









23年4月来自上海AI实验室,香港中文大学和Rutgers大学的论文“LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model“。
尽管最近的 LLaMA-Adapter 展示用 LLM 处理视觉输入的潜力,但它仍然不能很好地推广到开放式视觉指令,并且落后于 GPT-4。 本文提出 LLaMA-Adapter V2,一种参数高效的视觉指令模型。 具体来说,首先通过解锁更多可学习参数(例如范数、偏差和尺度)增强 LLaMA-Adapter,这些参数将指令跟从的能力扩展到整个 LLaMA 模型中。 其次,提出一种早期融合策略,仅将视觉token馈送到早期的 LLM 层,有助于更好的视觉知识融合。 第三,通过优化不相交的可学习参数组,将图像-文本对和指令跟从数据的联合训练范例引入进来。 该策略有效地减轻了图文对齐和指令跟从这两个任务之间的干扰,仅用小规模的图文和指令数据集即可实现强大的多模态推理。 在推理过程中,将额外的专家模型(例如字幕/OCR系统)合并到LLaMA-Adapter中,进一步增强其图像理解能力,而不会产生训练成本。 与原始的LLaMA-Adapter相比,LLaMA-Adapter V2只需在LLaMA上引入14M参数即可执行开放式多模态指令。 该框架还表现出更强大的纯语言指令跟从能力,甚至在聊天交互方面也表现出色。
如图展示的是引入几种策略来增强 LLaMA-Adapter [72] 的能力,从而实现具有卓越多模态推理的参数高效视觉指令模型 LLaMA-Adapter v2。
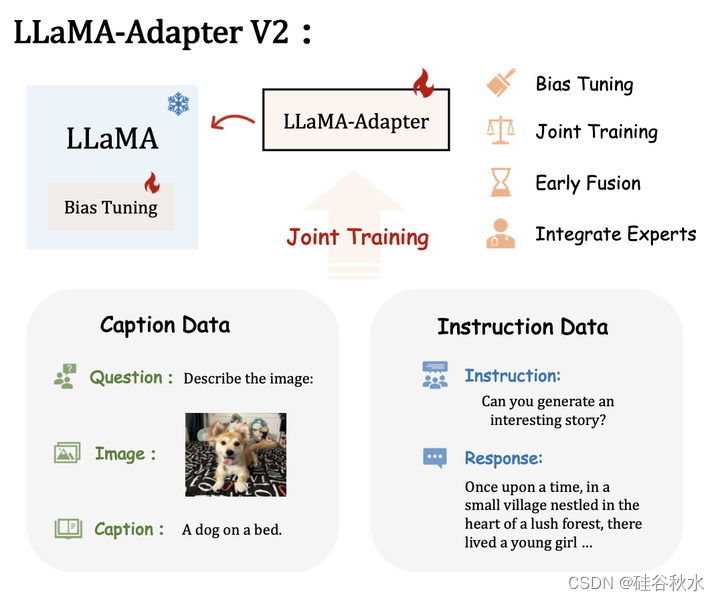
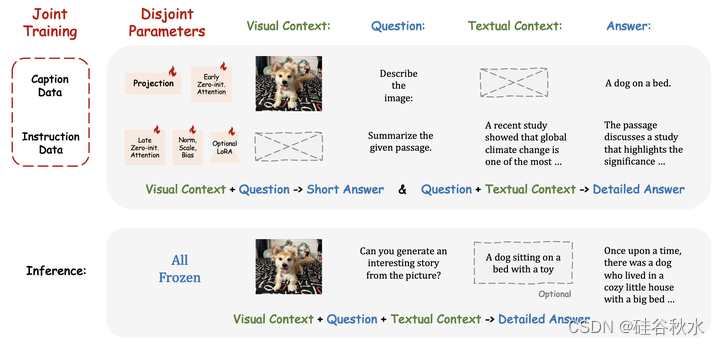
由于 500K 图文对和 50K 指令数据之间的数据量差异,简单地将它们组合起来进行优化可能会严重损害 LLaMA-Adapter 的指令跟从能力。因此,一个联合训练策略优化了 LLaMA-Adapter V2 中不相交的参数组,分别用于图像文本对齐和指令跟从。 具体来说,只有视觉投影层和带门控的早期零初始注意机制,对图像文本字幕数据进行了训练,而后期适应提示、零门控、不冻结参数模式、新添加偏差和尺度因子(或可选的低秩因子【25】)一起用于从指令跟从数据中学习。 这种不相交的参数优化自然地解决了图像文本理解和指令跟从之间的干扰问题,有助于LLaMA-Adapter V2涌现的视觉指令跟从能力。如图显示如何利用图像文本字幕和纯语言指令数据来联合训练 LLaMA-Adapter V2,优化不相交的可学习参数组。
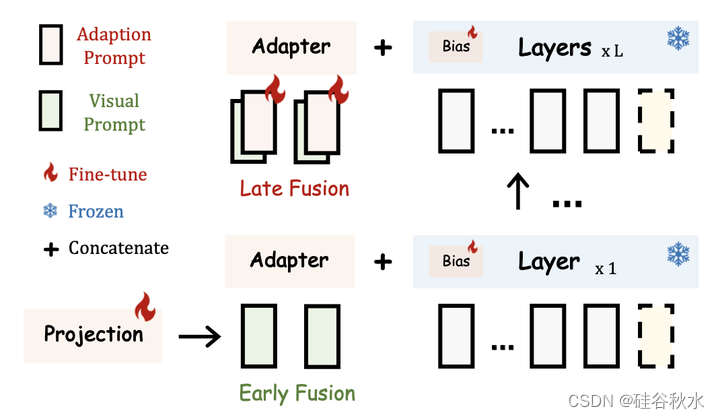
为了避免视觉和语言微调之间的干扰,作者提出了一种简单的早期融合策略,以防止输入视觉提示和适应提示之间的直接交互。 在 LLaMA-Adapter 中,输入视觉提示由一个有可学习视觉投影层的冻结视觉编码器顺序地进行编码,然后添加到每个插入层的适应提示中。 在 LLaMA-Adapter V2 中,将编码的视觉token和适应提示注入不同的 Transformer 层,而不融合在一起,如图所示。
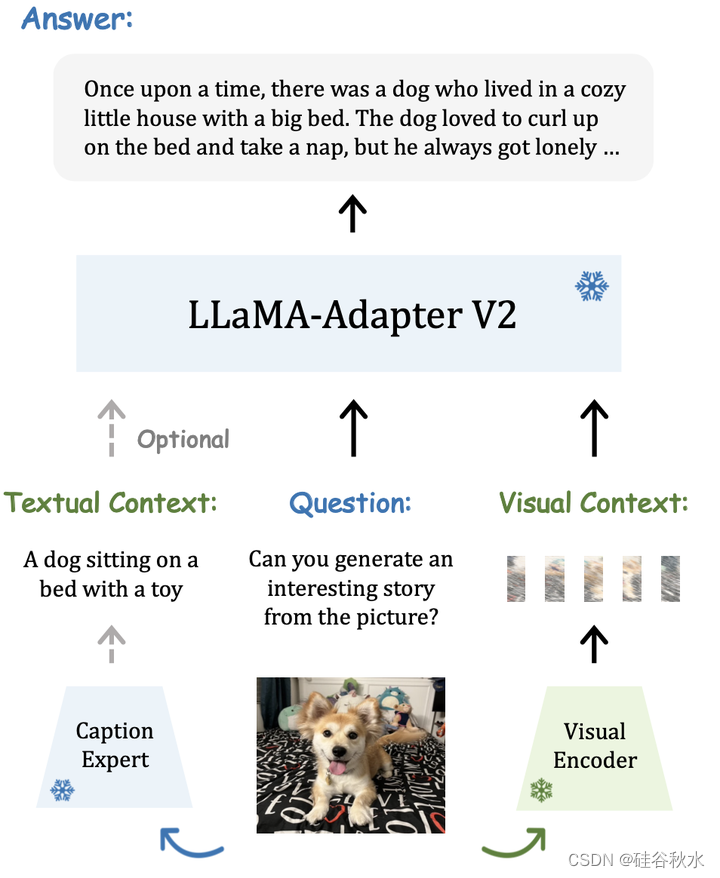
最后是一个LLaMA-Adapter V2的通用流水线图:在推理过程中,引入了额外的字幕专家,为输入图像生成文本上下文,展示了 LLaMA-Adapter V2 强大的视觉理解能力。给定输入图像,用预先训练的视觉编码器对其视觉上下文进行编码,并要求专家系统生成字幕作为文本上下文。 在默认实现中,采用在 COCO Caption [6] 上预训练的 LLaMA-Adapter 作为专家系统,因为它可以生成简短而准确的图像描述。 然而,值得注意的是,任何图像-到-文本的模型甚至搜索引擎都可以充当这里的专家系统。 本文方法能够根据手头的特定下游任务轻松地在不同的专家系统之间切换。















 1456
1456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









