










24年7月来自斯坦福/哥伦比亚大学和谷歌的论文“UMI on Legs: Making Manipulation Policies Mobile with Manipulation-Centric Whole-body Controllers”。
UMI-on-Legs,这是一个将现实世界和模拟数据相结合的四足机器人操纵系统新框架。用手持式夹持器 (UMI) 在现实世界中扩展以任务为中心的数据收集,从而提供一种无需机器人即可展示与任务相关操纵技能的廉价方法。同时,训练全身控制器(WBC)进行任务跟踪(无需任务模拟设置),在模拟中扩展以机器人为中心的数据。这两个策略之间的接口是任务框架中的末端执行器轨迹,由操纵策略推断并传递给全身控制器进行跟踪。在抓握、非抓握和动态操纵任务上评估 UMI-on-Legs,并报告所有任务超过 70% 的成功率。最后,展示在四足机器人系统上对先前工作中预训练的操纵策略检查点进行零样本跨具身部署,该检查点最初用于固定底座机械臂。这个框架为学习动态机器人富有表现力的操控技能提供了一条可扩展的途径。机器人视频、代码和数据的网站:https://umi-on-legs.github.io/
UMI-on-Legs如图所示:用手持式抓手(左)和经过模拟训练的全身控制器(右)的真实世界演示,在四足机器人身上实现了完全自主、富有表现力的真实世界操控技能。该框架允许将现有的“桌面”操控策略移植到移动操控中,同时增强四足机器人腿部的机动性和力量。

先前的研究表明,在目标检测器/分割模型的帮助下,在模拟中训练的拾取和放置四足机器人可以直接部署在现实中[12,16],用于视觉域迁移。对于轮式基座系统,当存在精心设计的操作原语时,已经展示了更具挑战性的移动操作技能[17–21],这使得能够使用基础模型[23–26]、在线学习[18,19]或轨迹优化[21]进行感知和规划[17,20,22]。为了减轻观察和行动空间的手动设计,Mobile-ALOHA[27]提出了一个轮式双手平台用于演示收集。然而,所有这些系统都假设准静态操纵和/或重心低的基座。
从学习动态运动技能 [6, 28–30] 到操控技能 [31–33],强化学习 [34] (RL) 与大规模并行模拟器 [3, 7] 是解决足式机器人控制难题的主要范例。为了部署这些控制器,存在大量针对不同具身和环境条件的域自适应 [7–9] 工作。为了支持四足系统的移动操控,先前的研究还探索训练全身控制器 [8, 10, 11]。然而,除了使用 AprilTags [35] 的简化场景外,这些先前的全身控制四足系统还需要人类用户执行操控(远程操作、演示重放)。虽然完全自主执行在理论上是可行的,但收集足够的数据来学习有效的操控技能的实际成本很高。这些实际挑战源于对机器人特定命令(例如身体速度命令)的依赖和/或数据收集期间对机器人物理存在的要求。He 将行为克隆(BC)策略和 RL 控制器与任务框架轨迹接口相结合。但是,他们使用控制器在模拟中启发式地生成特定机器人的演示。他们的算法设计在可扩展性(演示是机器人/控制器特定的)和可用性/表达性(特定于任务的启发式演示生成)方面受到限制。此外,由于他们依赖于 AprilTag 跟踪,因此系统设计受到带有外部摄像头的约束设置限制。
为了实现更高性能、更通用和更强大的操作,大量关于行为克隆的工作在策略架构 [2, 37–41]、传感器位置 [37]、动作空间 [38]、数据质量 [37, 42]、数据大小 [43–47] 和数据成本 [1, 27, 38, 48, 48, 49] 方面进行了创新。从这个经过深入研究的领域中,一些核心设计决策已成为主流选择,包括使用预训练的视觉编码器 [1, 25, 43]、基于扩散的动作解码过程 [1, 2, 27, 41, 43, 47, 49] 和末端执行器序列预测 [1, 38, 41, 43, 47, 49]。此外,当仅与以自我为中心/腕戴式视觉观察一起使用时,Yang 和 Chi 已经展示零样本跨具身的视觉-运动策略迁移。然而,通过预测目标姿势序列,他们假设完美的低级控制器能够精确跟踪这些目标。
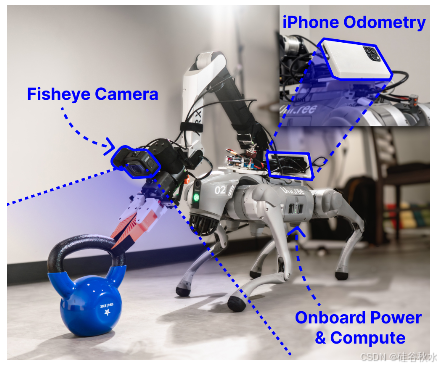
在野外有腿的操控系统如图所示:移动操控系统具有强大、低延迟的 iPhone 里程计和板载电源/计算功能,可实现野外移动操控。
本文系统概述如图所示:系统将 GoPro 的 RGB 图像作为输入,并使用扩散策略 (a) 推断出相机框架末端执行器轨迹,该策略使用真实世界的 UMI 演示进行训练。将此轨迹转换为任务空间,并将其用作 WBC 的接口(b)。该控制器 © 以 50Hz 的频率输出关节位置目标,随后 PD 控制器会跟踪这些目标。
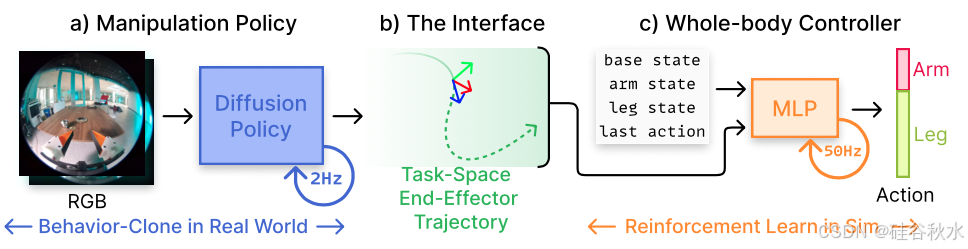
UMI-on-Legs 由两个主要组件组成:(1) 基于扩散的高级操纵策略 [2],它将腕戴式相机视图作为输入,并在相机框架中输出未来的末端执行器姿势目标序列,以及 (2) 低级全身控制器,通过输出腿部和手臂的关节位置目标来跟踪末端执行器姿势目标。使用在现实世界中收集的数据(使用手持式夹持器数据收集设备 UMI [1])训练操纵策略,并使用大规模并行模拟器 [3] 完全在模拟中训练 WBC。
该方法选择使用任务框架末端执行器轨迹作为界面具有以下优势:
• 直观演示:使用末端执行器轨迹而不是机器人特定的低级动作,允许非专家用户使用 UMI [1] 等手持设备进行直观的任务演示。
• 预览范围中的高级意图:通过预览未来目标(target)的范围,全身控制器可以预测即将到来的动作。例如,如果即将发生高速抛掷,机器人应该相应地做好准备。同时,如果目标在手臂可触及的范围内移动,身体应该倾斜而不是迈步,这有晃动末端执行器的风险。
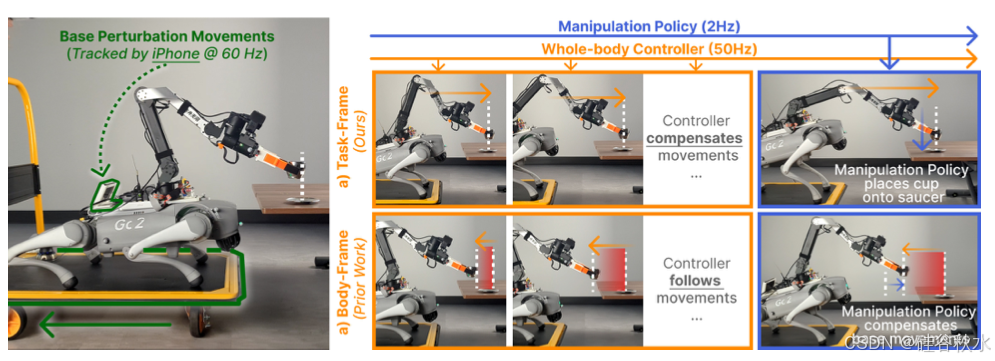
• 任务框架中的精确和稳定操作:与大多数使用身体坐标系跟踪的腿部操纵系统不同,该控制器跟踪任务空间中的动作(如图所示,WBC 学习跟踪任务坐标系 (a) 中的目标轨迹,有效地补偿基础扰动,因此释放操纵策略以专注于任务进展;相比之下,大多数现有 WBC 使用身体坐标系跟踪 (b)[8, 10–12],经过训练以跟踪基础扰动。实际上,它们将任务空间跟踪职责推迟到低速率操纵策略,无法对身体扰动做出快速反应),无论基本运动如何,该动作都是持久的,从而实现精确和稳定的操纵。
• 异步多频执行:该接口定义一个自然的推理层次结构,允许低频操纵策略(1-5Hz)与高频低级控制器(50Hz)协调,以处理截然不同的传感器和推理延迟。
• 与任何基于轨迹的操纵策略兼容:该接口支持任何基于轨迹的操纵策略即插即用 [1、38、41、43、47、49]。随着在不同数据集上训练的策略兴起 [43–47],以操纵为中心的 WBC 可以加速将现有的“桌面”操纵技能移植到“移动”操纵。
具有行为克隆的操纵策略
按照 Chi 的默认配置,用 U-Net [50] 架构扩散策略 [2] 与 DDIM 调度程序 [51] 和预训练的 CLIP 视觉编码器 [25]。用更长的行动范围 64,为低级控制器提供更多未来信息。对于杯子重排任务,直接使用 UMI [1] 的杯子重排列检查点。对于推抛任务,收集数据并从头开始训练扩散策略。
具有强化学习的全身控制器
为了跟踪从操纵策略预测的末端执行器轨迹,在模拟中使用强化学习训练全身控制器来推断手臂和腿部关节目标。值得注意的是,设置模拟来跟踪这些操纵末端执行器轨迹不需要设置操纵任务和环境。这种设计极大地缓解使用模拟数据的关键瓶颈。
任务坐标系的轨迹跟踪操作轨迹。先前的研究 [8、10–12] 通常在身体坐标系中对目标末端执行器姿势进行采样以训练其 WBC,这简化了策略优化,但并未训练控制器补偿身体运动和扰动所需的全身协调技能。在操作过程中手臂的动量导致显著的基础运动(即轻量级基础或动态手臂运动)的情况下,此问题会更加严重。相反,本文训练控制器跟踪任务框架中的姿势轨迹。这样教导手臂通过补偿和抵消身体运动或摇晃来保持其在任务框架中的末端执行器姿势。为了向控制器提供相关的参考轨迹,使用 UMI [1] 收集的轨迹。
观察空间。观察空间包括机器人的 18 个关节位置和速度、基本方向和角速度、先前的动作以及由操作策略推断出的末端执行器轨迹。用 3D 矢量表示位置,并使用 6D 旋转表示 [52] 表示末端执行器姿势。以相对于当前时间的 20ms 间隔从 -60ms 到 60ms 密集采样目标姿势,从而告知控制器当前速度和加速度。此外,将目标纳入未来的1000ms,这有助于控制器在必要时准备迈出脚的那些步。
奖励。任务目标奖励针对目标姿势的策略,将位置误差 εpos 和方向误差 εorn 最小化:exp(−( εpos/σpos + εorn/σorn )),其中 σ 是根据精度要求缩放的项。在这个公式中,位置和方向的项是纠缠在一起的。这比单独的位置和方向项更能产生理想的行为,这会导致策略仅在位置或方向上实现高精度。对位置和方向的一个 σ 课程对于在训练的早期阶段进行探索是必要的,同时迫使策略在后期阶段实现高精度。除了主要任务奖励之外,还遵循常见的惯例 [7–9, 12],包括额外的正则化和成形项。
策略网络架构。训练一个多层感知器 (MLP) 控制器,从观察值映射到腿部 (12 DOF) 和手臂 (6 DOF) 的目标关节位置。该控制器的前向传递在机器人的板载 CPU 上需要 ≈0.06 毫秒,并在部署期间以 50Hz 的频率调用。对腿部和手臂,使用单独的 PD 控制器跟踪关节的位置目标。
系统集成
机器人系统设置。机器人系统由 12 自由度 Unitree Go2 四足机器人和 6 自由度 ARX5 机械臂组成,均由 Go2 的电池供电。用 Finray 夹持器和 GoPro 定制 ARX5 机械臂以匹配 UMI 夹持器 [1]。全身控制器在 Go2 的 Jetson 上运行,而扩散策略推理通过互联网连接在单独的台式机 RTX 4090 上运行。安装一个 iPhone 进行姿势估计,并通过以太网电缆将其连接到 Jetson。
Sim2Real 迁移。根据之前的研究,在训练期间对机器人施加随机推力以实现更好的稳健性。随机化关节摩擦、阻尼、接触摩擦、身体和手臂质量以及质心。在训练期间模拟 20 毫秒的控制延迟至关重要。为了考虑里程计系统中的噪音,在episode中途每 20 秒随机运输机器人一次。
可访问实时里程计。缺乏实时机载任务-空间跟踪,是先前四足机器人操作工作中的一个常见限制。通过假设使用运动捕捉 [31] 和/或 AprilTags [8、11、36] 进行外部跟踪,它们的系统无法在野外完全自主部署。在本文系统中,用安装在机器人底座上的 iPhone 解决这个缺点。选择后置安装位置避免在机器人手臂上增加额外的重量,防止手臂与手机碰撞,并最大限度地减少运动模糊和视觉遮挡。与许多现有的稳健实时里程计解决方案 [13–15] 相比,该里程计解决方案具有独立、紧凑的外形尺寸,并且仅使用无处不在的消费电子设备。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









