










24年8月来自威斯康星大学的论文“VLM-MPC: Model Predictive Controller Augmented Vision Language Model for Autonomous Driving”。
受视觉-语言模型 (VLM) 新推理能力及其提高自动驾驶系统可理解性的潜力推动, VLM-MPC 是一个闭环自动驾驶控制器,它将模型预测控制器 (MPC) 与 VLM 相结合,评估基于模型的控制如何增强 VLM 决策。提出的 VLM-MPC 分为两个异步组件:上层 VLM 根据前置摄像头图像、自车状态、交通环境条件和参考记忆为下层控制生成驾驶参数(例如,期望速度、期望间隔);下层 MPC 使用这些参数实时控制车辆,考虑发动机滞后并向整个系统提供状态反馈。基于 nuScenes 数据集的实验验证所提出的 VLM-MPC 在各种环境(例如,夜晚、雨天和十字路口)中的有效性。结果表明,VLM-MPC 始终将侵占后时间 (PET) 保持在安全阈值以上,而在某些情况下,基于 VLM 的控制会产生碰撞风险。此外,与真实世界轨迹和基于 VLM 的控制相比,VLM-MPC 增强平滑度。通过比较不同环境设置下的行为,VLM-MPC 具备理解环境和做出合理推断的能力。
该闭环 VLM-MPC 的总体流程如图所示。VLM-MPC在结构上分为两个层次:上层 VLM 部分用作上层规划器,下层 MPC 部分用于自动驾驶汽车控制。
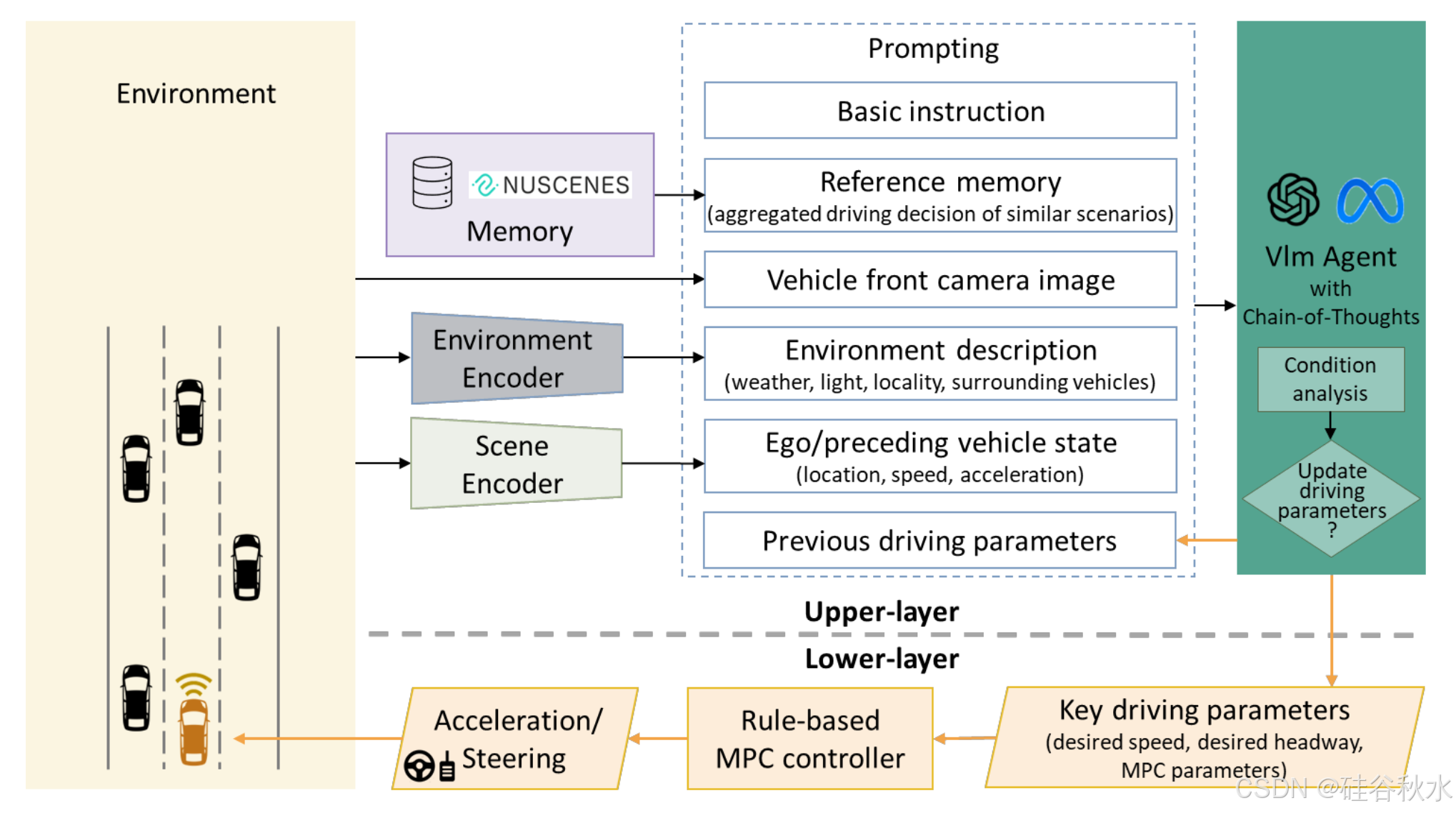
上层 VLM:上层依赖 VLM 作为核心推理和决策组件,由四个子组件组成:
- 环境编码器:从车辆的前置摄像头生成环境描述。
- 场景编码器:从数据集中提取有关本车和前方车辆的信息。
- 参考记忆:此组件存储来自历史驾驶数据集的聚合驾驶参数,为 VLM 提供历史背景和不同驾驶场景的平均参数。
- 提示生成器:构建输入提示并指导 VLM 执行思维链 (CoT) 分析。
前三个组件收集信息以构建第四个组件的提示。一旦提示输入到 VLM,它就会产生上层结果,特别是关键驾驶参数。
下层 MPC:下层是基于规则的 MPC。此部分考虑车辆的底层动态。它依靠上层设置的关键驾驶参数来确定特定动作,然后将其传输到车辆执行。
VLM-MPC 的上层和下层解耦并以不同的频率运行。此设置支持受控异步推理。因此,上层 VLM 不需要像下层 MPC 那样以高频率进行处理。在异步间隔期间,先前得出的上层指令和驾驶参数继续指导下层 MPC。
环境编码器
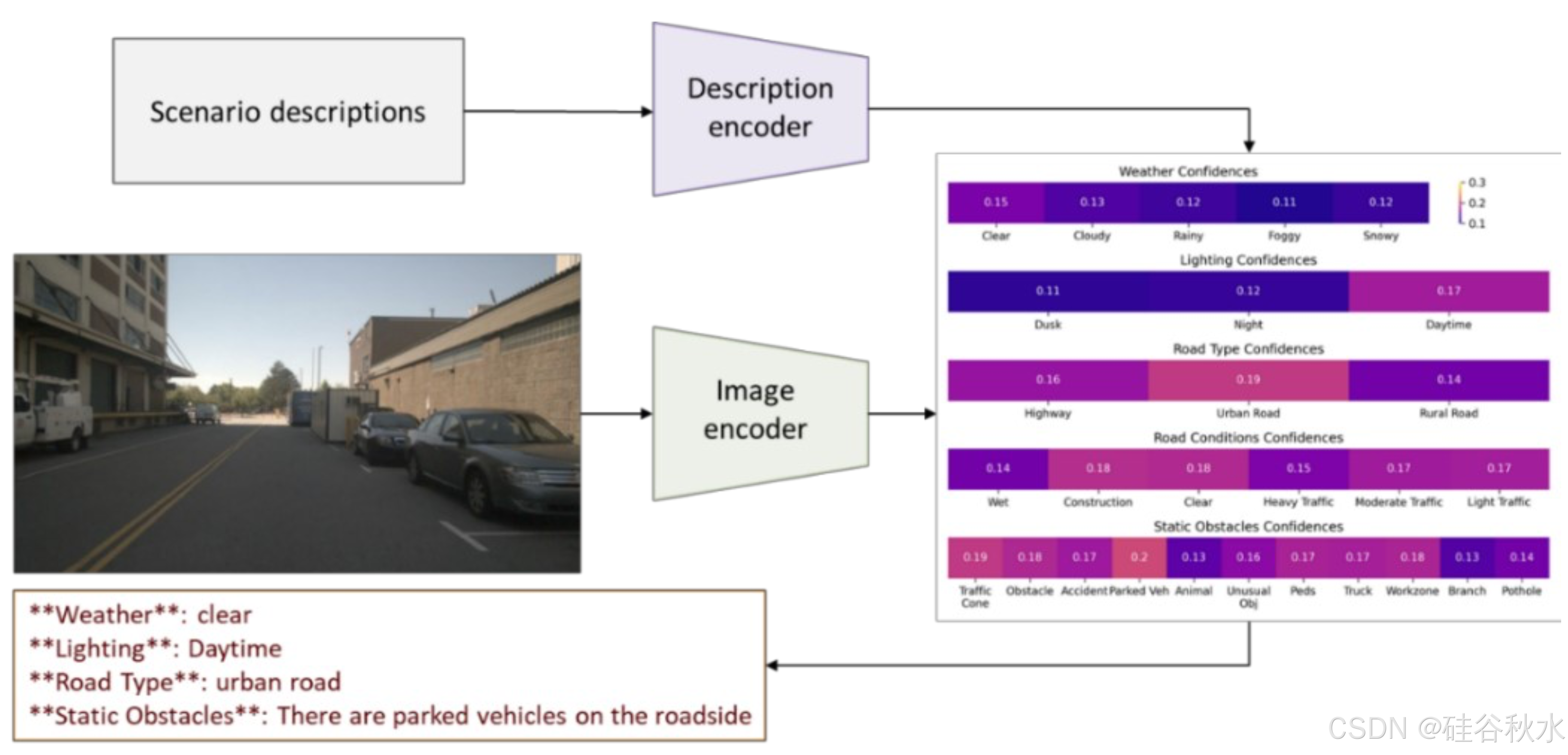
驾驶环境特征(例如天气、光线和道路状况)会显著影响驾驶表现。设𝒯 ≔ {𝑡/1, 𝑡/2, …, 𝑡/𝑛},其中 n 表示在一个场景内完成驾驶任务所需的时间点总数。为了增强 VLM 对环境的理解,该模型输出时间 𝑡∈𝒯 时驾驶环境的语言描述 E/𝑡。E/𝑡 包括时间 𝑡 时的 6 个详细场景描述。
采用对比语言-图像预训练 (CLIP) 模型 (Fang,2024;Radford,2021) 从车辆前置摄像头图像中提取 E/𝑡。加载预训练的“ViT-B/32”配置。定义了几类描述性文本,包括天气条件、照明、道路类型、道路状况和静态障碍物。该过程首先使用 CLIP 模型对输入图像进行预处理和编码以获得图像特征。然后通过 CLIP 模型编码的图像和文本特征之间的余弦相似度计算,将这些特征与预定义的描述性文本进行比较,如图所示。
场景编码器
为了增强 VLM 对驾驶任务的理解,提示包括自车的历史状态信息以及重要周围车辆和其他障碍物的状态。重要周围车辆是指 MPC 算法需要考虑的前车,以实现安全高效的跟车行为。其他障碍物包括任何阻碍自车路径的目标,例如行人,以及交通规则需要考虑的元素,例如红灯处的停车线或十字路口的停车标志。
场景编码器提取时间 𝑡 的场景状态 S/𝑡,包括本车状态 𝑠ego/t、前车状态 𝑠pre/t(如果适用)以及停车线位置𝑠^SL/t(如果适用)。
前方车辆的信息是根据车辆位置、道路信息和 nuScenes 数据集中的其他车辆位置确定的(Caesar,2020)。同样,停车线位置是从 nuScenes 数据集中提供的地图信息中得出的。本研究不考虑交通参与者感知阶段的错误。
参考记忆
参考记忆是基于 nuScenes 数据集中的真实车辆轨迹构建的。它通过汇总来自各种驾驶场景的数据,作为生成关键驾驶参数的参考。虽然来自 nuScenes 的轨迹并非完全来自自动驾驶或人类驾驶,但它们通常表现出安全的驾驶行为,正如安全分析所支持的那样。因此,这些轨迹对于确定关键驾驶参数具有宝贵的参考价值。
主要 6 个参数是为了优化自动驾驶汽车控制。预测范围 𝑁 预测未来的变化,从而实现主动调整。速度维持权重 Q和控制力度权重 𝑅 平衡所需速度和最小控制力度,以实现高效驾驶。车距维持权重 𝑄ℎ 确保与前方车辆保持安全距离,这对于避免碰撞和交通流量至关重要。所需速度 𝑣𝑑 和所需车距 ℎ^𝑑 设定了特定的性能目标。这些参数共同协调安全性、效率和舒适性,增强驾驶体验。
参考内存数据集使用符号𝑀(E/t)封装这些参数,函数 𝑀 将每个场景映射到特定于该场景平均MPC参数元组。
为了构建参考记忆数据集,提取特定特征(例如十字路口、雨天和夜晚)校准 nuScenes 数据集中每个场景的 MPC 参数。每个场景都根据这些特征的组合进行分类,从而产生八种不同的场景(例如,夜晚十字路口的雨天)。然后,进行统计分析,以确定这些场景对在驾驶行为方面是否存在显着差异。如果发现显着差异,则针对每个场景采用不同的平均驾驶参数;如果没有,则将场景组合起来,并使用相同的平均驾驶参数。这种方法可确保参考记忆为各种驾驶条件提供适当定制的参数。
提示生成器
提示生成器从各个模块收集所有相关信息,并为 VLM 生成输入提示。此过程确保 VLM 能够在时间 𝑡 有效地生成六个必要的参数。
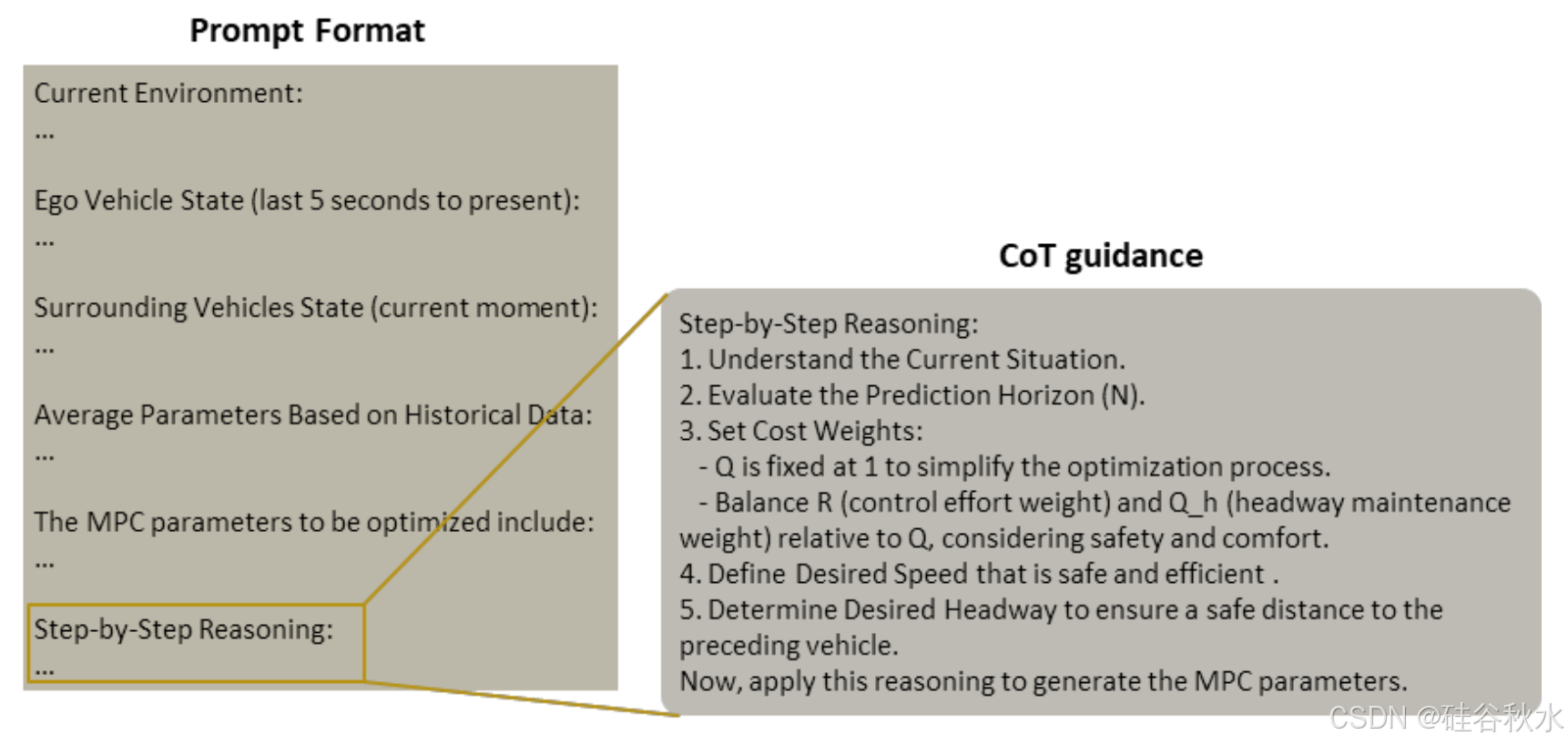
为了生成这些参数,在每个场景的初始调用 VLM 和后续更新期间,构建提示的方式略有不同。对于每个场景,在时间 𝑡=0 时第一次调用 VLM 进行上层决策包括以下输入:记忆 𝑀、前置摄像头帧 𝑖𝑚𝑔/𝑡=0、环境描述 E/𝑡=0,以及本车和前方车辆的状态 𝑠/𝑡=0。
随后以 ∆𝑡u 的间隔调用 VLM 来更新决策,包括前置摄像头帧 𝑖𝑚𝑔/𝑡、环境描述 E/𝑡、本车和前车状态 𝑠/𝑡 以及之前的驾驶参数 𝜃/𝑡−∆𝑡^u。
在提示结束时,利用思维链 (CoT) 提示(呈现一系列逻辑和相互关联的步骤或指令)来帮助 VLM 更好地驾驭现实世界驾驶任务的复杂性并进行类似人类的推理。CoT 指导如图所示。这种方法通过将决策过程分解为可管理的逻辑步骤,增强了 VLM 处理复杂场景的能力,从而提高了动态环境中的整体性能。
在下层 MPC,考虑车辆动力学,包括发动机滞后。基于 VLM 生成的关键参数 𝜃/𝑡,MPC 组件实时优化受控车辆的轨迹。MPC 模型的主要目标是,以预测方式调整车辆的速度和位置来提高交通效率和安全性。此外,它还考虑了交通环境的动态约束和车辆的运行限制,旨在最大限度地减少交通波动对自车以及周围交通流的影响。MPC 使用最新的车辆状态不断更新,并与上层 VLM 一起,此方法有助于实现闭环状态反馈。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









