






回顾
之前讲了Z统计量。
Z统计量的总体逻辑是:假设H0成立,建立群体均值的正态分布。正态分布的均值是总体均值,标准差是
σ/n−−√
,
σ
一般用
s
估计。这时候,根据样本的均值算出样本均值在群体均值正态分布的位置,如果位置很偏(p值很小,也就是取极限值的概率很小),那么就把H0拒绝了,因为从概率角度上,低概率事件可以默认为不可能事件,但是有一定的犯错概率,也就是Type 1 Error。
t分布的起源
大样本的好处
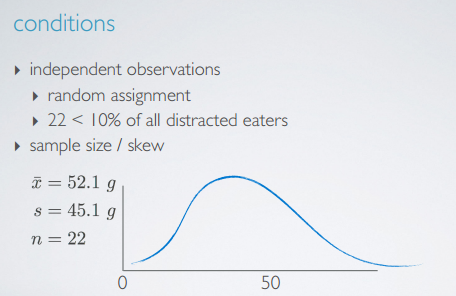
在obes独立不相关以及群体分布不是太skew的前提下,一个大的样本意味着
- sample distribution of the mean 是正态的
- 估计的standard error更可信:
sn√ sample样本越小,那么对standard error的估计就越不确信,因此相应的CI需要变得更宽一些,这就产生了T分布。
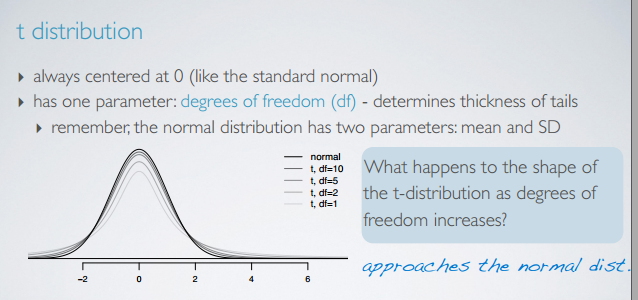
t分布概述
t分布的形状和自由度有关,自由度 df 一般是 df=n−1 。样本越大,t分布越接近正态分布。
样本越小,t分布越宽,这样解释了 σ 的不确定性。
inference for a mean
inference for comparing two independent means
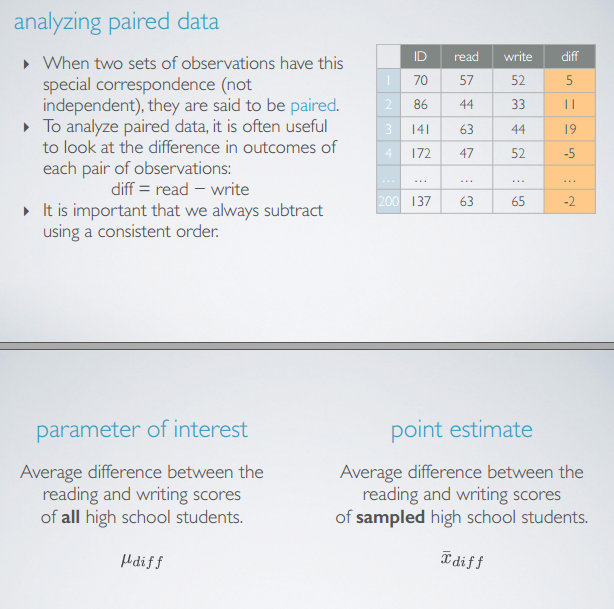
inference for comparing two paired means
比较paird means和independent means的区别有:
- 前者的点估计是每个pair的差值的平均数,后者的点估计是每一组的平均数的差值
- 前者的se是是pair的差值的
s
,然后
s/sqrtn ,后者的se是两组se的二范数。 - 前者的假设是,后者的假设是组内和组件独立不相关,size/skew。





















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









