










20年4月来自英国Bristol大学、加拿大多伦多大学、意大利Catania和Nvidia的论文“The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines”。
自 2018 年推出以来,EPIC-KITCHENS 就作为最大的以自我为中心的视频基准而备受关注,它为人们与目标的互动、注意甚至意图提供了独特的视角。本文详细介绍 32 名参与者如何在他们自己的厨房环境中捕获这个大规模数据集,并密集地注释动作和目标交互。这些视频描述了非脚本化的日常活动,因为每次参与者进入他们的厨房时都会开始录制。录制由来自 10 个不同国籍的参与者在 4 个国家/地区进行,因此厨房习惯和烹饪风格高度多样化。该数据集包含 55 小时的视频,由 11.5M 帧组成,对其进行了密集标注,总共有 39.6K 个动作片段和 454.2K 个目标边框。其标注是独一无二的,因为让参与者讲述他们自己的视频(录制后),从而反映真实意图,并且基于这些内容实际上众包了真值。描述了目标、动作和预期挑战,并评估了两个测试分组(见过的厨房和没见过的厨房)中的几条基线。同时,引入新的基线,强调数据集的多模态性质以及显式时间建模对于区分细粒度动作(例如“关闭水龙头”和“打开”水龙头)的重要性。
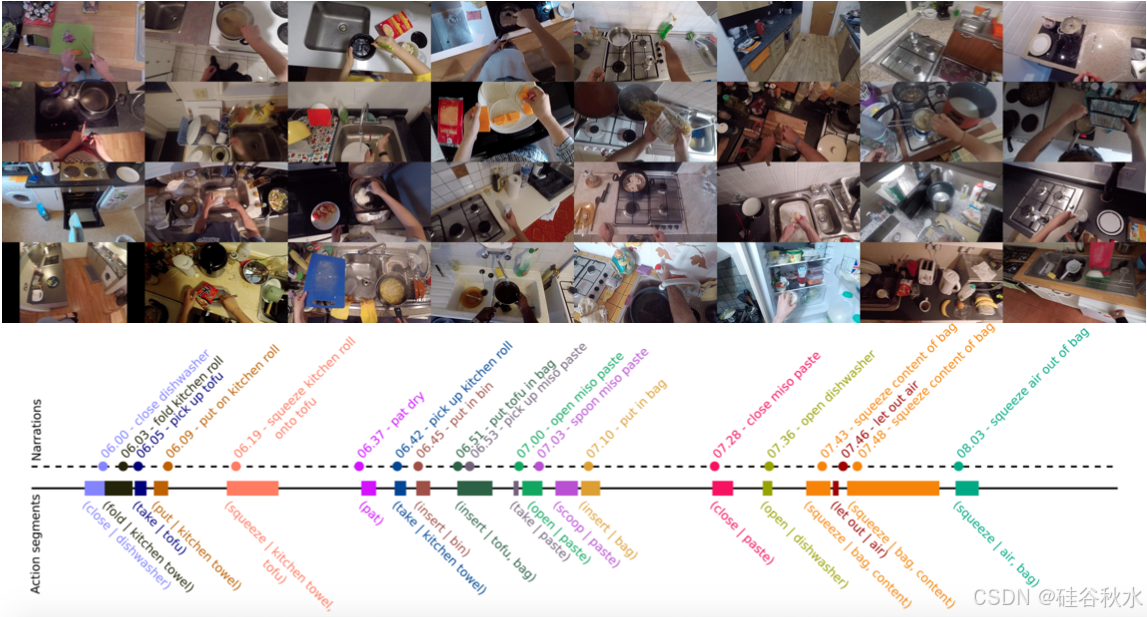
如图所示 EPIC-KITCHENS 来自 32 个环境的帧;参与者用来注释动作片段的叙述;活动目标边框注释。

首先将 EPIC-KITCHENS 与六个常用的自我中心数据集 [20]、[21]、[22]、[23]、[24]、[25] 以及五个关注目标交互活动的第三人称活动识别数据集 [18]、[19]、[26]、[27]、[28] 进行比较。排除关注人-人互动的自我中心数据集 [29]、[30]、[31] 以及教学视频 [32]、[33]、[34]、[35],因为它们针对不同的研究问题。如下表是数据集的比较结果:
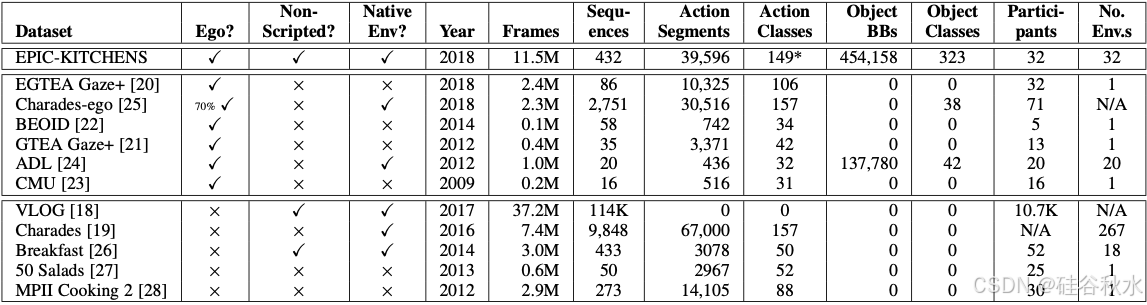
一些数据集旨在捕捉原生环境中的活动,其中大多数以第三人称记录 [10]、[18]、[19]、[25]、[26]。[26] 专注于根据早餐食谱列表烹饪菜肴。在 [18] 中,通过查询 YouTube 收集了描述与 30 个日常物品互动的视频,而 [10]、[19] 则是脚本化的——要求受试者表演众包故事情节 [19] 或给定动作 [10],这通常会导致看起来不太自然的动作。大多数以自我为中心的数据集同样使用脚本化活动,即人们被告知要执行哪些操作。在遵循指令时,参与者按顺序执行步骤,而不是本文工作中涉及的更自然的现实生活场景,这些场景涉及多任务处理、搜索物品、思考下一步做什么、改变主意甚至意外惊喜。
如图所示是用于数据集记录的头戴式 GoPro设备:

每次录制前,参与者都会使用 GoPro Capture 移动应用检查电池寿命和视点,以便他们伸出的双手大约位于相机画面的中间。立体声音频由 GoPro 的内置麦克风捕捉,采样率为 48000kHz,比特率为 128kb/s。相机设置为线性视野 (fov)、59.94fps 和 1920x1080 的全高清分辨率,但有些受试者做了一些小改动,例如宽或超宽视野或分辨率,因为他们在家中录制了多个序列,因此几天内一直在关闭和打开设备。具体来说,1% 的视频以 1280x720 录制,0.5% 以 1920x1440 录制。此外,1% 以 30fps 录制,1% 以 48fps 录制,0.2% 以 90fps 录制。
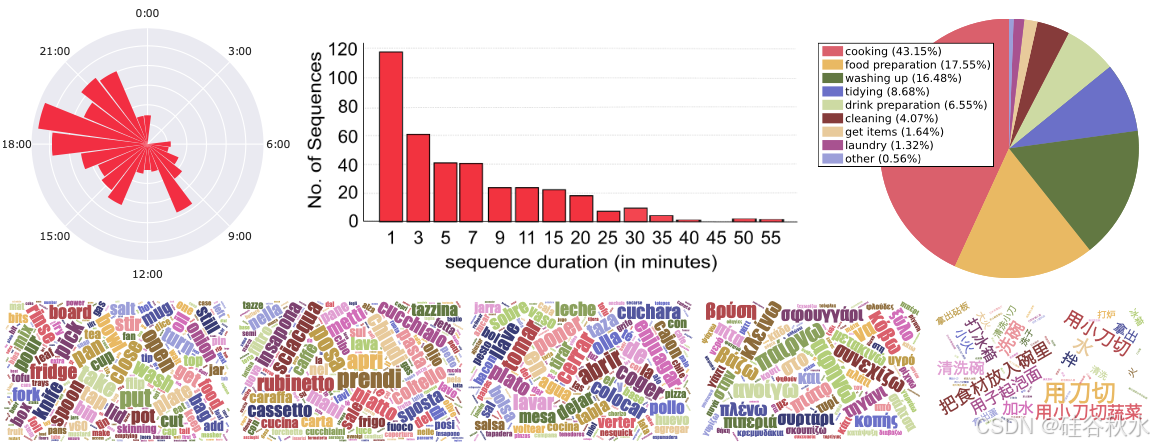
如图列出了叙述的一般指令。参与者如果足够流利,则用英语叙述,或者用他们的母语叙述。总共使用了 5 种语言:17 种用英语叙述,7 种用意大利语叙述,6 种用西班牙语叙述,1 种用希腊语叙述,1 种用中文叙述。

下图显示了每种语言中最常用单词的词组:
从参与者本人那里收集叙述,因为与独立观察者相比,他们最有资格给活动贴上标签,因为他们是执行这些行动的人。这里选择了事后记录叙述,这样参与者就可以不受干扰地进行日常活动,而不必担心标签。
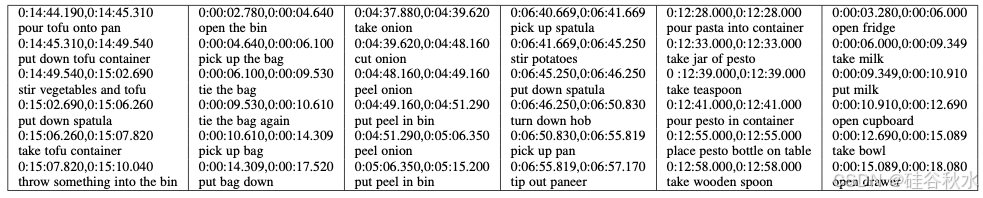
测试了几种自动语音转文本 API [37]、[38]、[39],它们都无法生成准确的转录,因为这些 API 需要相关的语料库和完整的句子作为上下文。因此,通过 Amazon Mechanical Turk (AMT) 收集手动转录,并使用 YouTube 的自动隐藏字幕对齐工具来生成准确的时间。对于非英语旁白,还要求 AMT 工作人员翻译句子。为了使这项工作更适合 AMT,语音文件会通过消除低于预先指定分贝阈值的静音(压缩和规范化后)进行拆分。然后将语音块分组到 AMT 的人类智能任务 (HIT)中,每个持续时间约为 30 秒。为了确保一致性,提交相同的 HIT 三次,并选择与至少一个其他 HIT 编辑距离为 0 的 HIT。当不一致时,会手动更正。下表提供了转录和定时叙述的示例。
还要求参与者每个序列提供一个句子来描述发生的总体目标或活动,其示例见下表。

对于每个叙述句子,用 AMT 调整动作的开始和结束时间。为了确保注释者能够进行时间定位训练,根据之前的工作理解 [41] 提供了一个入门教程,解释了动作的时间界限。每个 HIT 由最多 10 个连续的叙述短语 pi 组成,其中注释者将 Ai = [tsi, tei] 标记为第 i 个动作的开始和结束时间。如图是时间标注的例子:

叙述的名词对应于与动作相关的目标 [22]、[43]。假设 Oi 是与动作段 Ai = [tsi, tei] 相关的短语 pi 中的一个或多个名词的集合。将 [tsi − 2s, tei + 2s] 内的每个帧 f 视为注释 Oi 中每个目标边框的潜在帧。基于 [44] 中的接口构建了在 AMT 上注释边框的功能。每个 HIT 都旨在为一个目标获取注释,最长持续时间为 25 秒,相当于 2fps 的 50 个连续帧。注释者还可以注意到目标在 f 中不存在。特别要求同一位注释者注释连续的帧,以避免对目标的范围做出主观决定。还评估注释者的质量,通过确保注释者每次 HIT 开始在两个黄金注释上获得 IoU ≥ 0.7 。
如图所示目标注释选择,该方法的注释(绿色)与每帧最佳注释(橙色)。其他注释者为蓝色。

由于参与者使用多种语言自由文本进行注释,因此收集了各种动词和名词。例如,“放”、“放置”、“放下”、“放回”、“离开”或“返回”都曾用于表示将目标放置在某个位置。尝试将这些词语分组为语义重叠最小的类,以适应更典型的多类检测和识别方法,其中每个示例被认为只属于一个类。使用 spaCy 的英语核心网络模型估计词性 (PoS),以确定短语中的动词和名词。这是必要的,因为尽管大多数注释都是动词-名词短语,例如“拿杯子”或“打开冰箱”,但也有一些注释包含介词,例如“把平底锅放在炉架上”,还有的注释包含多个目标,例如“放下洋葱和刀子”。通过选择句子中的第一个动词来查找动词,并查找句子中的所有名词(不包括与所选动词匹配的名词)。当名词缺失或被代词替换(例如“它”)时,用直接在前面叙述中的名词(例如 pi:“冲洗杯”,pi+1:“放置晾干”)。
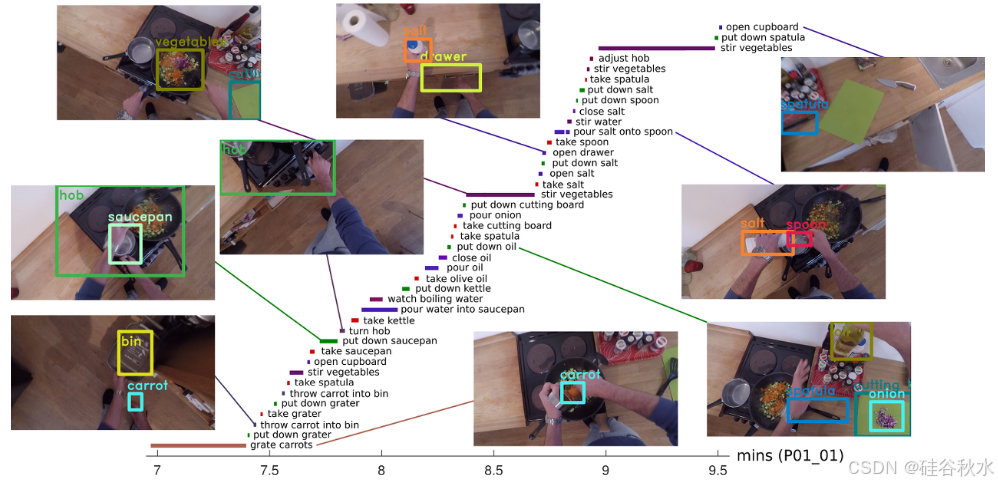
如图可视化使用关键帧目标注释对连续动作片段进行采样的结果:

















 2040
2040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









