










25年4月来自ETH、Mimics Robotic 和微软研究院的论文“MAPLE: Encoding Dexterous Robotic Manipulation Priors Learned From Egocentric Videos”。
大规模以自我为中心的视频数据集,捕捉各种场景中的各种人类活动,为人类如何与目标交互提供丰富而详细的洞察,尤其是那些需要细粒度灵巧控制的物体。这种复杂、灵巧的技能和精确的控制,对于许多机器人操作任务也至关重要,但传统的数据驱动机器人操作方法往往无法充分解决。为了弥补这一差距,本文利用从大规模以自我为中心的视频中学习的操作先验,来改进灵巧机器人操作任务的策略学习。MAPLE,是一种灵巧机器人操作方法,它利用丰富的操作先验来实现高效的策略学习,并在各种复杂的操作任务上实现更好的性能。具体而言,预测手部与物体接触时的手部-物体接触点和详细的手部姿势,并使用学习的特征来训练下游操作任务的策略。实验结果证明 MAPLE 在现有模拟基准以及一系列设计的高难度模拟任务中的有效性,这些任务需要精细的物体控制和复杂的灵巧技能。
MAPLE 如图所示:
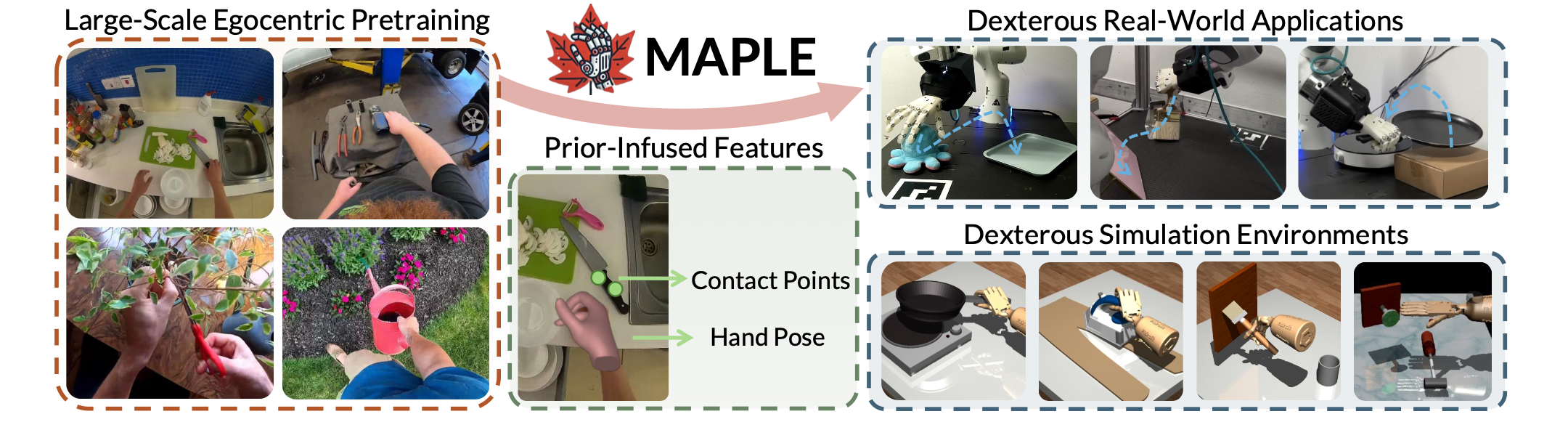
随着机器人系统在各个领域的应用日益广泛,灵巧操作逐渐成为一项关键能力,它超越基本自动化,使机器人能够增强人类的能力,并在动态的现实环境中自主运作。设想一个家用机器人负责准备一顿简单的饭菜,比如番茄酱意大利面。为了完成这项任务,机器人必须与各种厨房物品互动——找到锅、往锅里倒水,然后放在炉子上煮。在这种情况下,机器人会接触到各种各样的日常物品,其中许多物品需要复杂的灵巧操作技能。强大的灵巧操作先验知识,对于在现实世界中成功执行这些任务至关重要。那么,教会机器人灵巧操作技能的最佳信息来源是什么呢?
最近,计算机视觉界对以自我为中心的视角越来越感兴趣[9, 15, 16, 26, 64],因为它为理解人类与物体的交互提供了独特的视角。大规模的以自我为中心的数据集,尤其能够捕捉各种物体类别中手与物体交互的复杂灵巧动态。因此,这些数据集非常适合直接从自然的人与物体交互中学习物体操作先验。近期的几项研究 [32, 40, 53, 55] 通过在大量以人类为中心的视频上训练视觉表征来探索这一方向。然而,这些方法通常缺乏对灵巧操作的明确关注,并且往往难以泛化,尤其是在以人为中心的环境中,因为细粒度控制至关重要 [3, 11, 46, 47]。
灵巧操作。灵巧操作是指用多指手对物体进行操作。由于动作空间维数高且物理交互复杂,灵巧操作是机器人技术中最具挑战性的任务之一。传统的灵巧操作方法通常依赖于使用模型 [6] 或优化 [61, 63] 的解析型抓取规划方法。然后,使用合适的任务空间控制器以开环前馈方式执行这些抓取方案。虽然这种模块化方法具有更大的灵活性,但在处理部分观察的环境或需要适应性以及视觉和控制紧密耦合时面临挑战。因此,最近的研究探索使用数据驱动的端到端技术(如强化学习 RL)来学习操作策略 [43, 60, 68, 69]。强化学习提供一种强大的工具来学习鲁棒的灵巧操作策略,但其性能在很大程度上依赖于模拟精度以及合适的奖励公式,而这些公式的制定可能颇具挑战性。这引发了人们的研究兴趣,并催生模仿学习 IL [5, 22, 28, 70],它直接利用人类的演示作为监督信号。虽然大多数此类方法能够学习有意义的操作策略,但它们在不同任务中的泛化仍然有限——通常依赖于大量特定于任务的轨迹才能用于新任务。
从以自我为中心的视频中学习。大规模人工记录的视觉观察已被广泛用于提取机器人操作的嵌入或运动先验。现有的方法大致可分为隐式方法和显式方法。隐式方法 (IM) [31, 32, 35, 40] 利用大规模对比学习从以自我为中心的交互数据中获取有意义的特征。一些研究,例如 [31, 32, 66],利用大规模视频数据集来学习目标条件值函数 [31] 或训练掩蔽自编码器 (MAE) [32, 66]。此外,像 [40] 这样的方法通过在图像和语言模态之间应用对比损失来集成语言嵌入。然而,由于其隐式特性,这些方法不能直接用于机器人操作。相反,它们预训练的(冻结的)嵌入可作为强化学习 [66] 或模仿学习 [40] 算法的输入。相反,显式方法(EM) [1, 2, 21, 34, 39] 旨在通过将人机交互作为显式监督信号,直接从视频中学习交互 affordance。这些方法通常预测交互轨迹 [39]、接触热图 [1, 21, 34] 或未来的接触点和手腕位置 [55]。虽然它们的输出可以直接用于特定于任务的控制器,但由于操作任务的复杂性,大多数方法在策略学习中使用最终预测或中间嵌入。虽然显式监督有助于学习更适合的潜在空间,但大多数现有方法侧重于高级交互,并且主要设计用于简单的双指操作。此外,它们通常依赖于人工注释的数据,从而限制可扩展性。
机器人模拟器中的评估。根据所用末端执行器的类型对模拟基准进行分类。诸如 MetaWorld [67]、Franka Kitchen [14, 17] 和 Habitat 2.0 [56] 之类的基准专注于平行钳口夹持器,定义的任务包括物体操作、烹饪相关活动和家庭环境重新布置任务。 DeepMind 控制套件 [57] 还包含抽象环境中的基本物体操控任务。对于三指夹持器,TriFinger [65] 提供物体操控的基准,尤其能够评估真实和模拟环境中的玩具魔方任务。最后,灵巧手基准测试提供了更复杂的操控挑战。DAPG [47] 为模拟的 Adroit [24] 手引入四种环境,而 DexMV [44] 则包含倾倒、物体重新定位和基于目标的移动等任务,需要更细粒度的控制。许多基准测试的一个关键限制,是它们依赖于低自由度夹持器,这限制了它们评估细粒度操控策略的能力。
现实世界中的评估。在机器人领域,模仿学习正在成为执行灵巧操作任务的标准方法 [5, 7, 12, 70],甚至推动了基础模型式通才机器人策略的开发,这些策略可以使用来自小样本的目标数据进行微调 [23, 58]。这是因为它能够从任务演示中学习,而无需模拟环境或特定于任务的奖励。然而,这些模型主要在低自由度夹持器上进行训练和部署。此外,对于灵巧操作器 [36],由于设计之间差异很大,因此没有标准数据集。
为什么学习可泛化的灵巧操作先验仍然如此具有挑战性?虽然在大型数据集上训练的通用表征,能够捕捉丰富的场景级细节 [4, 45],但它们缺乏对操作相关线索的明确关注,因此并非最优。其他自监督学习方法(例如使用对比损失进行训练的 VIP [31])难以有效地从以自我为中心的视频中提取灵巧操作信息,尤其是由于这些视频中描绘的真实场景复杂且杂乱无章。这就引出了一个关键问题:一个为物体操作而设计的视觉编码器,应该学习提取哪些具体信息?假设低级交互线索,特别是物体接触点和抓握手势,可以为下游的灵巧操作任务提供强大的先验知识。
为此,引入 MAPLE,从以自我为中心的视频中学习灵巧操作先验知识以用于机器人操作。关键见解是设计学习目标,以指导表征有效地捕获灵巧操作知识。更具体地说,专注于训练一个视觉编码器,旨在提取在操作过程中与物体交互的位置和方式。利用现有的最先进方法自动提取用于训练的监督信号,大大降低了数据集获取的成本。给定一张目标物体的图像,MAPLE 学习预测手部与物体的接触点以及接触时刻的三维手势。
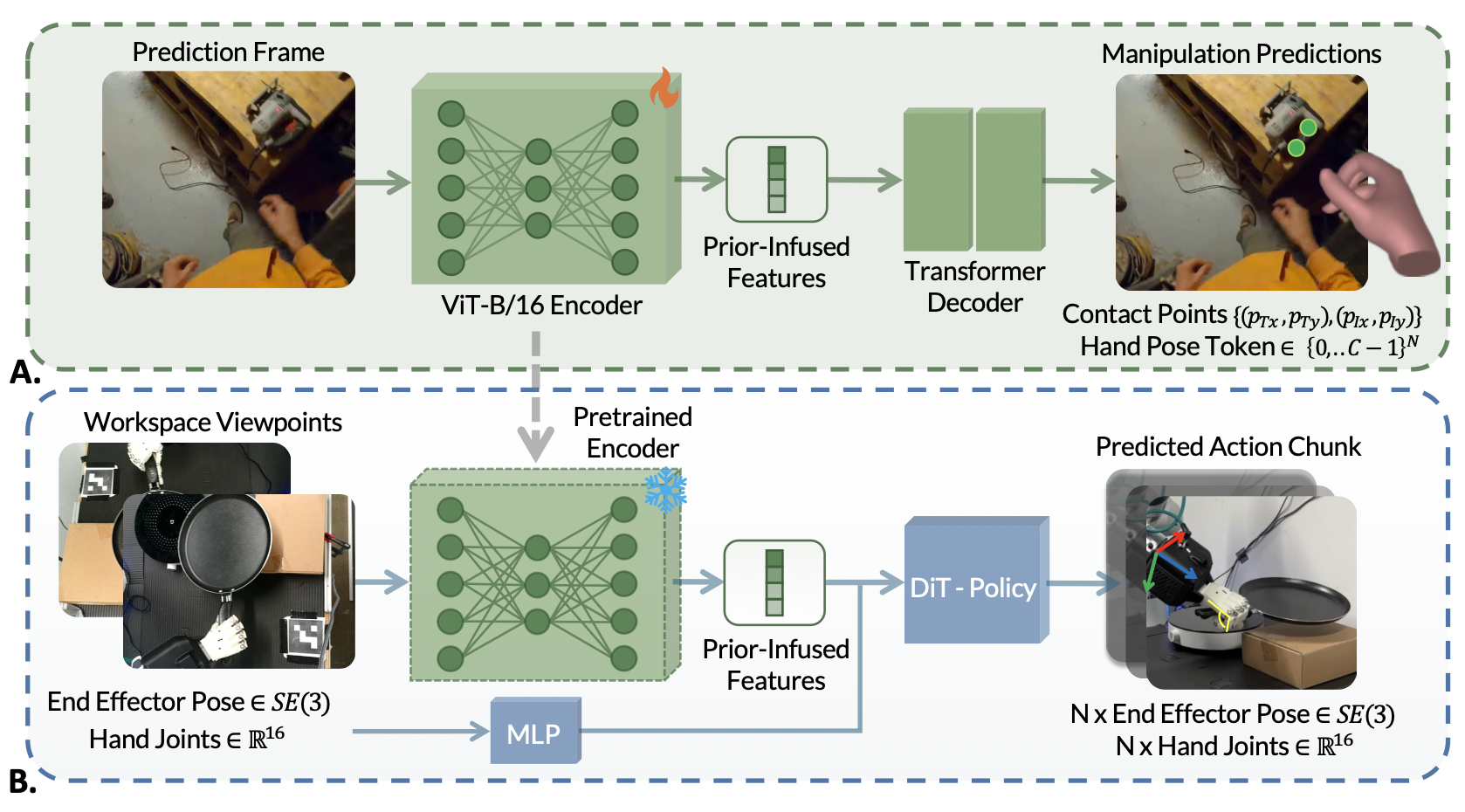
MAPLE 流程涉及解决两个关键问题:如何对操作先验进行建模并从自我中心视频中提取相应的标签,以及如何从提取的标签中学习这些先验。如图展示整个流程。
从视频中提取操作标签
MAPLE 旨在从大型公开的以自我为中心的视频数据集中学习对灵巧操作有用的特征。为了有效地表示操作先验,考虑手与物体之间的接触点,以及接触时刻对应的 3D 手势。使用现成的工具自动解析这些手与物体的交互并提取相关的训练标签。
具体来说,定义一个接触帧 f_c,它标记手首次接触物体的时刻。还定义一个预测帧 f_p,它在视频中出现的时间早于 f_c,即手与即将进行交互的物体之间距离足够远的时候。从接触帧 f_c 中提取表示交互手的手势向量 H_c。利用 H_c,进一步提取接触点 pt_c,然后回溯到 f_p,以获得预测帧上的未来接触点 pt_p。如图直观地显示标签提取过程。
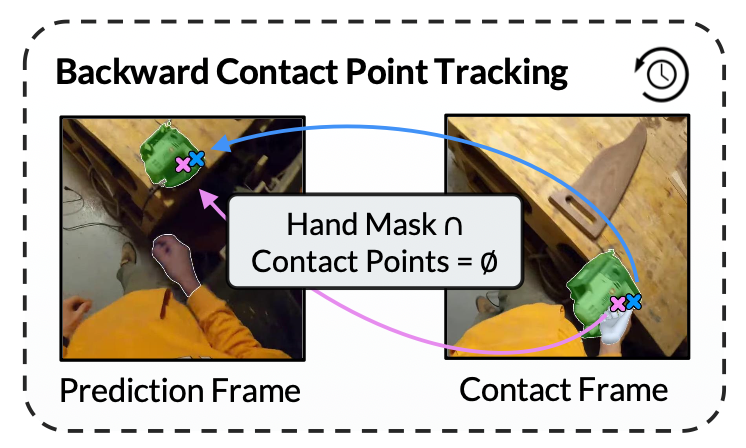
从接触帧中提取接触监督。为了定位接触时刻,使用现成的手-物体接触分割模型 [10] 处理数据集中的所有帧,并将第一个接触帧视为 f_c。为了避免从相邻的接触帧中提取相同的 f_p,仅处理在最后 δ_min = 90 帧中没有其他 f_c 的接触帧。
将接触点 pt_c 定义为拇指和食指指尖在物体上首次接触的点。对于每个接触帧,使用预训练的手势估计模型 [42] 提取交互手的姿势向量,从而得到 MANO [50] 手势 H_c。提取出的 H_c 通过一个 MANO 层进行转发,以获得二维指尖关键点。然后,将拇指和食指指尖关键点投影到物体掩码上以获得 pt_c。在计算投影指尖点的位置时,使用一个略小的物体掩码,其中一部分边界已通过 n_e = 12 次二元侵蚀 [52] 操作擦除。这有助于下一步在预测帧中查找接触点。
从预测帧中提取监督。为了识别预测帧 f_p,我们运行一个点跟踪器 [48],将接触点在视频时间中向后投影,直到找到手部掩码尚未与物体掩码相交的第一帧。使用较小的物体掩码进行接触点识别,有助于防止点跟踪器追随操作手的手指而不是物体。在检查相交时,通过 n_d = 75 次二元膨胀 [52] 迭代扩展物体掩码,以确保从物体到手有足够的距离。这有助于使接触点回归比简单地将物体定位在手的紧邻位置更简单。先前的研究 [1, 55] 从手与被操作物体产生的边框交集处随机采样接触点,这很容易导致错误的结果,例如当手触摸凹面物体时从背景中采样点。相反,将指尖投影到被操作物体的掩码上,以提取精确的接触信息。
手势 token 化。学习预测与抓握目标物体相关的手势,是一项具有挑战性的任务,因为它需要符合解剖学约束,并推理具有大量关节的复杂运动树。此外,关节配置空间的较大子集会导致手势表现出自渗透性。将预测任务简化为分类任务,让模型从有限的“合理频繁(reasonably frequent)”(即在视频中观察的)且解剖学上正确的手势列表中选择手势,而不是自行回归正确的手势。为此,利用 HaMeR [42] 从 Ego4D 随机选择的子集中提取手势数据,训练一个手势 token 化器。使用与 4M [37] 中人体手势 token 化器相同的基于 Memcodes [33] token 化方案,即 8 个大小为 1024 的码本,分别表示一个 MANO [50] 手势。
编码操作的先验
目标是通过推理从以自我为中心的视频中提取的人-物体交互,来训练一个专门用于灵巧操作的视觉编码器。使用编码器-解码器结构作为学习有用表征的基石:编码器将输入的预测帧处理成嵌入向量,然后解码器使用这些向量预测接触点和未来的手势。解码器完全依赖于编码器的嵌入(其维数远低于输入图像)来推断其输出。这种瓶颈设计鼓励编码器生成专门针对目标操作相关预测的信息,而不是学习生成“通用”视觉嵌入 [4, 45]。
接触点预测。在预测框 f_p 中采用交叉熵损失学习预测接触点 pt_p。为此,将图像的宽度 w 和高度 h 分别离散为 B_x 和 B_y bins,让解码器预测接触点应落入的相应 bin 索引。在实验中,设置 B_x = 100 和 B_y = 100。将一个样本和一个接触点 pt 的接触损失 L_con,pt 公式化如下:
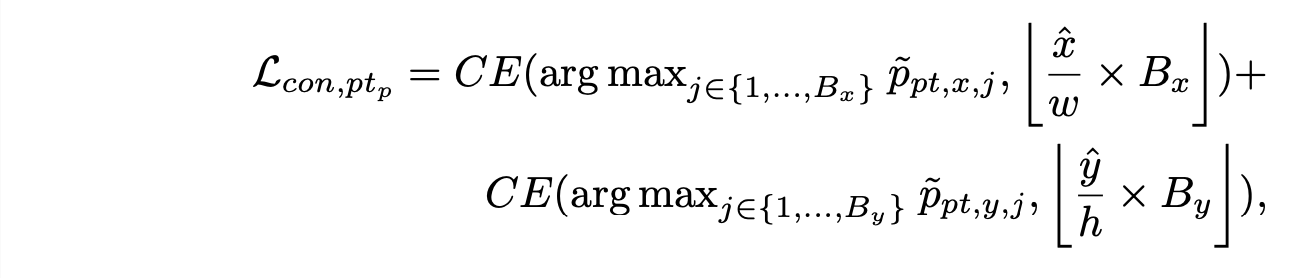
手势预测。在 MAPLE 的训练过程中,让解码器预测 token 序列中每个手势 token 的概率分布,然后使用得分最高的 token logit 来确定最终用于重建手势的 token。与接触点预测类似,也使用交叉熵损失函数。具体来说,使用 一个 token 化程序处理 MANO 手势 H,将姿态转换为一个 token t_n。令 p ̃_n 为解码器用于估计 t_n 的 logit 预测。则损失公式 L_hand 为:
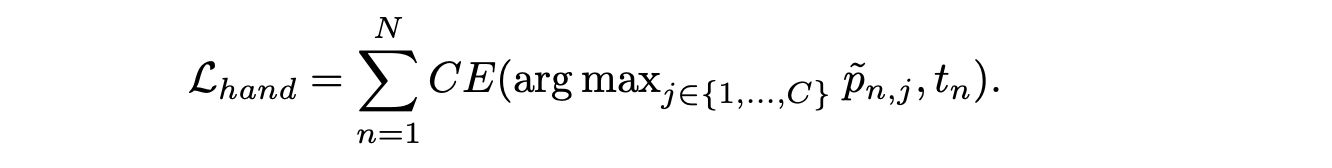
确保时间独特性。假设输入特征的时间独特性对策略学习的成功至关重要。需要注意的是,初始权重是从 DINO [4] 中复制而来的,由于 DINO 的对比训练目标,它提供了高度独特的视觉先验。为了保持这种独特性,可以优化一小组参数,例如 ViT [13] 主干网络中 LayerNorm [25] 模块的参数,这些参数会以较小的幅度改变表征,并保留先验的独特性。或者,可以在训练期间使用时间对比损失 [41],以便在面对更剧烈的变化时保持独特性。这两种方法在先前的研究 [40, 55] 中都已被探索过,并被整合到 MAPLE 中,即 MAPLE-LN(只训练 LayerNorm 参数)和 MAPLE-AP(训练所有参数)。
对于给定视频 v_m 中在位置 j 的帧 f_jv_m,遵循 [40] 中采用的 InfoNCE 目标,将来自不同视频(f_jv_m 和 f_lv_n,v_m 不等于 v_n)或时间上更远(f_iv_m 和 f_jv_m,i < j < k)的帧表征分离开,同时将来自同一视频中相近帧(f_iv_m 和 f_j^v_m,i < j)的表征合在一起:
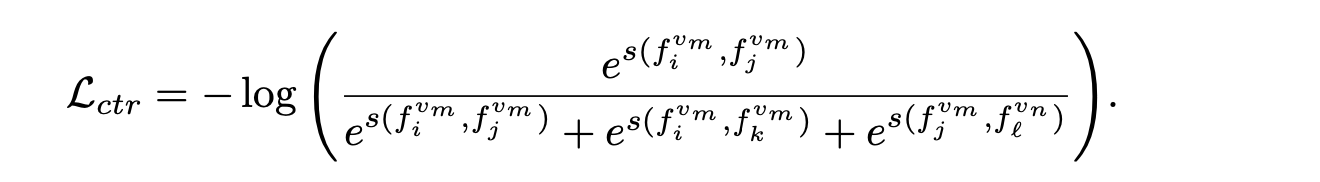
实现细节。与其他 ViT [13] 衍生的基线 [4, 32, 55] 类似,采用 ViT-B/16 作为编码器架构。编码器使用 [4] 的权重初始化,并生成维度 d = 768 的视觉特征。为了确保公平比较并评估监督训练过程的贡献(而不是架构的选择),不会选择更大或更复杂的主干网络。使用 Transformer [62] 解码器模型,该模型有 2 个 Transformer 层,每层有 4 个注意头。编码器和解码器使用 AdamW [30] 优化器联合训练,学习率为 5 × 10−5。训练 MAPLE-LN 时使用的批量大小为 128,训练 MAPLE-AP 时使用的是 512。
仿真和真实环境实验如下。
实验设置
训练数据。在 Ego4D [15] 上运行提取流程,该流程包含超过 3,000 小时的无脚本人类活动,涵盖各种场景(例如园艺、锻炼和烹饪)。为了确保公平比较,遵循 [40, 55] 中既定的协议,并选择相同的子集(涵盖约 1,590 小时的视频)来提取数据。流程从该子集中生成约 82,100 个训练样本。
基线编码器。针对常用的通用视觉编码器 DINO [4] 以及四种专为机器人操作设计的最先进 (SotA) 编码器进行评估:
• DINO [4]:一种自监督视觉编码器,使用对比损失对图像及其提取的图块进行训练。
• R3M [40]:一种机器人操作基线,在图像上使用时间对比损失,并使用另一种对比损失估计任务完成情况,该损失基于与图像对的视觉特征匹配的视频摘要。
• HRP [55]:一种针对机器人操作设置进行训练的视觉编码器,使用从手部与物体边框交集中提取的接触点以及使用 FrankMocap [51] 提取的手腕轨迹。
• VC-1 [32]:一种针对各种具身智能任务的视觉编码器,使用掩码自编码器 [20] 范式在大量图像上进行训练。
• VIP [31]:一种用于机器人操作的视觉编码器,使用一种隐时间对比目标。
对于所有基于 ViT [13] 的方法,即 DINO、HRP 和 MAPLE,都采用 ViT-B/16 [13] 主干网络。R3M 和 VIP 使用 ResNet50 [19] 主干网络。使用公开可用的权重初始化所有基线。
仿真实验评估
现有的模拟环境和任务。首先评估来自现有DAPG [47]基准套件的四个任务。这四个任务包括开门、使用锤子、旋转笔和移动球(如图所示)。

新的环境和任务设计。进一步引入一组新的、由四个定制设计的、具有挑战性的评估任务,这些任务侧重于需要更精细控制的灵巧操作。具体来说,在MuJoCo模拟器[59]中设计三个任务,这些任务需要使用灵巧手[24]对工具进行复杂的灵巧操作。这三个任务都涉及一个放置在桌子上的物体,灵巧手悬停在物体上方并可以自由移动(可视化效果见上图)。这些任务是:(1) 平底锅:拿起平底锅并将其放在附近炉灶的电磁炉板上;(2) 刷子:从杯子中取出刷子,然后在附近的画布上涂抹; (3) 熨斗:抓住桌上熨斗的把手,沿着旁边裤腿滑动。
收集新任务的演示。为了符合文献 [31, 40] 中既定的评估标准,使用 Rokoko Smartgloves [49] 为每个任务记录 25 个专家演示,采用 [44] 中的算法将人手姿势重定位到模拟中的 Adroit 手。
实验方案。评估同时使用现有任务和新设计的任务。为了评估给定视觉编码器在给定任务上的表现,基于 MLP 的策略 [40] 经过训练,以在给定本体感受输入和来自视觉编码器的特征的情况下控制模拟中的机器人手。在总共 20,000 个训练步骤中,每 1,000 个步骤对策略进行一次评估,每次评估包含模拟器中的 50 次部署。在每次部署期间,都会随机化目标的位置和/或旋转。该策略会收到一个二进制分数,指示它是否根据特定于环境的成功标准(例如打开门)完成预期任务。然后,编码器在该任务上的得分就是所有 20 次评估中的最佳平均成功率。遵循先前的工作 R3M [40],通过另外计算三个摄像机视图的得分来计算编码器在任务上的得分,每个视图的三个随机种子用于改变策略网络的初始化,每个编码器和任务总共进行九次实验。这种平均过程有助于提高评估的统计稳健性。对于定制设计的任务,采用 750 个时间步长的时间范围。为了模拟不完美的执行效果并增加任务难度,在生成的动作中添加高斯噪声。
真实环境中的评估
任务设计。真实环境评估包含两个源自模拟任务的任务,以及一个新任务:(1)毛绒玩具:机器人拾起一个毛绒玩具并将其放置在托盘上,评估其对编码器训练期间未见过的、独特形状物体的鲁棒性。(2)平底锅:机器人抓住平底锅的把手,将其举起并放置在电磁炉上。放置完成后,机器人松开把手。(3)刷子:机器人拿起刷子,将其移动到目标框架,并在其表面进行刷洗动作,然后将刷子放在桌子上。这是最具挑战性的任务,它既考验抓取精度,也考验精细操作的灵活性。
硬件设置。机器人装置包括一个安装在Franka Emika Panda机械臂[18]上的Mimic机械手[36, 60],以及两个外部摄像头。使用 Rokoko Smartgloves 和 Coil Pro 动作捕捉系统 [49] 收集演示,这套系统可以从演示者的手指和手腕提供本体感受位置数据,外部摄像头记录视觉数据。如图所示:

实验方案。在使用自我中心视频进行训练后,冻结编码器以确保稳定的特征提取,并使用提取的特征进行操作策略训练。对于实际实验,采用扩散策略框架 [5] 来预测机器人动作,并使用扩散transformer (DiT) [12] 作为模型架构。视觉输入由训练有素的编码器处理,并将其嵌入与本体感受数据相结合。具体而言,末端执行器姿势和手指关节角度被转换成 token,并与图像 token 连接起来,然后再传递到 DiT。使用 DDiM [54] 作为噪声调度程序,训练期间有 100 步,推理期间有 8 步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









