










2024年3月麻省Amherst、上海交大、南方科技大学、MIT、UCLA和MIT-IBM AI实验室的论文“3D-VLA: A 3D Vision-Language-Action Generative World Model”。
最近的视觉-语言-动作(VLA)模型依赖于2D输入,缺乏与3D物理世界更广泛领域的集成。此外,学习从感知到动作的直接映射,这样做行动预测,忽略了世界的巨大动态性以及行动和动态性之间的关系。相比之下,人类被赋予世界模型去描绘未来场景的想象,并据此规划行动。3D-VLA,引入一系列具身基础模型,通过生成世界模型将3D感知、推理和动作无缝连接起来。具体而言,3D-VLA建立在基于3D的大语言模型(LLM)之上,并引入一组交互tokens来与具身环境互动。此外,为了将生成能力注入到模型中,训练了一系列具身扩散模型,并对齐到LLM中,用于预测目标图像和点云。为了训练3D-VLA,从现有的机器人数据集中提取大量的3D相关信息来选取出一个大规模的3D具身指令数据集。
最近,得益于互联网上数十亿规模的数据集,VLM在各种任务中表现出了非凡的熟练度。类似地,包括视频-动作对的百万级数据集为机器人控制的具身VLM奠定了基础。然而,它们大多不能在机器人操作中提供深度或3D注释和精确控制,这需要包含3D空间推理和交互。如果没有3D信息,机器人很难理解和执行需要3D空间推理的命令,比如“把最远的杯子放在中间的抽屉里”。
为了弥补这一差距,构建一个大规模的3D指令调优数据集,该数据集提供了足够的3D相关信息以及成对的文本指令来训练模型。设计一个流水线,从现有的具体数据集中提取3D语言-动作对,获得点云、深度图、3D边框、机器人的7D动作和文本描述的注释。
如图是一些3D指令调优数据集例子:

考虑到超过95%具身任务的视频数据集不提供3D信息,在数据集的视频每帧使用ZoeDeep(Bhat,2023)。此外,为了更好地利用视频数据,用RAFT(Teed&Deng,2020)进行光流估计。光流有助于完善生成的数据。因此,对于摄像机姿态不变的视频片段,用光流来估计哪些像素是未移动的背景。在同一视频的不同帧上对齐这些背景的深度图,将每一帧的深度图乘以一个系数以确保深度一致性。在获得深度图后,可以用相机的内参和姿态外参直接将RGB-D图像提升到3D点云中。
需要生成几个与3D相关的注释:目标的3D边框、目标(goal)图像、深度或点云作为想象的结果,以及机器人在3D空间中的动作。首先提取场景中目标的3D边框。这样的信息可以有利于3D模型捕捉3D信息并关注被操纵目标以进行更好决策的能力。作为源的具体数据集,提供文本指令来描述机器人执行的命令。用spaCy(Honnibal&Montani,2017)来解析指令,获得所有名词块,包括被操纵的目标。用预训练的基础模型,例如基础SAM(Ren et al.,2024)来获得每个目标的2D掩吗。当提升到3D时,这些2D掩码对应于点云的一部分,能够获得空间中所有目标的3D边框。选择遮码时,将基于显著光流区域中的最高置信度值来选择操纵目标。由于已经重建深度和点云,可以在未来的帧中使用图像、深度和点云和作为真值目标。对于操作,用所提供数据集中的7个DoF操作。
受(Li2023a;Peng2023)的启发,生成由tokens组成的密集语言注释(例如,; ),这些tokens包含之前生成的3D注释(边框、目标图像/深度/点云、动作)。然后,用带tokens的预定义语言模板将这些3D注释构建为提示和答案。按照(Hong et al.,2023)方法,用基于ChatGPT的提示来使提示多样化。具体来说,为ChatGPT提供指令,以及注释目标和边框。还提供了2-3次少样本人工演示,指导GPT生成数据类型。ChatGPT被要求总结信息,并将模板生成的提示重写为更多样的形式。对于没有预定义模板的任务,ChatGPT还被要求自行生成提示和答案。
如图是3D-VLA的流水线:左侧部分显示目标生成能力;模型可以根据用户的输入来想象最终的状态图像和点云。然后,可以将生成的目标状态反馈给模型,指导机器人控制。
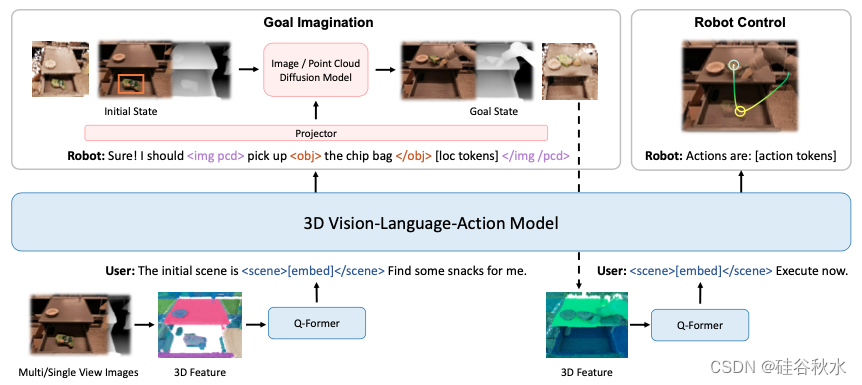
3D-VLA是一个用于具身环境中的三维推理、目标生成和决策的世界模型。首先在3D-LLM之上构建主干(Hong,2023),并通过添加一系列交互tokens来进一步增强模型与3D世界交互的能力。接下来,首先预训练具身扩散模型并使用投影器来对齐LLM和扩散模型,将目标生成能力注入3D-VLA。
在第一阶段,根据3D-LLM的方法开发3D-VLA基础模型(Hong,2023)。由于收集的数据集没有达到从头开始训练多模态LLM所需的十亿级规模,因此遵循3D-LLM的方法,利用多视图特征生成3D场景特征。这使得视觉特征能够无缝集成到预训练的VLM中,而不需要自适应。同时,3D-LLM的训练数据集主要包括目标(Deitke et al.,2022)和室内场景(Dai et al.,2017;Ramakrishnan et al.,2021),与具身设置不直接一致。因此,选择不加载3D-LLM预训练模型。相反,用BLIP2-PlanT5XL(Li,2023b)作为预训练模型。在训练过程中,解冻tokens的输入和输出嵌入,以及Q-Former的权重。
为了增强模型对3D场景的理解并促进这些环境中的交互,引入了一组交互tokens。首先,考虑包含在解析的句子中(例如, a chocolate bar [loc tokens] on the table)的目标tokens ,以便模型能够更好地捕捉被操纵或引用的目标。其次,为了更好地用语言表示空间信息,设计一组用于落地参考目标的位置tokens ,以AABB形式表示的3D边框六个tokens。第三,为了更好地使用这个框架对动力学进行编码,引入 tokens来封装静态场景的嵌入。通过在场景tokens上进行组合,3D-VLA可以理解动态场景并管理3D场景和文本交织的输入。
通过一组扩展的、表征机器人动作的专用tokens,可进一步增强该架构。机器人的动作有7个自由度,由离散的tokens表示,如, 和<gripper0/1> ,代表手臂的预期绝对位置、旋转和抓握器打开度。这些动作由tokens 做分隔。
人类预先可视化场景的最终状态,以便于行动预测或决策,这是构建世界模型的一个关键方面。此外,在初步实验中,提供基本事实的最终状态可以增强模型的推理和规划能力。然而,训练MLLM来生成图像、深度和点云是不容易的。首先,视频扩散模型并不是为具体的设置量身定制的。例如,当要求Runway(Esser,2023)在给出“打开抽屉”指令的情况下生成未来的帧时,整个场景在很大程度上会发生视图变化、意外的目标变形、奇怪的纹理替换以及布局失真。同样,使用DreamLLM(Dong,2023)的方法直接冻结在互联网数据上训练的SD模型,可能导致输出崩溃。第二,如何将各种模态的扩散模型纳入一个单一基础模型仍然是一个挑战。因此,建议将生成图像、深度和点云的能力注入3D-VLA。首先根据不同的模态(如图像、深度和点云)对具体的扩散模型进行预训练,然后通过对齐阶段将这些扩散模型的解码器与3D-VLA的嵌入空间对齐。
为了解决当前在具身环境目标生成(goal generation)扩散模型的局限性,训练RGB-D-到-RGB-D以及点云-到-点云的扩散模型。利用选取的3D-语言视频数据来训练条件扩散模型,该模型根据指令编辑初始状态模态,以生成相应的最终状态模态。这些模型的具体训练细节如下:对于RGBD-到-RGBD的生成,采用SD V1.4(Rombach et al.,2022)作为预训练模型,因为在预训练的VAE潜在空间中操作时,SD生成图像的效率和质量(Kingma&Welling,2013)令人满意。将RGB潜变量和深度潜变量连接起来作为图像条件。类似地,对于点云-对-点云生成,用point-E(Nichol et al.,2022)作为预训练模型,添加点云的条件输入。
在对扩散模型进行预训练后,配备各种解码器,这些解码器可以在其模态中调节潜空间来生成目标。关于如何将预训练的解码器无缝地结合到LLM中,使3D-VLA能够生成关于以输入指令为条件的任何预训练模态的目标,仍然存在挑战。为了弥合LLM和不同模态扩散模型之间的差距,在3D-VLA中开发了一个对齐阶段。图像和点云的tokens设计来告诉解码器输出的类型,在封装的tokens之间,监督LLM生成给机器人操作的指令,包括目标和位置tokens。
基于此,应用基于transformer的投影器,它能够将解码器特征和嵌入从LLM映射到扩散模型的空间中。它在增强模型理解和生成多模态数据的能力方面发挥着至关重要的作用,建立了高级语言支持和多模态目标生成之间的联系。为了提高训练3D-VLA的效率并避免灾难性遗忘,利用LoRA(Hu,2021)来微调不同的扩散模型。同时,只训练新引入的特殊tokens嵌入、相应的嵌入输出线性层和整个投影器,训练目标是最小化LLM和扩散模型去噪损失。
用预训练的BLIP-2Flant5作为骨干。在预训练阶段,在6×32 V100s上训练30个epochs的3D VLA,并验证每个epoch。在训练期间,每个节点上的批处理大小设置为4。此外,在最初的1K步中对学习率进行线性预热,从10−8增加到10−5,然后进行余弦衰减,最小学习率为10-6。在对齐阶段,在6×64 V100s上训练3D VLA,最多20个epochs。在每个节点上将批量大小设置为2进行训练。用AdamW优化器,其中beta1=0.9,bet2=0.999,权重衰减设为0.05。用分布式数据并行(distributed data parallel)模式来训练模型。
为六个任务的数据生成给出问题模版如下表所示:

下图是基于chatGPT数据生成的提示:

如图是生成的RGB-D图像例子:
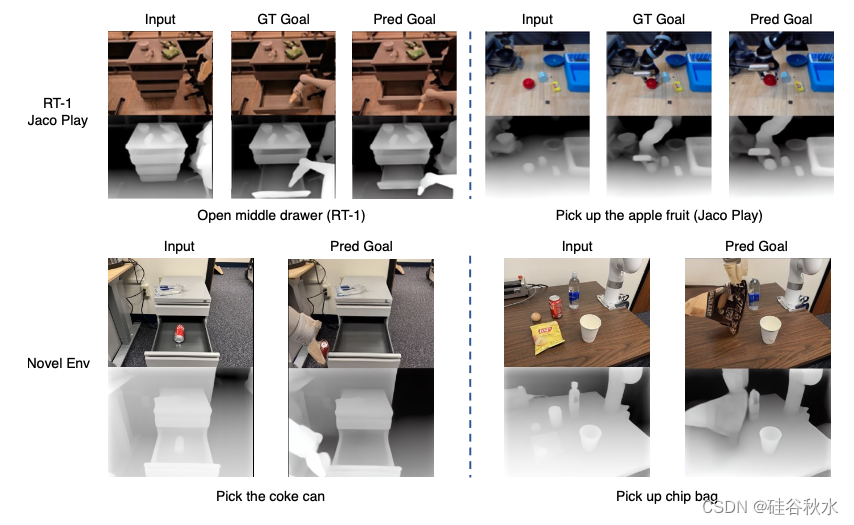
如图是生成的RGB-D图像和点云例子:



















 157
157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









