










LeRobot 的数据集系统提供了一个强大的框架,用于管理用于训练、评估和推理的机器人数据。本文介绍 LeRobot 数据集组件的架构和使用方法,重点介绍了机器人数据的存储、访问和处理方式。

概述
LeRobot 的数据集系统旨在高效处理多模态机器人数据,包括状态向量、图像/视频和任务描述。该系统支持本地和远程(Hugging Face Hub)数据集,并具备规范化、视频处理和图像转换等功能。
数据集结构
LeRobot 数据集采用结构化的文件层次结构进行组织,以促进高效的存储和访问模式。
关键组件
Data:包含存储在 Parquet 文件中的 episode 数据,按块组织(默认每块 1000 episodes)
Video:包含用于视觉数据的视频文件,按块和摄像头进行组织
MetaData:包含元数据文件:
info.json:数据集信息(特征、形状、FPS 等)
episodes.jsonl:剧集元数据(索引、时长、任务)
stats.json:用于规范化的数据集统计数据
tasks.jsonl:任务的自然语言描述
episodes_stats.jsonl:单集统计数据
核心数据集类
LeRobotDataset
处理机器人数据集的主要类。它提供以下功能:
- 从 Hugging Face Hub 或本地存储加载数据集
- 创建新的数据集用于录制
- 访问情节数据、视觉数据和元数据
- 将数据集推送至 Hugging Face Hub
Example: Loading a dataset
dataset = LeRobotDataset(
repo_id=“lerobot/example_dataset”,
episodes=[0, 1, 2], # Optional: load specific episodes only
image_transforms=transforms, # Optional: apply transformations to images
delta_timestamps={“observation.camera”: [-0.1, 0, 0.1]}, # Optional: temporal offsets
)
Example: Creating a new dataset
dataset = LeRobotDataset.create(
repo_id=“username/new_dataset”,
fps=30,
robot=robot, # Optional: get features from robot
use_videos=True, # Use videos instead of individual images
)
LeRobotDatasetMetadata
处理数据集元数据,包括:
- 特征描述(形状、类型、名称)
- 任务定义
- 事件信息
- 用于标准化的数据集统计数据
MultiLeRobotDataset
将多个LeRobot数据集实例合并为一个数据集:
- 支持使用来自多个数据集的数据进行训练
- 处理具有不同特征的数据集之间的兼容性
- 维护数据集标识符以便进行源跟踪
数据集创建和管理
工厂函数
make_dataset 工厂函数提供一种基于配置创建数据集的统一方法:
delta 时间戳
delta 时间戳允许在检索数据点时进行时间偏移,从而实现:
- 访问相对于当前时间步长的过去和未来帧
- 为依赖于历史的策略创建观察窗口
- 预测未来状态以进行规划
Example: Setup delta timestamps for different features
delta_timestamps = {
“observation.state”: [-0.1, -0.05, 0], # Past and current states
“observation.image”: [0], # Current image only
“action”: [0, 0.05, 0.1] # Current and future actions
}
数据集特征和模式
存储的各种数据格式如下
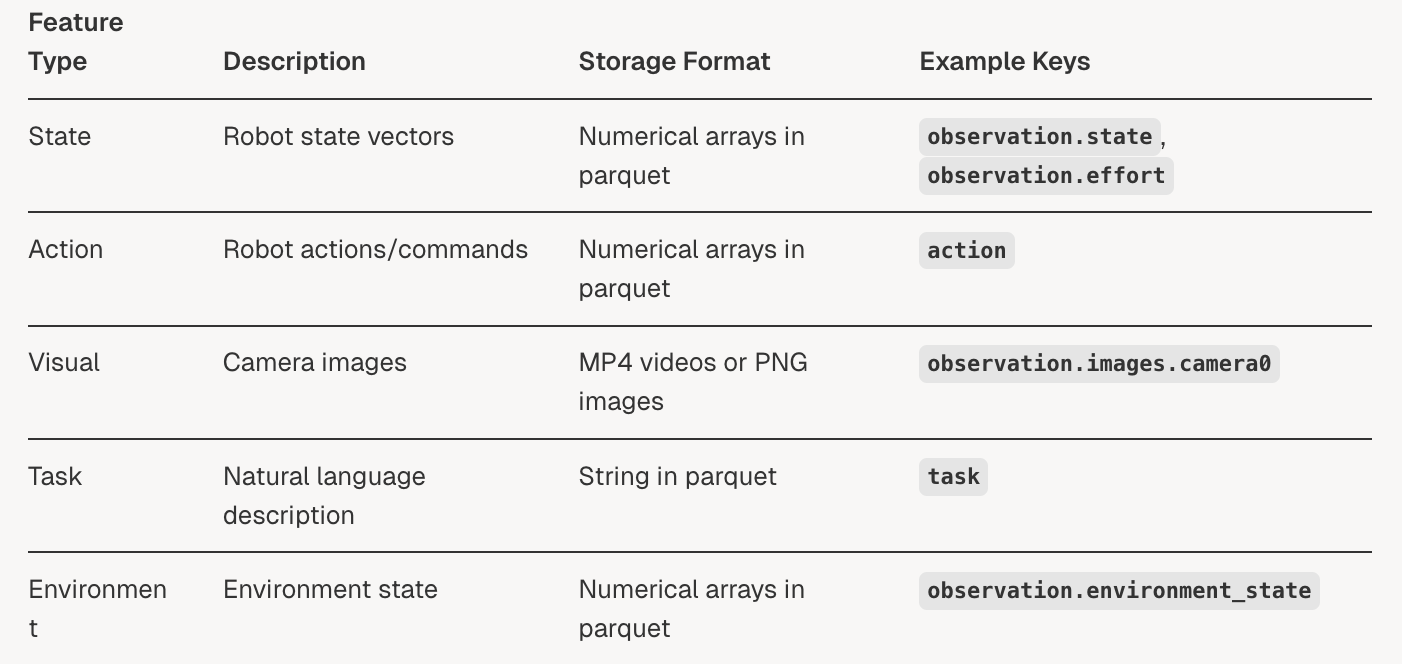
视频处理
对于包含视觉数据的数据集,LeRobot 提供高效的视频处理功能:
数据集记录
数据集系统支持高效记录新数据集:
- 使用 LeRobotDataset.create() 创建新数据集
- 使用 add_frame() 将数据帧添加到 episode 缓冲区
- 使用 save_episode() 完成并存储 episode
- 使用 push_to_hub() 推送至 Hugging Face Hub

数据集转换
对于使用旧版 LeRobot 创建的数据集,可以使用转换实用程序升级到最新格式:
python lerobot/common/datasets/v2/convert_dataset_v1_to_v2.py \
–repo-id username/dataset \
–single-task"Task description"
归一化和统计
LeRobot 数据集会跟踪用于归一化数据的统计数据:
- 每个特征的平均值和标准差
- 每集统计数据
- 与策略配合使用时自动归一化
统计数据在录制时计算,并存储在 stats.json 和 episodes_stats.jsonl 中。
下面介绍可视化 LeRobot 数据集的工具和方法。数据集可视化对于检查机器人数据、调试问题以及理解机器人行为至关重要。LeRobot 框架提供两种互补的可视化方法,允许用户检查数据集内容,包括摄像头图像、机器人状态、动作和其他指标。
可视化概览
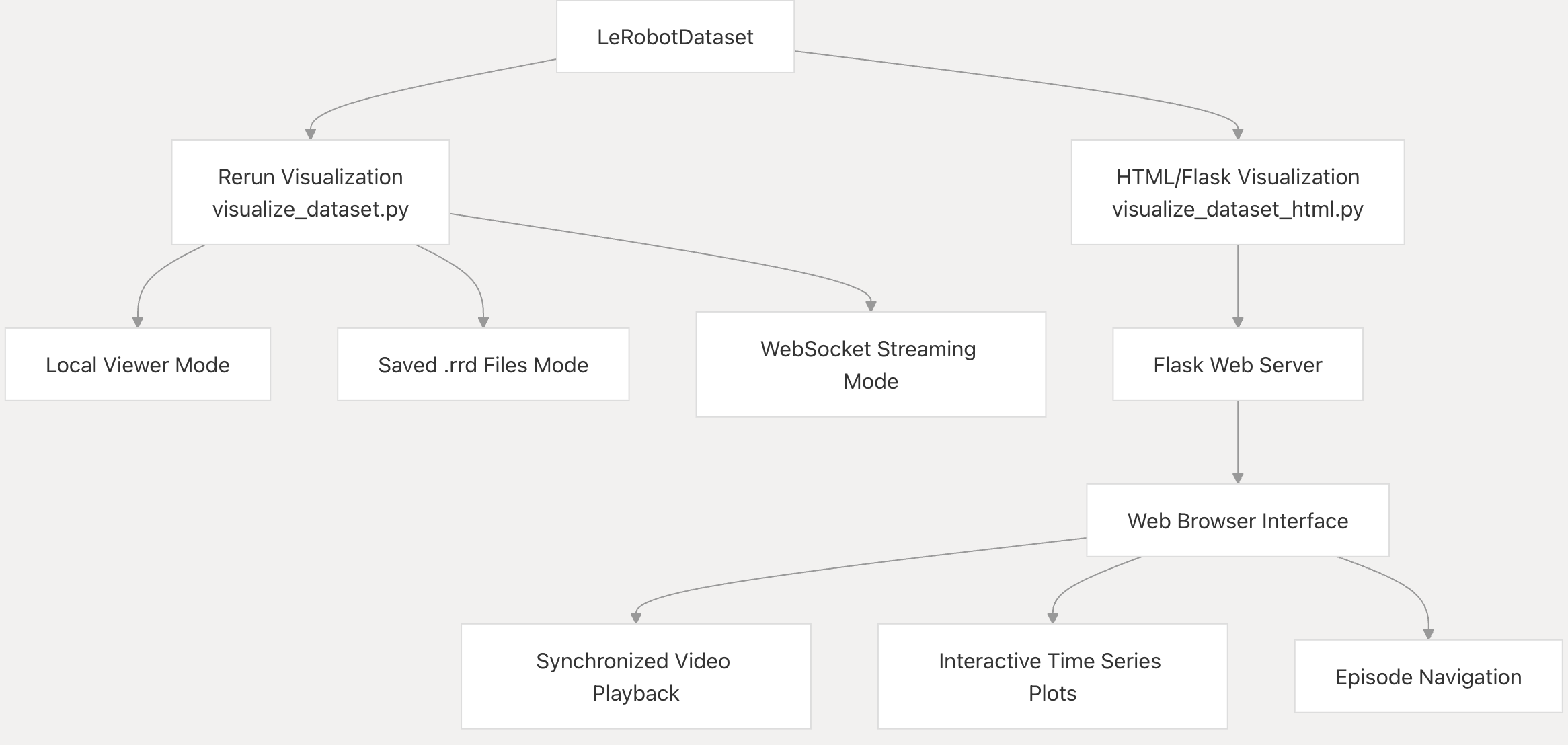
LeRobot 提供两种主要的可视化方法:
- Rerun 可视化:使用 Rerun 库进行技术可视化,用于详细检查数据集片段。
- HTML/Flask 可视化:基于 Web 的交互式可视化,提供同步视频播放和时间序列图表。
Rerun 可视化
Rerun 可视化工具 (visualize_dataset.py) 使用 Rerun 可视化库提供数据集片段的技术视图。它允许在分层时间轴中精确检查数据集内容。
使用 Rerun 可视化

使用模式
Rerun 可视化脚本支持三种使用模式:
- 本地模式:打开本地 Rerun 查看器窗口以显示数据集可视化效果。
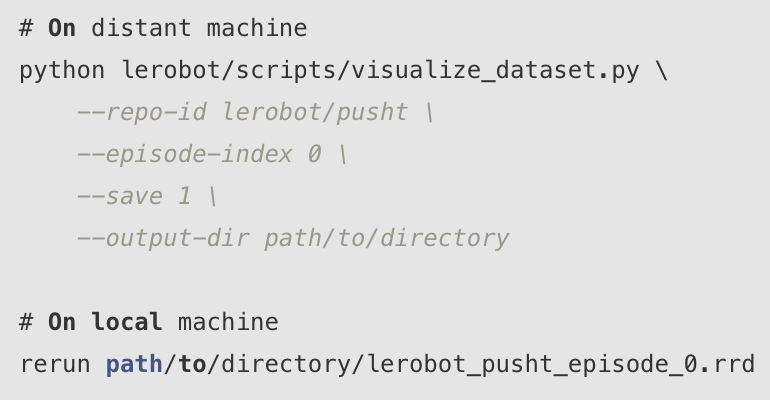
- 保存模式:将可视化数据保存为 .rrd 文件以供日后查看。
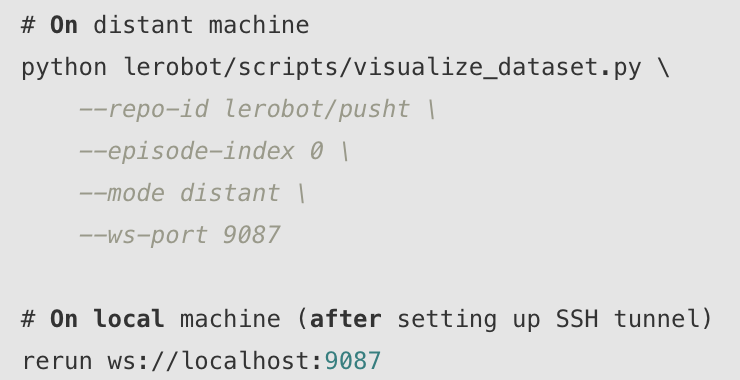
- 远程模式:创建一个 WebSocket 服务器,允许通过 Rerun 客户端进行远程连接。
命令行示例
本地可视化:
python lerobot/scripts/visualize_dataset.py \
–repo-id lerobot/pusht \
–episode-index0
保存模式(远程使用):
远程模式(流传播):
HTML/Flask 可视化
HTML/Flask 可视化工具 (visualize_dataset_html.py) 提供一个用户友好的 Web 界面,用于查看数据集片段。它包括同步视频播放、交互式时间序列图以及数据集元数据显示。
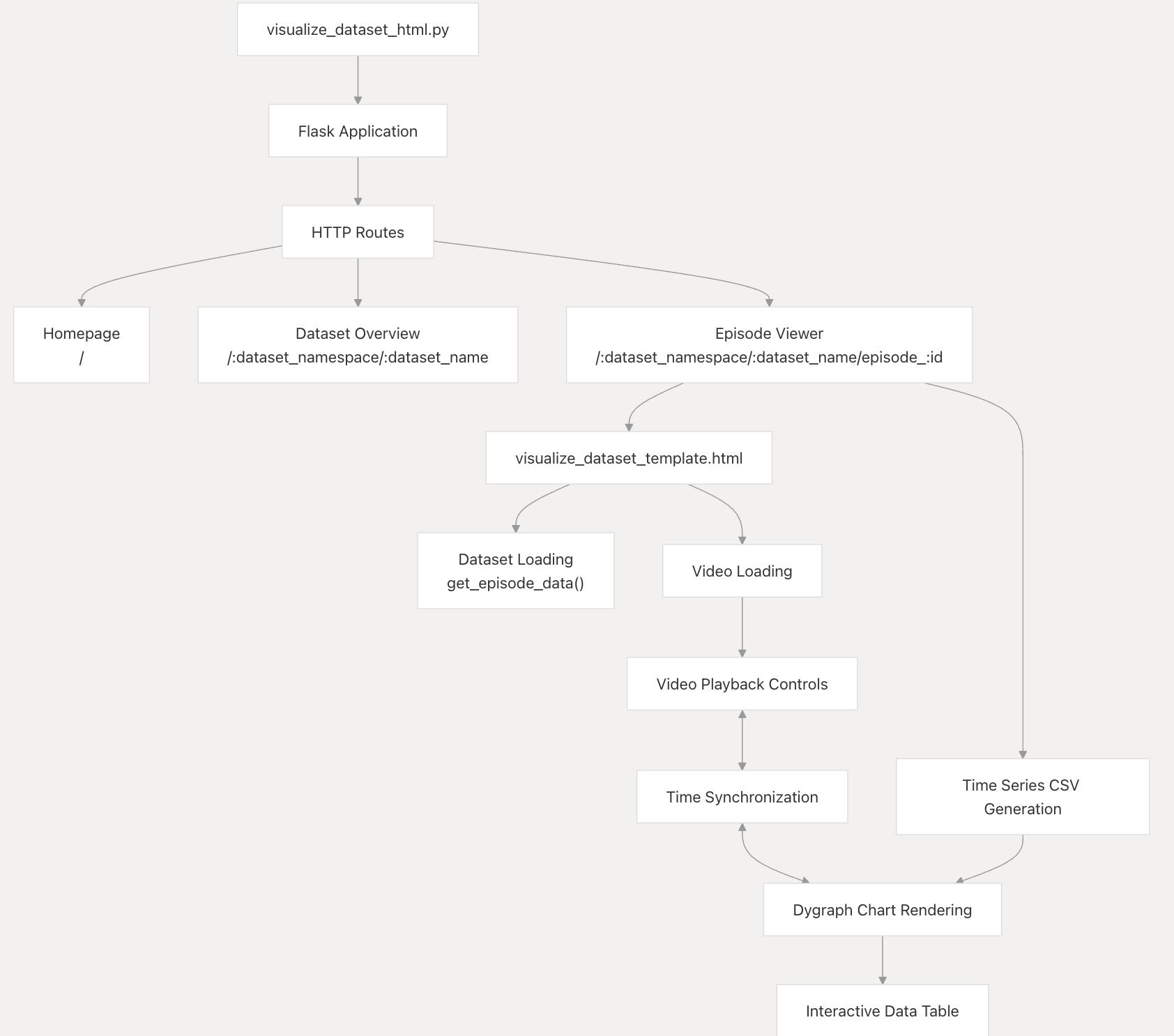
特征
HTML/Flask 可视化工具提供了一个交互式界面,其中包含以下几个主要功能:
- 数据集浏览器:在可用数据集和片段之间导航
- 同步视频回放:同步查看多个摄像机角度
- 时间序列图:机器人状态和动作数据的交互式图表
- 回放控件:播放、暂停、倒带和搜索控件
- 数据过滤:切换特定数据序列的可见性
- 可共享 URL:带有时间锚点的 URL,用于共享特定时刻
命令行示例
启动 Web 服务器:
python lerobot/scripts/visualize_dataset_html.py
–repo-id lerobot/pusht
选择特定 episodes:
python lerobot/scripts/visualize_dataset_html.py
–repo-id lerobot/pusht
–episodes 7 3 5 1 4
远程服务器访问:
在远程机器上
python lerobot/scripts/visualize_dataset_html.py
–repo-id lerobot/pusht
–host 0.0.0.0
在本地机器上(SSH tunnel)
ssh -L 9090:localhost:9090 username@distant-machine
然后在浏览器中打开 http://localhost:9090
可视化数据流
两种可视化系统处理数据集数据的方式类似,但在呈现方式上有所不同:

Web 界面组件
HTML/Flask 可视化界面包含以下关键组件:
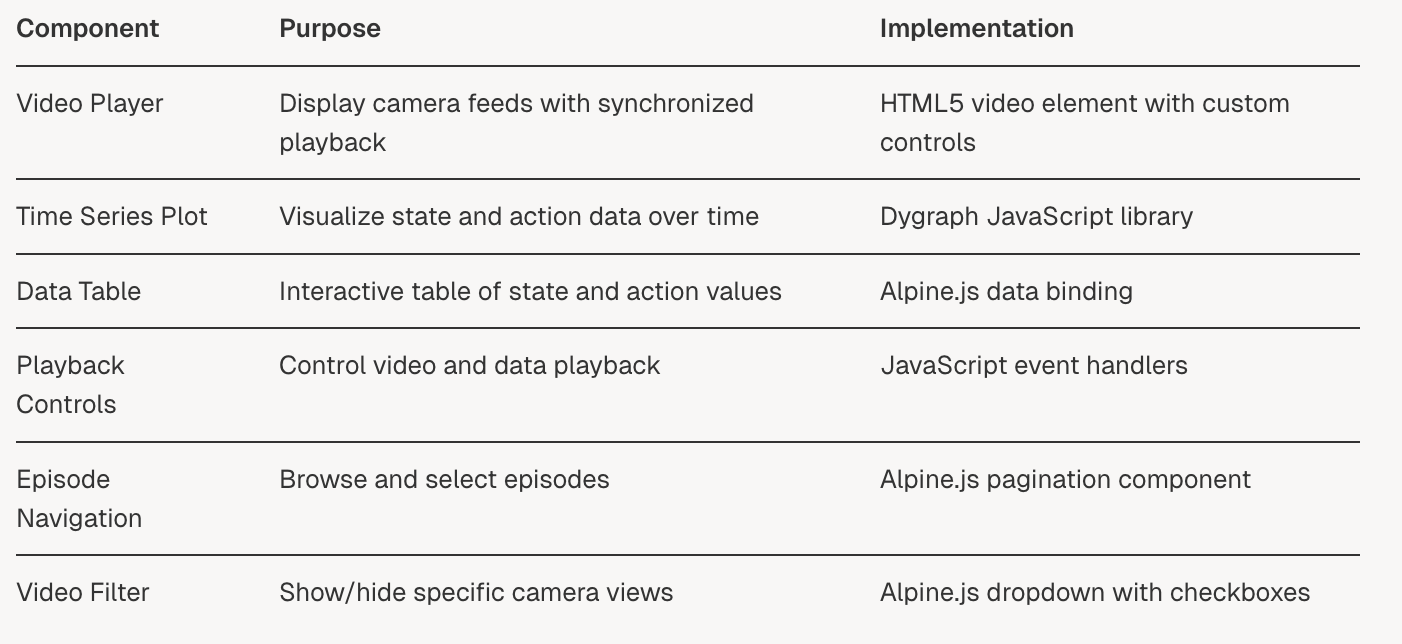
时间序列数据可视化
HTML 界面使用 Dygraph JavaScript 库创建数据集特征的交互式时间序列可视化:
- 从数据集中提取时间序列数据并转换为 CSV 格式
- Dygraph 在浏览器中加载 CSV 数据
- 图表与视频播放同步
- 用户可以与图表交互以选择特定时间点
- 可以切换数据值的可见性
可视化系统处理数据集中的各种数据类型:
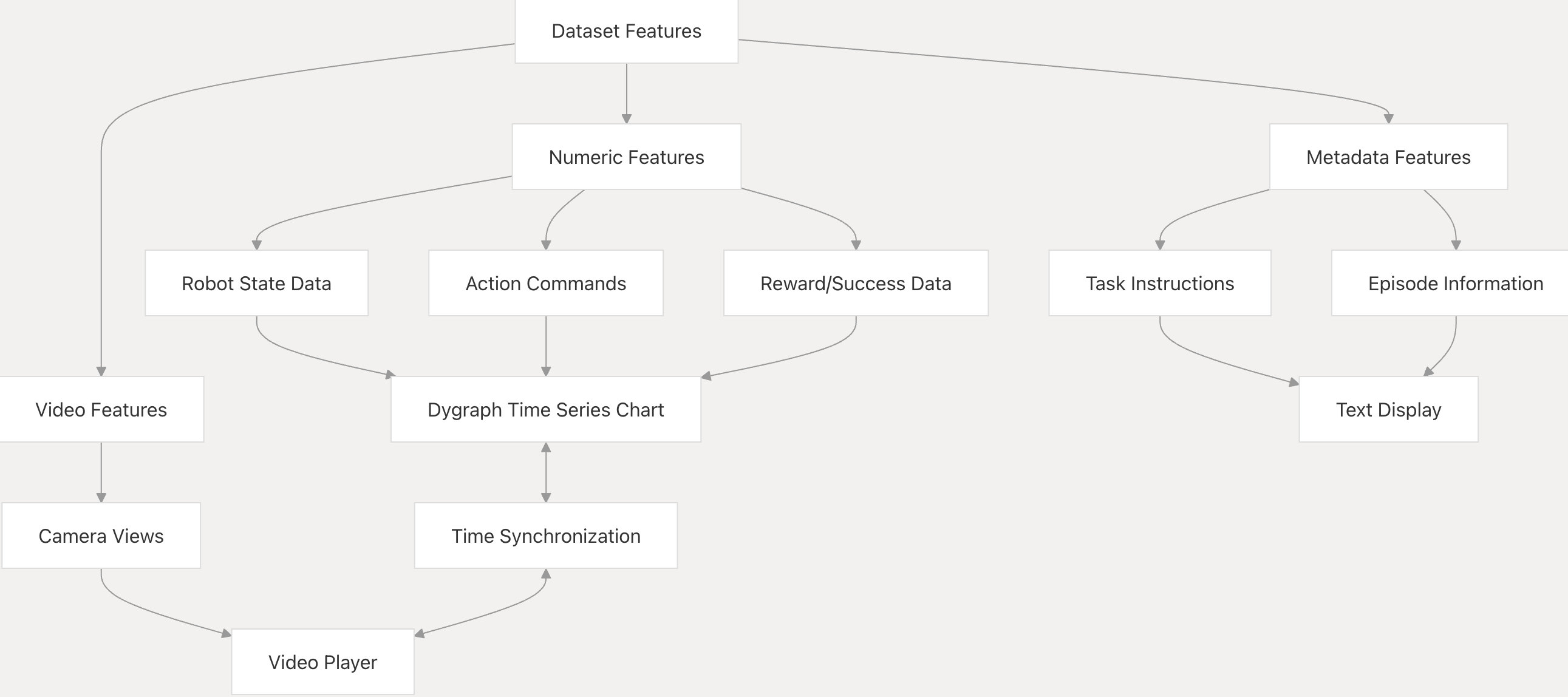
常见用例
- 调试数据集问题:识别缺失帧、错误的状态/动作数据或时间戳异常。
- 策略制定:分析机器人行为并将策略输出与人类演示进行比较。
- 数据收集验证:确保在远程操作或自主操作期间数据收集工作正常。
- 教育用途:出于教育目的研究机器人行为和任务。
技术实现细节
EpisodeSampler
两种可视化工具都使用 EpisodeSampler 提取特定情节的帧:
classEpisodeSampler(torch.utils.data.Sampler):
def__init__(self, dataset: LeRobotDataset, episode_index: int):
from_idx = dataset.episode_data_index[“from”][episode_index].item()
to_idx = dataset.episode_data_index[“to”][episode_index].item()
self.frame_ids = range(from_idx, to_idx)
该采样器与 PyTorch 的 DataLoader 一起使用,可以有效地加载 episode 帧。
HTML 可视化的数据提取
HTML 可视化提取时间序列数据并将其转换为 CSV 格式以便在浏览器上呈现:
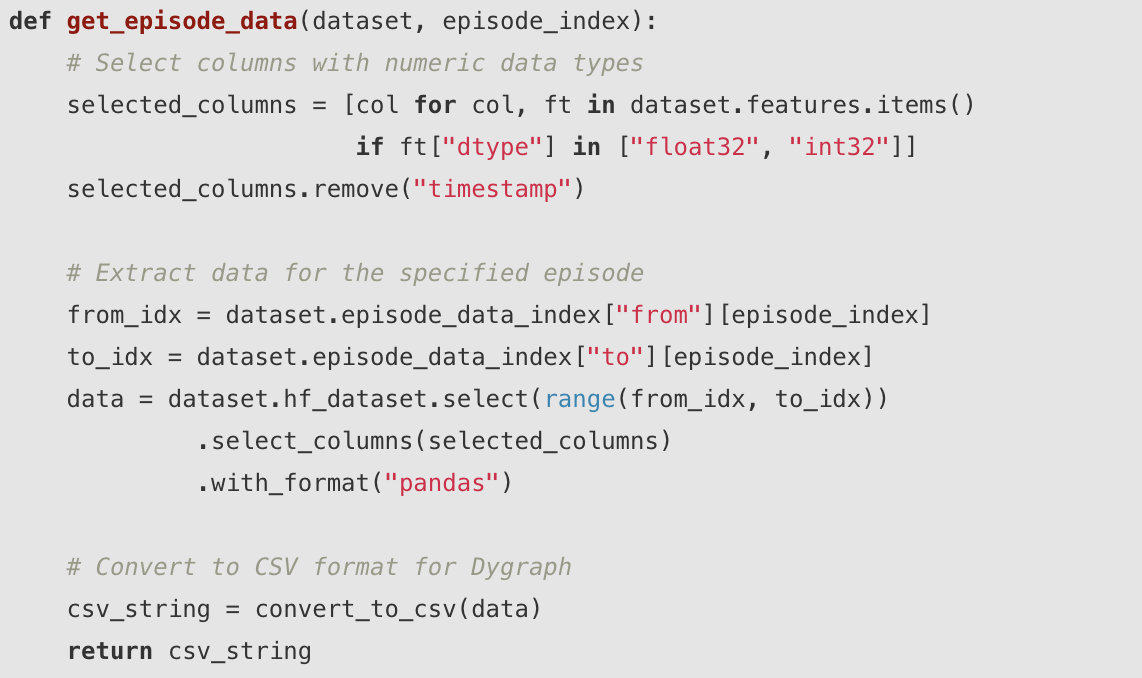
编程接口
这两款可视化工具都提供了可在 Python 代码中导入和使用的编程接口:
rerun 可视化
from lerobot.scripts.visualize_dataset import visualize_dataset
visualize_dataset(dataset, episode_index=0, mode=“local”)
HTML 可视化
from lerobot.scripts.visualize_dataset_html import visualize_dataset_html
visualize_dataset_html(dataset, episodes=[0, 1, 2], host=“localhost”, port=9090)
这些接口可用于将数据集可视化集成到自定义工作流程和应用程序中。
小节
LeRobot 的数据集可视化工具提供了多种互补方法来检查数据集内容:
- Rerun 可视化:用于调试和详细分析的技术性、精确的可视化
- HTML/Flask 可视化:用户友好的 Web 界面,用于探索具有交互功能的数据集
这些工具能够高效地调试、分析和理解机器人数据集,这对于开发和评估机器人学习策略至关重要。

















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









