










25年3月来自清华大学、上海 AI 实验室、上海姚期智研究院和 UCSD 的论文“FP3: A 3D Foundation Policy for Robotic Manipulation”。
继自然语言处理和计算机视觉领域取得成功后,在大规模多任务数据集上预训练的基础模型,在机器人领域也展现出巨大潜力。然而,现有的大多数机器人基础模型,仅仅依赖于二维图像观测,而忽略三维几何信息,而这些信息对于机器人感知和推理三维世界至关重要。本文的 FP3,是一个用于机器人操作的大规模三维基础策略模型。FP3 基于可扩展的扩散 transformer 架构构建,并使用点云观测在 6 万条轨迹上进行预训练。凭借模型设计和多样化的预训练数据,FP3 可以有效地针对下游任务进行微调,同时展现出强大的泛化能力。在真实机器人上的实验表明,仅需 80 次演示,FP3 就能在具有未见过物体的新环境中以超过 90% 的成功率学习新任务,大大超越现有的机器人基础模型。
FP3概述如图所示:

基于学习的策略已在机器人操控领域展现出卓越的效果 [6, 80, 12, 75, 36, 3]。然而,这些学习的策略通常对未知场景、新物体和干扰因素的泛化能力有限,甚至为零 [66]。此外,目前大多数方法都针对单一或少数任务进行训练 [12, 75],需要相对大量的专家演示(通常约 200 个回合)才能学习一项新任务。相比之下,自然语言处理 (NLP) 和计算机视觉 (CV) 在开发基础模型方面取得了显著成功,这些模型基于大规模数据和多样化任务进行训练,使其能够泛化到任意自然场景。因此,在机器人操控领域构建一个类似的基础模型,使其能够泛化到新物体、场景和任务,成为一个极具前景的课题 [36, 39, 3]。
为了实现策略基础模型的这一目标,一些学者对视觉-语言-动作 (VLA) 模型进行初步尝试 [80, 36, 3]。这些模型以基于互联网规模的视觉和语言数据训练的视觉-语言模型 (VLM) 为基础,继承常识性知识,并在大规模机器人数据集上对 VLM 进行微调 [46, 35]。与此同时,RDT [39] 等研究尝试扩展扩散模型以构建基础策略。尽管取得了显著进展,但在面对新任务、新物体、新场景和新摄像机视角等时,它们的泛化能力仍然有限。
当前策略基础模型的一个潜在局限性是它们仅仅依赖于二维图像观测,缺乏三维观测输入。然而,三维几何信息对于感知三维环境和推理空间关系至关重要 [78, 72, 70, 63]。已有研究表明,3D 表征可以提升机器人操作策略的采样效率和泛化能力 [54, 70, 33, 72]。在 RGB-D 图像、点云、体素和 3D 高斯分布等所有 3D 表征中 [34],点云被认为是最有效的 [70]。
本文提出 3D 基础策略 (FP3),一个基于 3D 点云的机器人操作语言-视觉运动策略基础模型,具有强大的泛化能力和采样效率。为了从 3D 点云观测中提取丰富的语义和几何表征,FP3 采用预训练的大规模点云编码器 Uni3D [77]。进一步利用编解码器扩散 transformer (DiT) 架构,将点云表征、语言嵌入和本体感觉相结合,对动作进行去噪。
FP3 是一个 1.3B 的编码器-解码器 Transformer 网络,遵循两阶段预训练和后训练方案。
FP3 模型
FP3 的核心是一个基于扩散的策略模型,类似于 [12, 39]。它以 3D 点云观测数据、语言和机器人本体感受状态作为输入,预测未来动作的动作块。形式化地,将语言条件下的视觉运动控制问题形式化为对分布 p(A_t |o_t) 进行建模,其中 o_t = [P1_t , …, Pn_t , l_t , q_t ] 表示时间 t 的观测数据,包括来自第 i 个摄像机的点云观测数据 P^i_t(含历史观测数据)、语言指令 l_t 和本体感受信息 q_t;A_t = [a_t , a_t+1 , …, a_t+H −1 ] 表示预测的动作块。训练一个去噪扩散概率模型 (DDPM) [21] 来近似条件分布,并使用去噪扩散隐式模型 (DDIM) [55] 方法来加速推理。
FP3 模型的结构,包括多模态输入的编码和基于 Transformer 的编码器-解码器架构。如图所示:
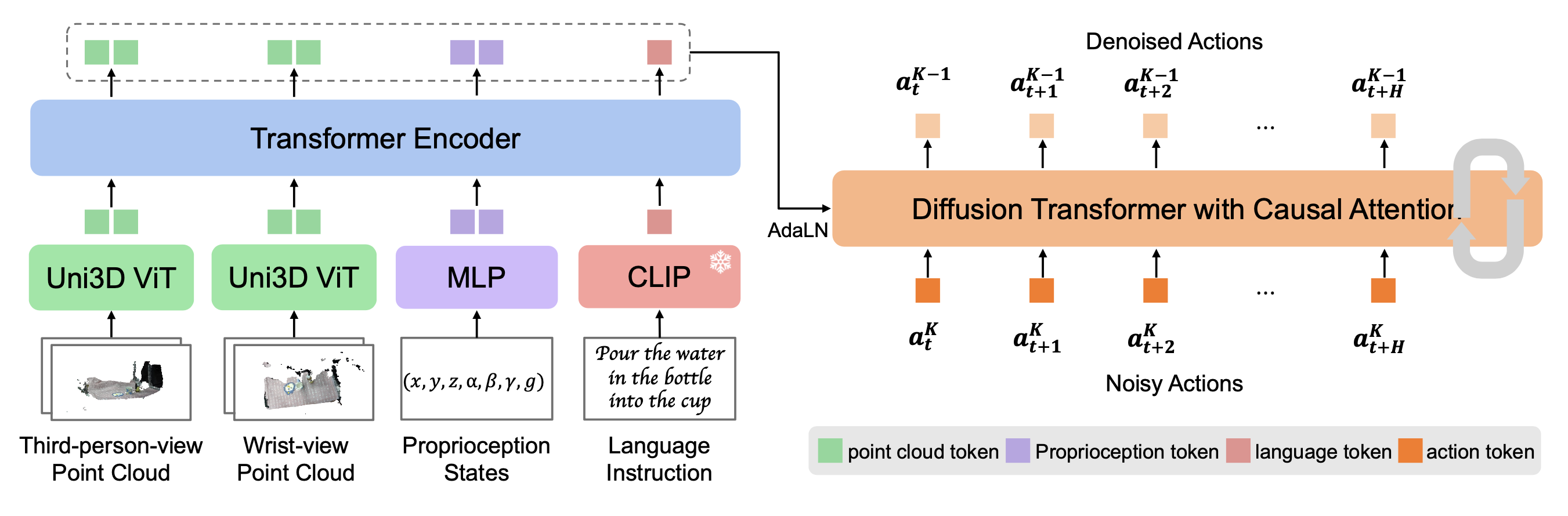
多模态输入的编码。为了处理多模态输入,将输入信号编码到具有相同维度的统一 token 空间中,如下所示:
点云观测包含丰富的语义和几何信息,与其他 3D 表示相比,它更适合策略学习 [70]。因此,考虑在 FP3 中使用点云作为 3D 表示。当前基于点云的机器人策略 [70, 61, 73] 通常使用稀疏点云和小型网络(例如 PointNet++ [49] 和 PointNeXt [50])将点编码为嵌入。然而,预训练的大规模基础视觉编码器,已证明在基于图像的策略中优于小型编码器 [13, 37]。因此,将每个视图的输入点数增加到 4000 个,并使用一个 300M 参数的点云编码器 Uni3D ViT [77],该编码器经过预训练以将 3D 点云特征与图像文本对齐的特征对齐,以获得点云嵌入。对于第三人称视角和腕视点云,使用单独的编码器,因为它们的点分布可能有很大差异。按照 [37],选择在策略训练期间微调 Uni3D ViT 的权重。
语言指令仅使用 CLIP [51] 模型进行编码以与 Uni3D 对齐。由于语言嵌入已经训练有素,因此权重在训练期间是固定的。
包括机器人本体感受状态和噪声水平在内的低维输入分别用双层 MLP 处理。
编码器-解码器结构。鉴于扩散 Transformer 在图像生成 [47, 16] 和策略学习 [79, 15] 中展现出卓越的可扩展性,采用 Transformer 架构,并将其扩展用于 FP3。为了更好地融合点云、语言和本体感受状态嵌入,采用类似于 [75, 74, 52, 15] Transformer 编码器-解码器架构。具体来说,FP3 首先将所有嵌入输入到 Transformer 编码器中,生成一系列信息丰富的潜 tokens。
FP3 的扩散降噪器是一个 Transformer 解码器,它遵循 [79] 的方法,利用时间因果掩码对动作块进行降噪。为了将具有多模态信息的潜 token 注入降噪器,FP3 采用自适应层范数 (adaLN) 模块进行调节,这被发现对于实现图像生成 [47, 16] 和策略学习 [79, 15] 中的扩散训练至关重要。
预训练
预训练数据。为了构建 3D 策略基础模型,需要在大规模 3D 机器人操作数据集上训练模型。然而,大多数现有的大规模机器人数据集,例如 Open X-Embodiment 数据集 (OXE, [46]),主要都是 2D 数据集。因此,在本研究中,使用 DROID 数据集 [35] 对 FP3 进行预训练,该数据集包含 86 个任务和 76,000 个演示,并提供了深度观测数据。最终使用 DROID 中的 60,000 个演示对 FP3 进行预训练。
数据预处理。DROID 使用三个摄像头进行数据采集,而为了方便起见,在 FP3 中仅使用其中两个摄像头,包括一个第三视角摄像头和一个腕视摄像头。使用 RGB 图像和深度图恢复每个摄像头的 3D 点云,并将两个点云转换到同一世界坐标系。由于只关心操作目标,因此裁剪 1 米框外的点以去除冗余点。此通过最远点采样(FPS,[48])将每个点云下采样至 4000 个点,以便在保留足够信息的同时进行模型训练。保留每个点的颜色通道,以便进行以颜色为条件的进一步实验。
预训练细节。根据先前研究 [36, 37] 发现冻结预训练的视觉编码器可能会损害策略性能,在预训练期间对 Uni3D ViT 编码器进行微调。还在训练期间随机丢弃一些点以进行增强,丢弃率在 0 到 0.8 之间随机选择。
使用 AdamW 优化器 [40] 和余弦学习率策略。权重衰减设置为 0.1,梯度裁剪设置为 1.0。 FP3 基础模型使用 8 块 NVIDIA A800 GPU 进行 3M 步预训练,批量大小为 128,耗时约 48 小时。在单块 NVIDIA A800 GPU 上对同一模型进行微调大约需要 2 小时,并且可以通过多 GPU 训练进一步加快速度。
为了处理部分观察结果,将 2 帧数据堆叠作为输入,其中包含 1 步观察历史记录,以补偿缺失的机器人动态信息。
后训练
在获得预训练的基础模型后,进一步采用后训练流程,使用少量高质量数据使模型适应特定任务,这与大多数现代 LLM 实践 [1, 57] 相一致。与大多数现有机器人基础模型所采用的微调设置不同(这些模型要么专注于微调模型以适应新的机器人设置 [36, 58],要么专注于在固定环境中学习新任务 [39, 3]),本文目标是微调模型以解决任何环境中任何物体上的特定任务。
为了实现这一目标,进一步收集机器人设置中每个下游任务的数据。借鉴 Lin [37] 的经验,目标是增强环境和物体的多样性,而不仅仅是增加同一场景中的演示数量。具体而言,对于每个任务,在 8 个环境中分别使用 8 个不同的物体收集 10 个遥操作演示,总共 80 个演示。然后,使用参数高效的微调策略 LoRA [23] 基于这些数据对基础模型进行微调。得益于预训练阶段的有效初始化,这些少量的微调数据能够实现对新环境和新目标的零样本部署。
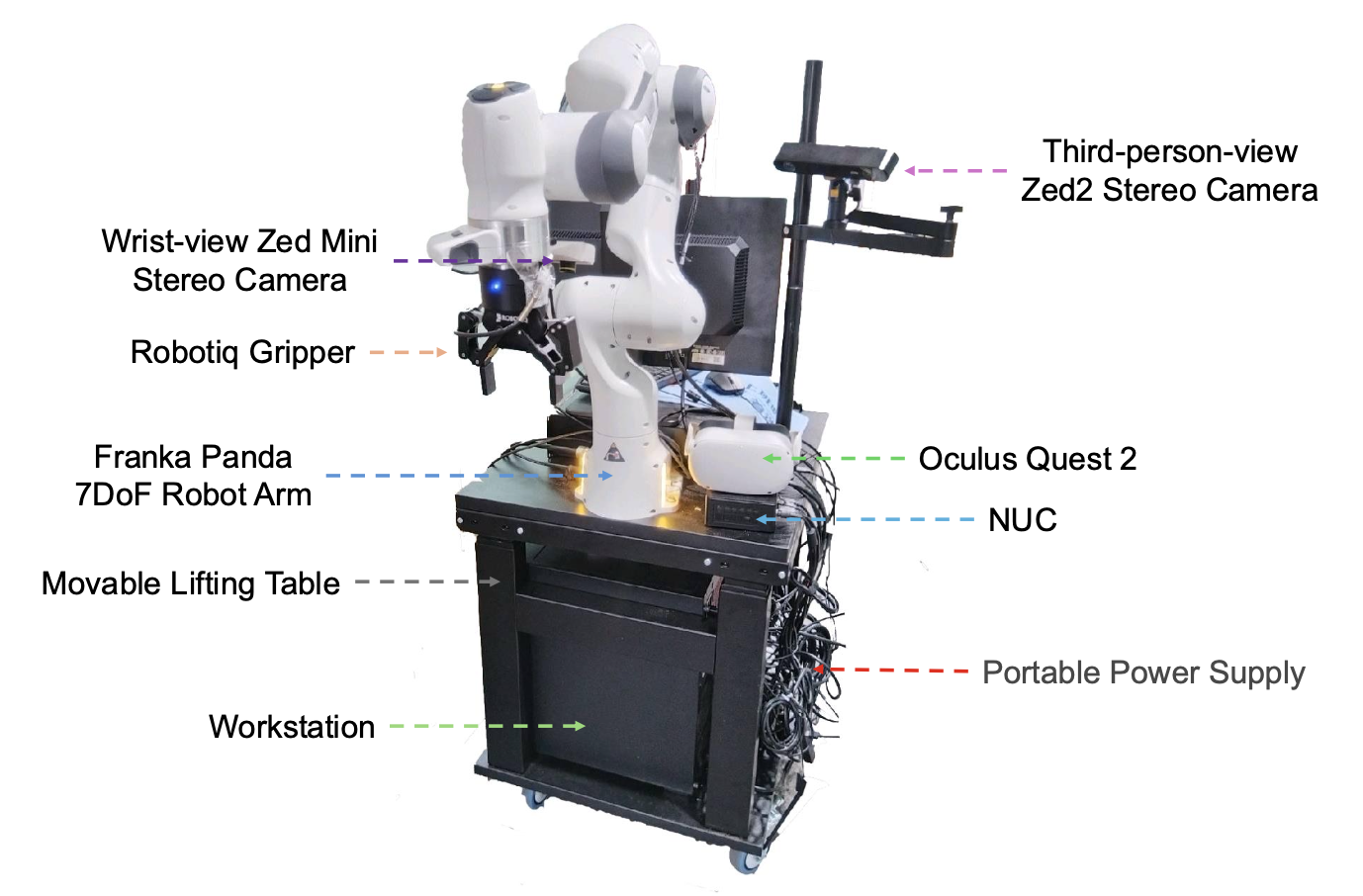
真实的机器人设置。在 DROID 数据集上预训练 FP3 模型时,还构建一个类似于 DROID 的真实机器人设置,用于评估下游任务。该设置包含一个 Franka Emika Panda 机械臂,配备 Robotiq 机械手,安装在可移动的桌面上。为了进行点云观测,使用一个 ZED mini 摄像头(腕部视角)和一个 ZED 2 摄像头(第三人称视角)。为了收集数据,使用 Meta Quest 2 VR 头显来遥操作机器人。将绝对笛卡尔空间控制记录为策略训练和部署的动作空间。
如图所示:所有策略评估均在 RTX 3090 GPU(24GB VRAM)上执行。所有设备均由移动电源 (EcoFlow DELTA 2 Max) 供电。
选择四个下游任务来评估模型和基线:
折叠毛巾:在平面上从右向左折叠一条长毛巾。
清洁桌面:拿起一张揉皱的纸并将其放入桶中。
立杯:将杯子竖直放置在平面上。
倒水:拿起一个水瓶,将水瓶中的水倒入杯中,然后将水瓶放在杯垫上。
如图展示这四个任务的流程:

为了全面评估 FP3,精心选择三条基线:
扩散策略 (DP) [12]:一种经典的基于扩散模仿学习策略,采用二维图像观测。
DP3 [70]:DP 的替代版本,它将二维图像观测转换为三维点云,并设计一个轻量级编码器来对点云进行编码。
OpenVLA [36]:一种最广泛使用的基于图像视觉-语言-动作 (VLA) 模型。
这三条基线分别代表一个小型二维策略、一个小型三维策略和一个大型二维基础策略。对于 DP 和 DP3,以与 FP3 相同的方式添加一个语言调节模块来融合语言指令。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









