










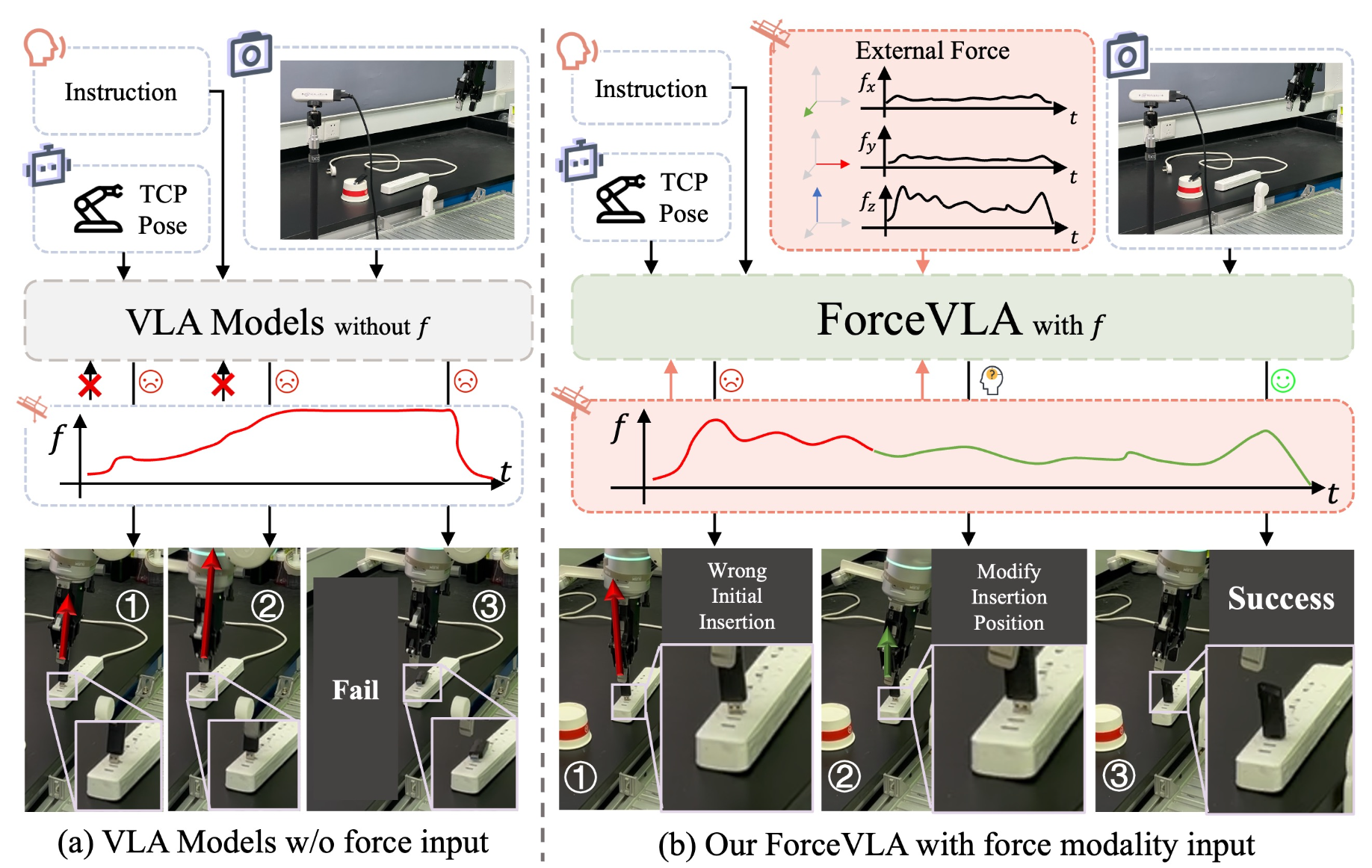
25年5月来自复旦、上海交大、新加坡国立、上海大学和西交大的论文“ForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-rich Manipulation”。
视觉-语言-动作 (VLA) 模型利用预训练的视觉和语言表征,提升通用机器人操控性能。然而,它们在处理需要精细控制力的接触密集型任务时却举步维艰,尤其是在视觉遮挡或动态不确定性的情况下。为了突破这些限制,ForceVLA,一个端到端操控框架,将外部力感知视为 VLA 系统中的一级模态。ForceVLA 引入 FVLMoE,这是一个力-觉察专家混合融合模块,可在动作解码过程中动态地将预训练的视觉语言嵌入与实时 6 轴力反馈进行集成。这使得跨特定模态专家的上下文-觉察路由成为可能,从而增强机器人适应细微接触动态的能力。还推出 ForceVLA-Data,这是一个数据集,包含五个接触密集型操控任务中的同步视觉、本体感觉和力-扭矩信号。与基于 π0 的强基线相比,ForceVLA 将平均任务成功率提高 23.2%,在诸如插入插头等任务中成功率高达 80%。
随着具身人工智能 (embodied AI) 的兴起,在大规模操作数据集和基础模型 [1, 2, 3] 的推动下,机器人学习取得了快速发展。这些模型表现出强大的适应性,能够在极少的监督下快速推广到新任务 [4, 5, 6]。与此同时,视觉-语言模型 (VLM) 通过大规模多模态对齐 [7, 8] 实现了卓越的泛化能力,学习到可迁移的表征,从而支持广泛的下游任务。
在此基础上,OpenVLA [9] 引入视觉-语言-动作 (VLA) 模型,为现实世界的机器人操作架起感知和控制的桥梁。通过利用基于 VLM 的编码器,这些模型在语义基础、语言跟随和零样本泛化方面展现出强大的性能。 π0 [10] 使用更强大的 VLM 主干 [11] 和基于流的动作生成进一步增强该框架,表明预训练的多模态 VLA 模型可以获得稳健的物理世界先验,并且只需少量演示即可进行高效微调。
然而,接触丰富的操作,需要的不仅仅是语义基础和空间规划——它从根本上是由相互作用力驱动的 [12, 13]。现有的 VLA 模型严重依赖视觉和语言线索,往往忽略力感知,而这个是实现精确物理交互的关键模态。相比之下,人类会自然地整合触觉和本体感受反馈来调整其操作策略 [14]。因此,VLA 模型经常难以完成插入、使用工具或组装等任务——尤其是在遮挡或视觉条件较差的情况下——导致行为脆弱或任务失败。此外,力的需求会随着任务的不同阶段而变化:精细的抓握、受控的插入和柔顺的表面接触——每个阶段都需要不同形式的力调节。当前的方法缺乏感知和适应这些动态变化的机制,限制了它们对物理交互进行长期推理的能力。
为了突破这些限制,引入 ForceVLA,它通过力-觉察混合专家 (MoE) 模块增强了 VLA 模型,从而能够在接触丰富的操作任务中进行有效的推理,并生成情境敏感、基于力的动作,如图所示。
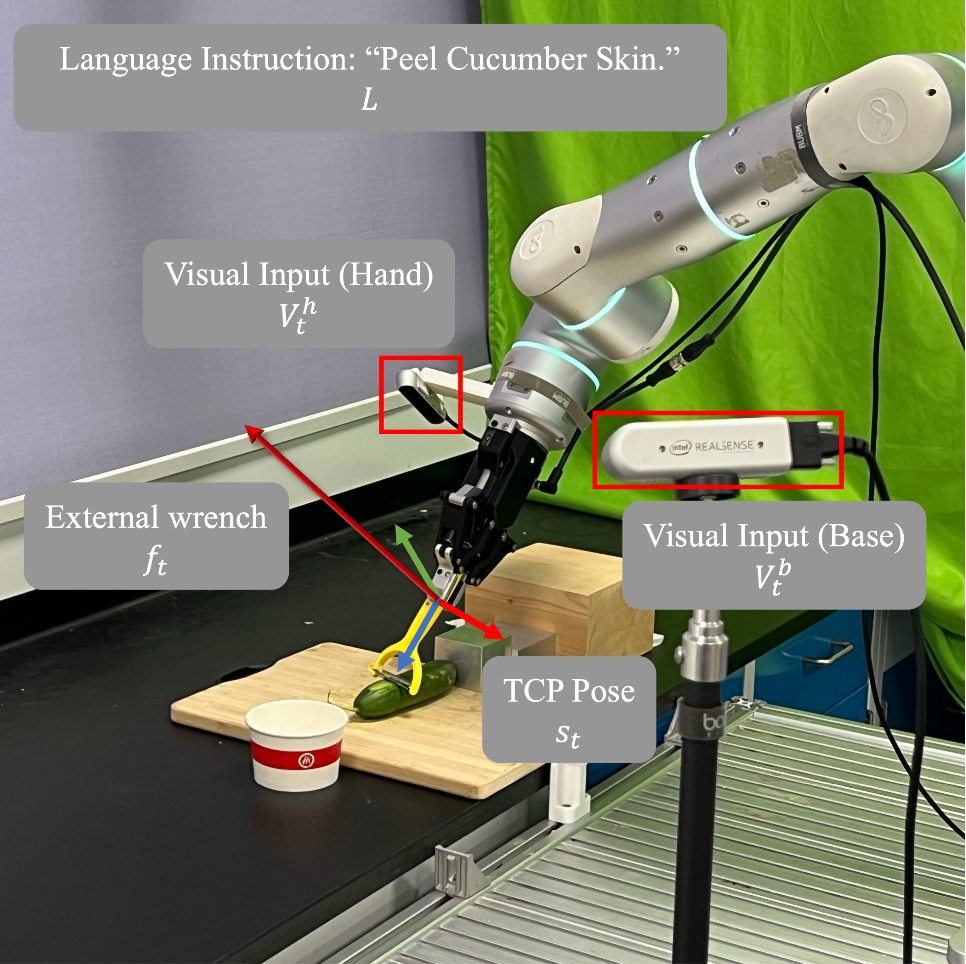
问题表述。如图显示机器人操作任务的设置。机器人在时间步 t 的观察,包括基础和手部视觉输入 V_tb 和 V_th、本体感受状态 s_t 以及外部力-扭矩读数 f_t,它们统称为 O_t = {V_tb, V_th, s_t, f_t}。给定一条语言指令 L,目标是学习一个端到端策略 π(A_t|O_t,L),该策略输出低级、可执行动作块 At = {a_t, a_t+1, …, a_t+H−1}[10],最大化完成富含接触任务的可能性,其中 s_t 是与夹持器宽度连接的 TCP 姿态向量。TCP 位置用笛卡尔坐标 (x, y, z) 表示,方向用欧拉角 (α, β, γ) 表示。 f_t 是施加于 TCP 估计的外部扳手,以世界坐标系表示,由力和力矩组成:f_t = {f_tx,f_ty,f_tz,m_tx,m_ty,m_tz}。
MoE 架构。选择混合专家 (MoE)[44, 42] 作为融合层。其核心思想是将不同的模态分布到一组规模较大、专门化的“专家”子网络中,对于任何给定的输入 tokens,只有一小部分子网络被激活。MoE 层通常包含一组 N 个专家网络(记为 {E_i})和一个门控网络(也称为路由器),记为 G。该网络接收输入 tokens x,并动态确定应从 N 个专家中挑选出哪一个来处理它。在流行的稀疏 MoE 实现中,对于输入 tokens x,门控网络 G(x) 会生成分数或对数函数,用于从 N 个专家池中选出一小部分专家(通常为 k = 1 或 k = 2,其中 k ≪ N)。然后,输入token x 仅被路由到这 k 个活跃专家。这些活跃专家的输出 E_i(x) 随后被聚合,通常通过加权和的方式进行,其中权重 g_i(x) 也来自门控网络。MoE 层的最终输出 y(x) 可以表示为:y(x) = sum_i∈TopK(G(x)) g_i(x)E_i(x),其中 TopK(G(x)) 表示门控网络针对输入 x 选取的前 k 名专家索引集。
ForceVLA 概述
ForceVLA 是一种端到端多模态机器人策略,专为接触式操作而设计。其流程如图所示。它基于 π0 框架 [10],集成了视觉、语言、本体感受和 6 轴力反馈,通过条件流匹配模型 [48, 49] 生成动作。来自多个 RGB 摄像头的视觉输入和任务指令由基于 SigLIP [50] 的视觉语言模型(基于 PaliGemma [11])编码为上下文嵌入。这些嵌入与本体感受和力反馈相结合,形成一个迭代去噪过程,用于预测动作轨迹。
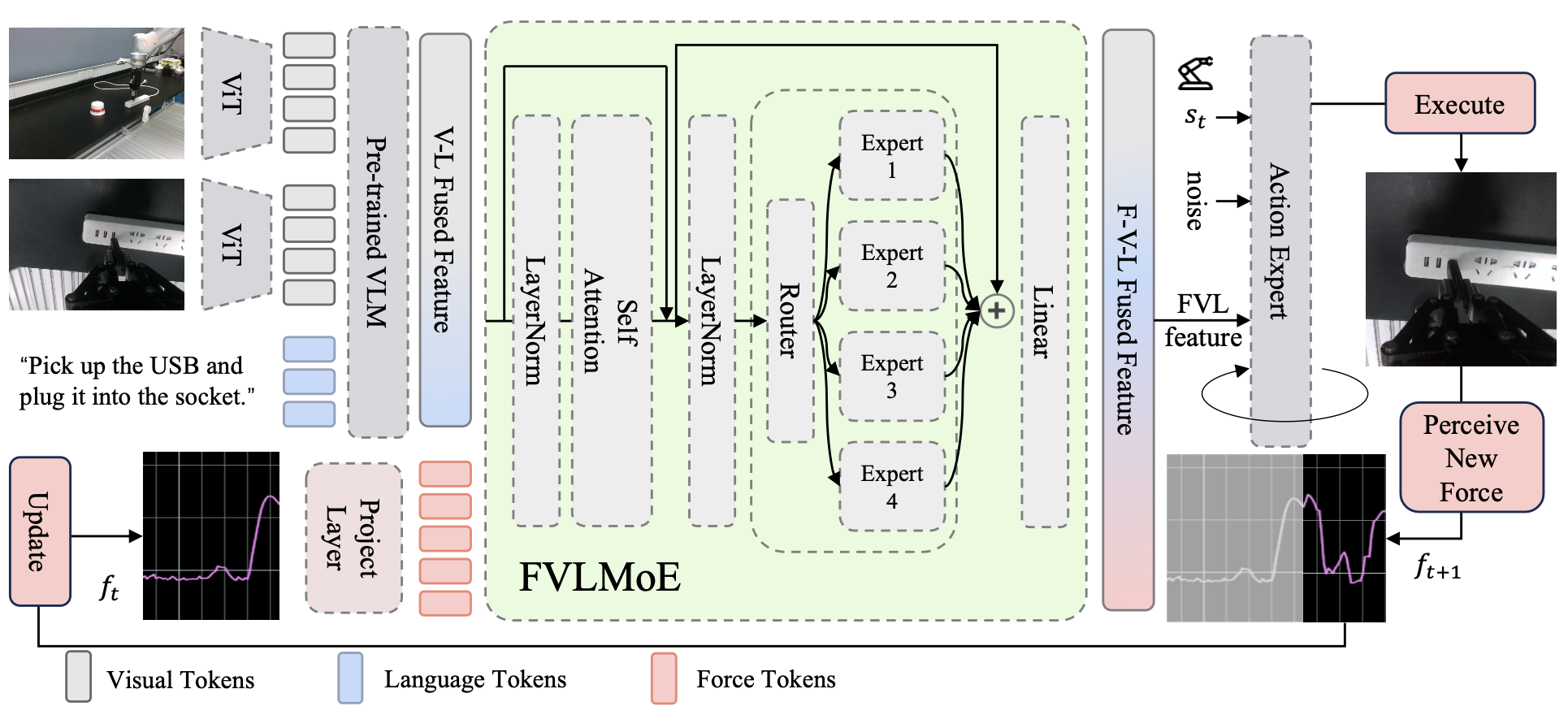
FVLMoE 是实现有效力集成的核心模块。力读数被线性投影到专用 token 中,并通过混合专家 (MoE) 模块与视觉语言嵌入融合。受 MoE 在多任务和模态特定学习方面的优势 [51, 46] 的启发,FVLMoE 能够自适应地路由和处理多模态输入。其输出为流模型提供丰富的引导信号,使 ForceVLA 能够以更高的精度和鲁棒性处理细微的接触动态和视觉模糊场景。
FVLMoE 架构
FVLMoE 模块专为融合多模态感知信息而设计。其设计使模型能够将来自视觉和语言的丰富上下文理解与力-力矩(force-torque)传感器捕捉的即时、细粒度的动态信息相结合。这种融合对于在接触丰富的操作任务中实现鲁棒性和自适应行为至关重要。FVLMoE 的架构和操作可分为以下几个阶段:
多模态输入映射。如何确定引入力模态的最佳阶段和方法是一项重大的设计挑战。经过大量实验,我们建立了一种方法,在主 VLM 处理完视觉和语言输入后再引入力模态。具体来说,力特征作为独立输入被馈送到 FVLMoE 模块,使其功能类似于高级皮质关联区域,负责将 VLM 预训练的视觉语言表征与新引入的力 token 进行整合。这种策略与在 VLM 初始融合视觉和语言模态之前或同时引入力形成对比。
FVLMoE 模块遵循此设计选择,接收由视觉语言特征和专用力 token 串联而成的 tokens 嵌入序列 E_in。VL 特征(表示为 E_VL)是主要视觉语言模型的输出,封装从处理后的图像流和文本指令中获得的上下文理解。同时,原始的六轴力-扭矩传感器数据 f_raw 通过线性投影 φ_F 转换为力 token 嵌入 E_F = φ_F(f_raw)。因此,FVLMoE 的最终输入是连接序列 E_in = [E_VL ; E_F],其中力 tokens 附加到视觉语言上下文中,以便在 MoE 架构中进行后续联合处理。
多模态路由与融合计算。组合的多模态序列 E_in 形成后,将在 FVLMoE 模块中进行分层处理。E_in 经过编码器层进行共享细化,以促进所有组成力、视觉和语言 tokens 之间的整体交互。该编码器层由多头自注意机制(包含 N_heads 个注意头)和一个后续的 FFN(最终神经网络)组成,最终得到 E_enc。随后,E_enc 被引导至稀疏的混合专家层。该层采用 E = 4 个不同的专家网络,每个网络都实现为一个独立的多层感知器 (MLP)。动态门控网络确定路由,根据学习到的调度权重,为 E_enc 中的每个 token 选择最合适的单个专家(前 k 个专家 = 1 个)。然后,MoE 计算的输出通过残差连接与 MoE 层的输入进行集成,得到 E_fused。最终的融合多模态特征序列将通过最终的线性投影层,以匹配动作专家的维度。
将融合特征注入动作流头。F_VLMoE 模块生成的融合多模态特征序列,作为动作生成过程的指导信号,该过程被表述为基于流的去噪模型。该指导首先通过提取特定子序列 G_FVLMoE 来实现,该子序列包含来自 E_FVLMoE 的最终 H_action tokens;这些 tokens 封装 H_action-length 动作规划中每个步骤最相关的融合指导。通过逐元加法将 G_FVLMoE 与 S_suffix 合并。S_suffix 是由主 VLM 在去噪步骤 τ 时处理当前本体感受机器人状态 s_t 和噪声动作轨迹 a^τ_t 得到的,D_s 和 D_a 分别是状态空间和动作空间的维度。这种加法注入机制确保 FVLMoE 所构建的丰富的、接触-觉察的上下文理解,能够直接调节和优化预测轨迹每一步所生成的动作序列。
数据集
为了训练 ForceVLA,挑选一个专门针对接触密集型操作任务的新数据集,强调视觉、本体感受和力矩数据的同步采集。现有数据集通常缺乏全面的力相互作用或开发稳健力-觉察策略所需的接触驱动场景多样性。
用配备 Dahuan 自适应夹持器的 Flexiv Rizon 7 自由度机械臂进行数据收集。视觉数据由两台 RGB-D 摄像头采集:一台静态第三人称视角(RealSense D435,分辨率 1280x720,帧率 30 FPS)和一台腕戴式摄像头(RealSense D415,分辨率 640x480,帧率 30 FPS),提供以自我为中心的视角。数据通过人类远程操作收集,使用 Quest3 VR 界面,并自定义映射到机器人末端执行器控制。五位专业操作员共执行五项不同的高接触任务:抽水瓶、插入插头、插入U盘、擦拭白板和剥黄瓜。对于每项任务,操作员都被要求在确保交互模式多样化且成功的前提下完成目标。在演示过程中改变物体的位置和方向,以增强数据多样性。
最终生成的数据集(称之为ForceVLA-Data)包含244条轨迹,总计14万个同步时间步。所有传感器数据流均基于时间戳同步。图像尺寸调整为 480x640 像素并进行归一化。动作以目标 TCP 姿态和夹持器宽度表示。
为了评估 ForceVLA 的有效性,针对五项接触性操作任务进行了实验:抽瓶、插入插头、插入 U 盘、擦拭白板和剥黄瓜,如图所示。选择这些任务是为了评估机器人的精细控制能力、对不同初始条件的适应性以及多模态反馈(尤其是力感知)的实用性。每项任务都带来了独特的物理挑战:抽瓶需要精确的垂直按压;插入插头和 U 盘需要精确的对准和力控插入;擦拭白板需要平滑的轨迹控制和表面接触;剥黄瓜则测试机器人在持续的表面交互过程中施加和保持受控力的能力。
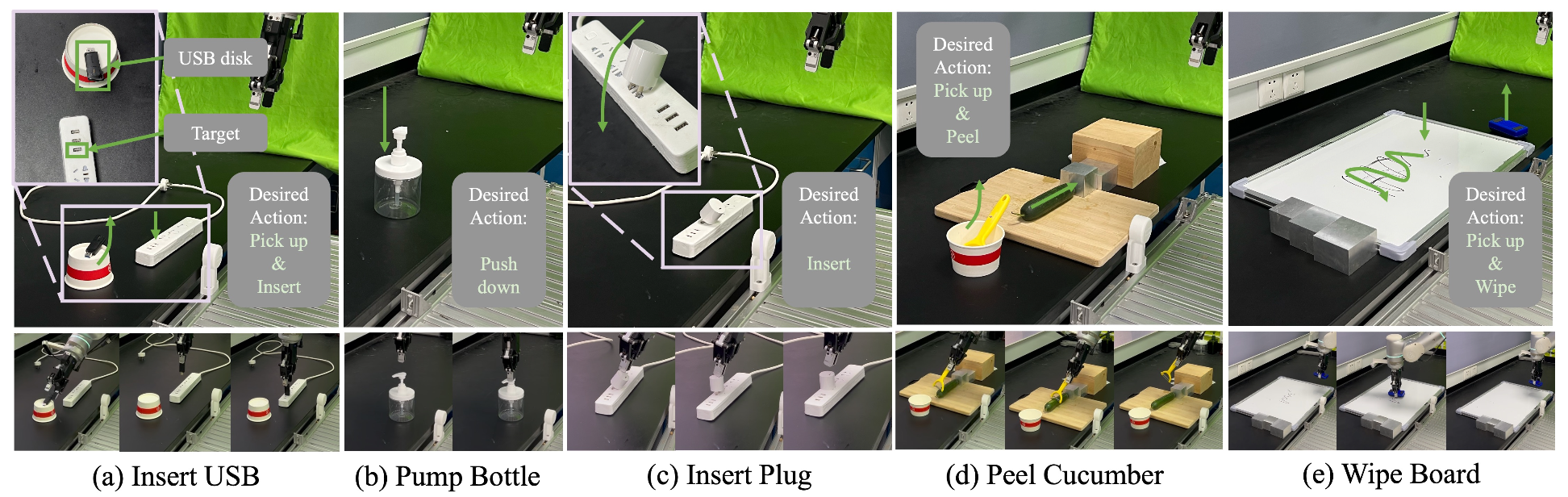
对每项任务使用大约 50 个专家演示来训练 ForceVLA。插入和抽瓶任务分别进行了 20 次试验,耗时的白板任务进行了 10 次试验,而剥黄瓜任务则进行了 15 次试验,每次试验涉及 15 次剥黄瓜动作。成功的定义取决于特定任务的标准,例如完全插入、有效的擦拭动作或大量的累积剥离覆盖率。这些任务旨在严格探索 ForceVLA 通过整合视觉、语言和力模态来建模和控制复杂、不确定动态的能力。
评估指标和基准。模型性能主要通过其在所有五个具有挑战性的、接触丰富的操作任务中的任务成功率来评估。对于像黄瓜剥皮这样的具体任务,还报告平均剥皮长度和最短剥皮时间,以提供更细致的评估。为了更好地理解 ForceVLA 模型的性能,将其与几个精心挑选的基准进行了比较,这些基准源自基于最先进 π0[10] 架构的基础模型。具体变型包括 π0-base[10] w/o F(标准 π0,无力模态输入)、π0-base[10] w/ F(力信号直接连接到状态输入的 π0),以及相应的 π0-fast[25] 配置(w/o F 和 w/ F),这些变型代表潜在的更快替代方案。选择 π0-base[10] 可以与现有的强大 VLA 方法进行比较,而“inputForce”变型对于证明 FVLMoE 融合策略优于更简单的力积分方法至关重要。
数据收集系统如图 (a) 所示。该装置配备一个机械臂,该机械臂配备腕式摄像头和静态第三人称视角摄像头,用于捕捉不同的视觉视角。操作员佩戴 Quest 3 头显并使用手持控制器远程操作机械臂。附近的计算机运行着数据采集所需的软件,其中包括用于与机器人交互、同步传感器流以及管理与 VR 远程操作硬件通信的程序。图 (b) 展示了操作员远程操作机械臂以收集擦板任务的演示数据。

模型主要在配备 8 个 NVIDIA RTX 4090 GPU(每个 24 GB VRAM)、64 个物理 CPU 核心和 251 GB 系统 RAM 的计算节点上进行训练,使用 Adam 优化(β_1 = 0.9,β_2 = 0.95),峰值学习率为 2.5 × 10−5,在 30,000 步内衰减至 2.5 × 10−6。多任务训练利用跨 2 个 GPU 的数据并行性(全局批次大小为 16,通过梯度累积有效值为 2048),由于通信开销导致额外 GPU 带来的收益递减,多任务训练在 ∼12 小时内完成 30,000 步;单任务训练使用 1 个 GPU 进行 10,000 步(∼9 小时)。两者均采用 bfloat16 精度并进行梯度剪裁(||∇|| = 1.0)。
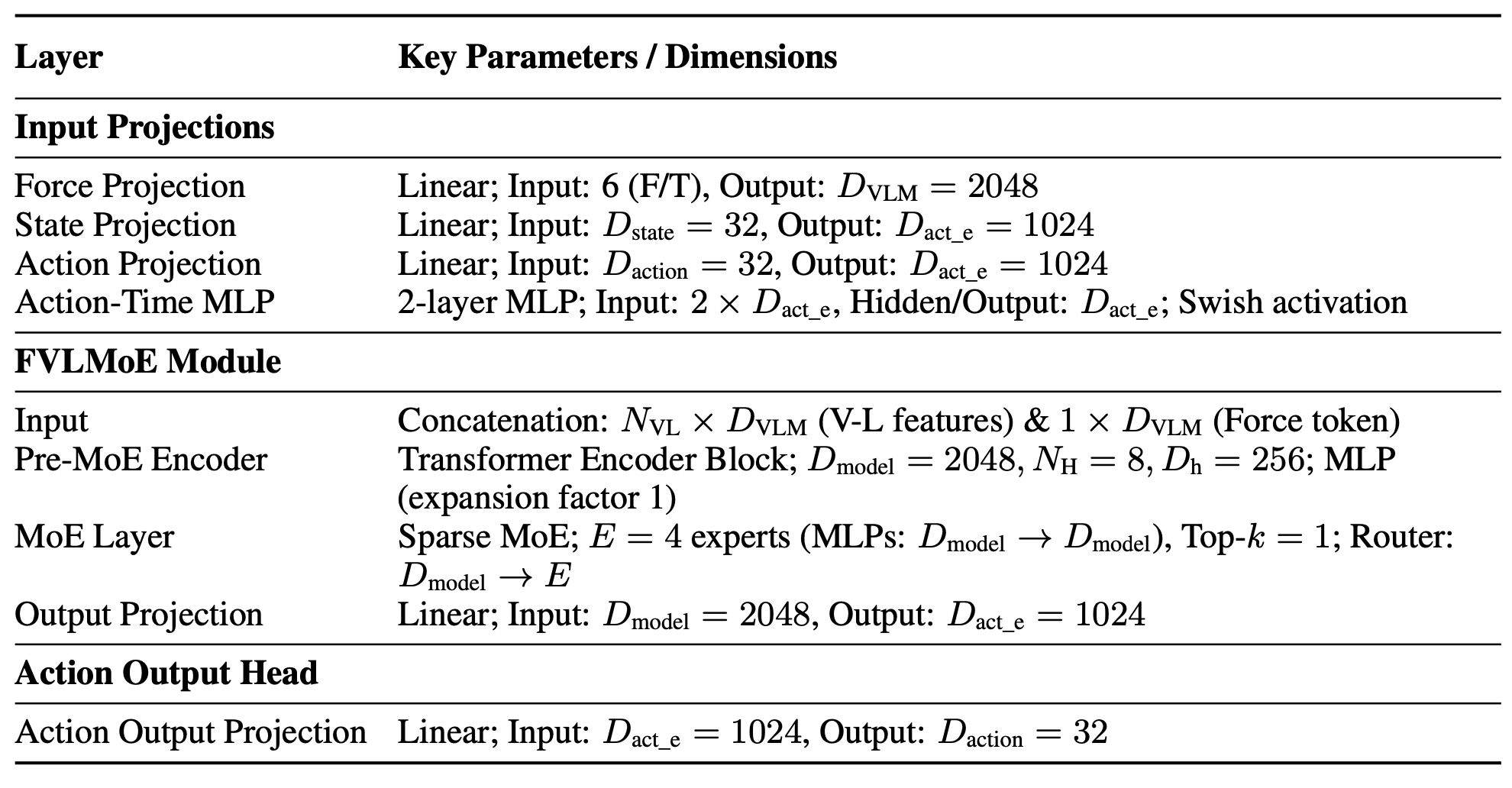
ForceVLA 核心处理模块的维度和关键参数:输入投影、FVLMoE 块和动作输出头详见下表。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









