参与讨论。连贯性衡量整个文本的整体一致性和清晰度。凝聚性衡量句子或文本章节之间的联系强度。复杂性评估文本中的语言复杂程度。从这三个基本维度出发,提出一套指标来定量分析长文本的质量。这些指标涵盖统计和基于预训练模型的方法,具有很强的可解释性。
下表中提供长文本三个质量维度的示例,说明这些维度的高级和低级。突出强调体现每个维度特定特征的关键术语。
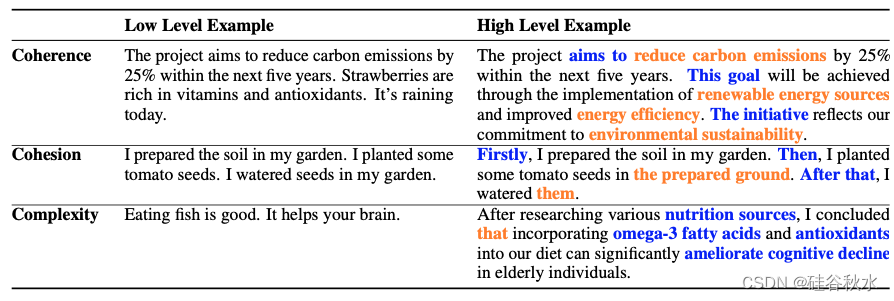
为了衡量长文本的连贯性,评估文本的先前部分对理解后续部分的贡献程度。连贯的文本应该更容易根据其前面的上下文预测其后面的内容。例如,在预测下面的蓝色文本时,如果提供前面的文本,则更容易做出正确的预测。

通过比较较长上下文的预测准确度和较短上下文的预测准确度以及这两个上下文之间的差异来评估长文本的连贯性。具体而言,使用由θ参数化的预训练因果语言模型,采用以下三个指标来评估长文本的连贯性:
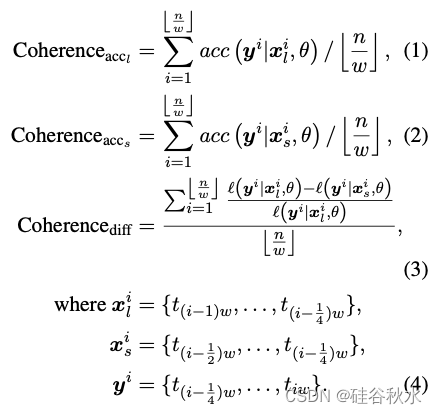
其中acc(y|x, θ)和l(y|x, θ)表示模型在给定提示x(由θ参数化)的情况下生成y的平均top-1预测准确度和负对数似然损失。 Coherence accl 和 Coherence accs 分别表示模型在较长和较短的前置文本中的 top-1 预测准确率,而 Coherence diff 表示在使用较长上下文与较短上下文时模型性能的比例提升。用大小为 w 的滑动窗口处理长文本,避免超出语言模型的处理能力,在实践中将 w 设置为 4096。
分析文本中连接词和代词的密度以及相邻句子之间的关系来定量测量凝聚性。连接词在句子和段落中连接单词、句子或想法方面起着关键作用。代词作为名词或名词短语的替代词,在避免不必要的重复的同时,保留对前面提到的特定实体引用。
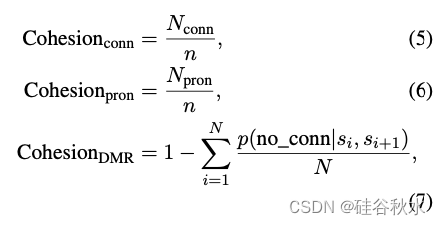
其中 Nconn 和 Npron 分别表示文本中的连接词和代词的数量。
这个文本 t 由 N + 1 个句子组成,si 表示文本中的第 i 个句子。术语 p(no_conn|si, si+1) 表示使用分布式标记表示 (DMR) (Ru et al., 2023) 确定句子 si 和 si+1 不相关的概率。
复杂性由词汇和段落估计:
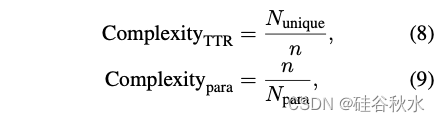
其中 Nunique 表示文本中唯一tokens的数量,用于计算类型-Token 比率 (TTR) (Richards, 1987)。Npara 表示文本中的段落数,用于确定平均段落长度。
基于这三个维度的特征,将预训练数据集中的长文本分为三类:整体长文本,包括书籍、学术论文、报告、小说和访谈等完整作品;聚合长文本,由按主题相关的短文本或碎片文本(如大量列表或表格)组成;混乱长文本,其特点是无意义的内容,例如乱码数据。基于这些分类,手动注释来自 SlimPajama(Soboleva,2023)和 Wanjuan(He,2023)的 200 个样本的验证集,验证提出的指标与人类判断之间的相关性。
LongWanjuan
基于前面讨论的分析和指标,引入双语长文本数据集 LongWanjuan。构建数据集的流程如图所示。
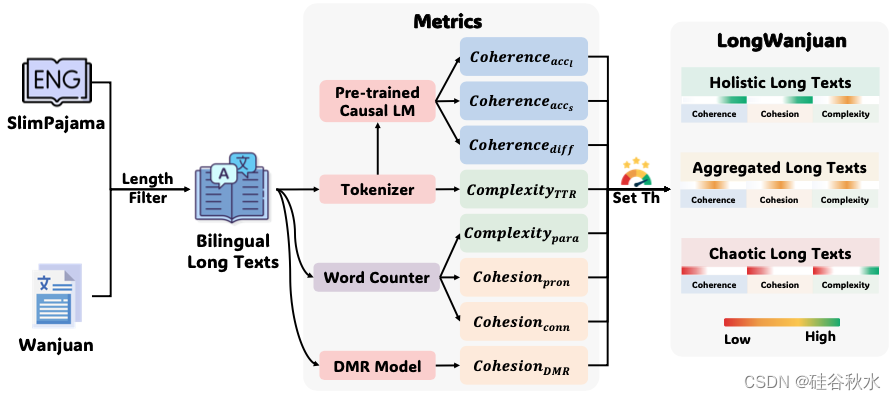
鉴于 SlimPajama (Soboleva et al., 2023) 语料库的大部分内容为英文,用 Wanjuan (He et al., 2023) 数据集中的中文文本对其进行丰富。首先,从 SlimPajama 和 Wanjuan 数据集中提取超过 32K 字节的数据条目,作为构建数据集的起点。
随后,用上面指标评估每个数据条目。具体来说,首先使用 InternLM2 token化器 (Team, 2023) 对数据进行token化,然后计算 ComplexityTTR。使用 InternLM2-7B 进一步处理token化结果以获得连贯性分数,包括 Coherence accl、Coherence accs 和 Coherence diff。分别用 NLTK(Bird & Loper,2004)和 LTP(Che,2021)对英文和中文句子进行切分。然后,将这些句子输入 DMR 模型得出 Cohesion DMR 分数。Cohesion conn、Cohesion pron 和 Complexity para 指标是通过直接的字数统计得出的。
使用这些指标对每个数据条目进行评分后,建立阈值,将数据分类为整体长文本、聚合长文本和混乱长文本。在此过程中,仅需检查阈值两侧的文本是否属于不同的类别。如图显示基于 Cohesion conn 指标的 C4 域内文本的分布。如图所示,提出的指标不同范围内的文本表现出不同的特征,从而简化了阈值确定的过程。对于数据集中的每个域,可以根据该指标的分布提取大约30个数据样本,并确定不同类别文本之间的阈值。在此阶段,初步确定阈值以分离整体长文本。随后,在剩余的文本中,建立阈值以区分混乱长文本,将剩余文本归类为聚合长文本。
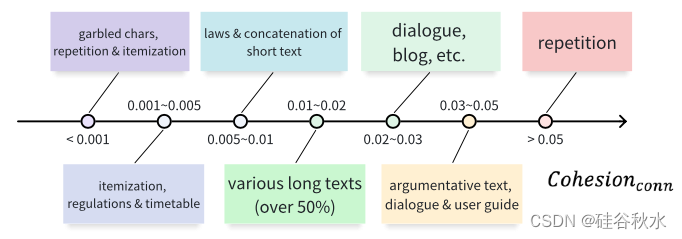
总体而言,整体长文本具有较高的连贯性和凝聚性,复杂性中等。与前者相比,聚合长文本的连贯性和凝聚性较低。混乱长文本的主要特征是其复杂性,异常高或低。
LongWanjuan数据集共包含 1606 亿个 tokens,由 InternLM2 token化器得到。其中,整体文本包含 1376 亿个 tokens,占数据集的 85.7%;聚合文本包含 218 亿个 tokens,占 13.6%;混沌文本包含 12 亿个 tokens,占 0.7%。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









