









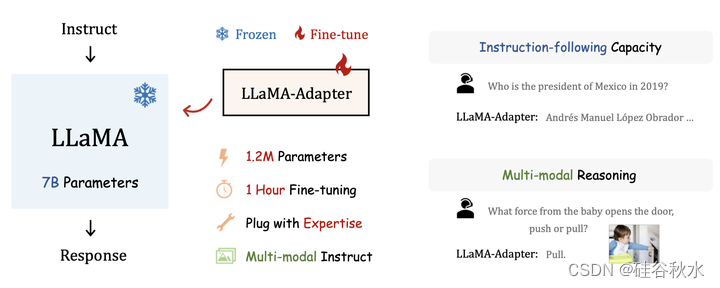
23年6月来自上海AI实验室,香港中文大学和UCLA的论文“LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention“。
LLaMA-Adapter是一种轻量级的自适应方法,可以有效地将 LLaMA 微调为指令跟从模型。 用 52K 自指令(self instruct)的演示,LLaMA-Adapter 在冻结的 LLaMA 7B 模型上仅仅引入了 1.2M 可学习参数,并且在 8 个 A100 GPU 上进行微调的成本还不到一小时。 具体来说,采用一组可学习适应的提示,并将它们添加到Transformer更高层的单词token中。 然后,提出一种零门控(zero gating)的零初始注意机制,将新的指令线索自适应地注入LLaMA,同时有效地保留其预训练的知识。 通过高效的训练,LLaMA-Adapter 可以生成高质量的响应,可与具有全微调7B 参数的 Alpaca 相媲美。 除了语言命令之外,该方法还可以简单地扩展用于学习图像条件 LLaMA 模型的多模态指令,该模型在 ScienceQA 和 COCO Caption 基准上实现了卓越的推理性能。 此外,还评估了零初始注意机制,让它在传统视觉和语言任务上微调其他预训练模型(ViT、RoBERTa),展示了卓越的泛化能力。
如图显示LLaMA -adapter的特点。 轻量级自适应方法在一小时内仅用 120 万个可学习参数有效地微调 LLaMA 7B 模型。 经过训练,LLaMA-Adapter 表现出卓越的指令跟从和多模态推理能力。
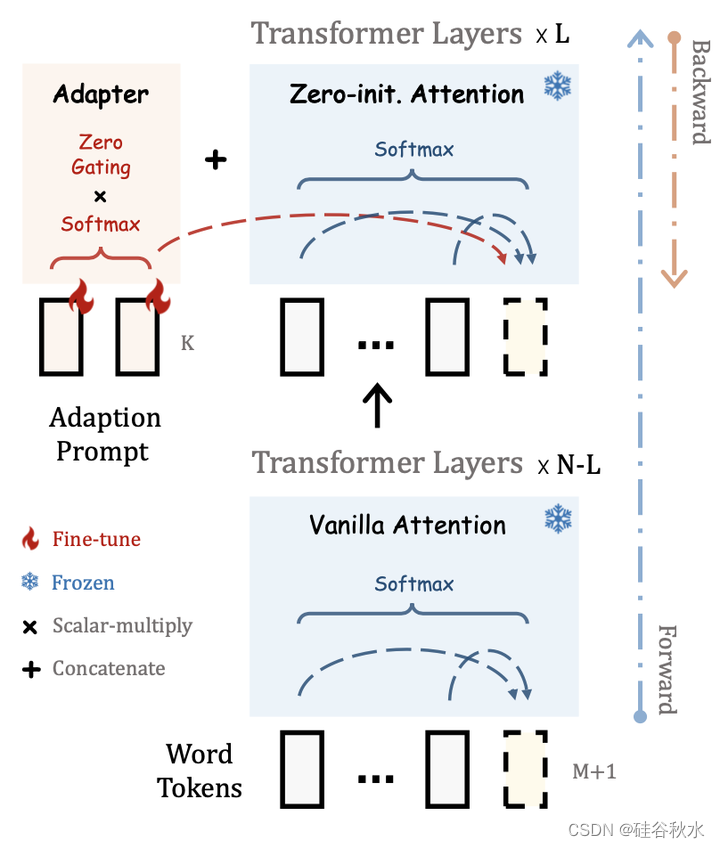
下图给出一些细节。如果随机初始化自适应提示,可能在训练开始时会对单词token造成干扰,从而损害微调的稳定性和有效性。 考虑到这一点,为了逐步学习指令知识,采用零初始注意机制和门控机制实现早期的稳定训练。该方法将最后 L个Transformer层的普通注意机制修改为零初始注意,即插入具有可学习提示的轻量级适配器。
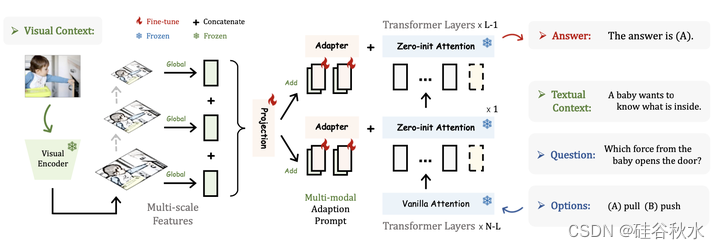
除了文本指令之外,LLaMA-Adapter 还能够根据其他模态的输入回答问题,丰富的跨模态信息增强了语言模型。 如图所示:以ScienceQA基准[41]为例,类似于COCO Caption数据集[8];给定视觉和文本上下文以及相应的问题和选项,模型需要进行多模态理解才能给出正确答案;在 ScienceQA 基准 [41] 上,LLaMA-Adapter 被扩展为用于图像条件问答的多模态变型;给定图像作为视觉上下文,通过多尺度聚合获取全局图像token,并将其按元素添加到适应提示中以跟从视觉指令。
零初始注意机制的适应提示方法,不仅限于指令模型领域,还可以进一步用于微调传统视觉和语言任务中的大模型,发挥卓越的泛化能力。
视觉模型。 选择预训练的 ViT [16] 作为下游图像分类任务的基础视觉模型。 与 LLaMA 类似,将自适应提示作为前缀插入到 ViT 中最上面的 L 个Transformer层中,并将所有插入层的注意操作修改为零初始注意。 通过越来越多地注入下游视觉语义,只在冻结ViT 之上引入一些参数,在 VTAB-1k [67] 基准上获得与全微调相当的分类精度,这表明了注意算子在视觉领域的功效。
语言模型。 用在大规模未标记文本语料库上预训练的 RoBERTa [40],并在 SQuAD [54] 基准上评估提取式问答的零初始化注意操作。 在 P-tuning v2 [38] 之上实现了零初始注意,这是一种有效适应地大语言模型的提示调整方法。 同样,仅启用 P-tuning v2 中的提示token和零门控因子,使其在微调期间可学习。 结果证明在传统语言任务上的优势。

















 2079
2079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









