







 本文详细探讨了集成学习中的投票法原理,比较了硬投票与软投票在乳腺癌数据集上的表现,并通过实例展示了如何在sklearn中实现。实验表明,软投票通常优于硬投票,且不同类型模型的集成往往强于单一类型。
本文详细探讨了集成学习中的投票法原理,比较了硬投票与软投票在乳腺癌数据集上的表现,并通过实例展示了如何在sklearn中实现。实验表明,软投票通常优于硬投票,且不同类型模型的集成往往强于单一类型。
集成学习第一法宝:投票!
集成学习(上)所有Task:
文章目录
投票法的原理分析
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
注意,是理想情况下。真的会存在集成模型不如基模型的情况,看下面的例子就知道了
投票法在回归模型与分类模型上均可使用:
- 回归投票法:预测结果是所有模型预测结果的平均值。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
分类投票法又可以被划分为硬投票与软投票:
-
硬投票:预测结果是所有投票结果最多出现的类。用基模型的分类结果
-
软投票:预测结果是所有投票结果中概率加和最大的类。用基模型的分类概率
注意!!采用软投票的时候,基模型务必是可以输出概率的,比如SVC需要要设置 probability=True 。
下面我们使用一个例子说明硬投票与软投票的区别:
对于某个样本:
模型 1 的预测结果是 类别 A 的概率为 99%,是类别B的概率是1%,基模型预测结果为类别A
模型 2 的预测结果是 类别 A 的概率为 49%,是类别B的概率是51%,基模型预测结果为类别B
模型 3 的预测结果是 类别 A 的概率为 49%,是类别B的概率是51%,基模型预测结果为类别B
硬投票:只考虑基模型的投票结果类别,有2/3的模型预测结果是B,因此硬投票法的预测结果是B
软投票:最终对于类别A的预测概率的平均是 (99 + 49 + 49) / 3 = 65.67%,对类别B的预测概率是平均是(1+51+51)/3=34.33%,因此软投票法的预测结果是A。
从这个例子我们可以看出,软投票法与硬投票法可以得出完全不同的结论。相对于硬投票,软投票法考虑到了预测概率这一额外的信息,因此可以得出比硬投票法更加准确的预测结果。软投票的结果一定比硬投票结果更加准确吗?
在投票法中,我们还需要考虑到不同的基模型可能产生的影响。理论上,基模型可以是任何已被训练好的模型。但在实际应用上,想要投票法产生较好的结果,需要满足两个条件:
- 基模型之间的效果不能差别过大。当某个基模型相对于其他基模型效果过差时,该模型很可能成为噪声。
- 基模型之间应该有较小的同质性。例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型。
当投票合集中使用的模型能预测出清晰的类别标签时,适合使用硬投票。
当投票集合中使用的模型能预测类别的概率时,适合使用软投票。
软投票同样可以用于那些本身并不预测类成员概率的模型,只要他们可以输出类似于概率的预测分数值(例如支持向量机、k-最近邻和决策树)。
投票法的局限性在于,它对所有模型的处理是一样的,这意味着所有模型对预测的贡献是一样的。如果一些模型在某些情况下很好,而在其他情况下很差,这是使用投票法时需要考虑到的一个问题。
投票法的案例分析
Sklearn中提供了 VotingRegressor 与 VotingClassifier 两个投票方法。 这两种模型的操作方式相同,并采用相同的参数。使用模型需要提供一个模型列表,列表中每个模型采用Tuple的结构表示,第一个元素代表名称,第二个元素代表模型,需要保证每个模型必须拥有唯一的名称。
我在代码中设计了几处可以调整设计对比的参数。
dataset:
“generate” 采用sklearn的make_classification 生成的散点数据。
“breastcancer” sklearn中自带的乳腺癌数据,其特征均为连续型
basemodel:
“diff” 基模型为不同的模型
“same” 基模型为同一个模型的不同参数
voting:
“soft”:软投票
“hard”:硬投票
代码原文,在DataWhale教程基础上改的:
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from matplotlib import pyplot
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
class VoteClassify:
# test classification dataset
# define dataset
def __init__(self,dataset,basemodel = "diff",voting = "hard"):
""":arg
dataset: 数据集,generate生成数据 breastcancer 乳腺癌数据
"""
self.basemodel = basemodel
self.voting = voting
self.dataset = dataset
def get_dataset(self):
if self.dataset == "generate":
X,y = make_classification(n_samples=1000, n_features=20, n_informative=15,
n_redundant=5, random_state=2)
return X, y
elif self.dataset == "breastcancer":
# 乳腺癌数据集
breast_cancer = datasets.load_breast_cancer()
# print(breast_cancer.feature_names)
df = pd.concat([pd.DataFrame(breast_cancer.data,columns=breast_cancer.feature_names)
,pd.DataFrame(breast_cancer.target,columns=["label"])
]
,axis=1)
# print(df.head())
X=breast_cancer.data
y=breast_cancer.target
# print(X.shape)
# print(df['label'].value_counts())
return X, y
# get a voting ensemble of models, the base models are same
def get_voting_samebasemodel(self):
# define the base models
model_dict = dict()
# model_dict['knn1'] = KNeighborsClassifier(n_neighbors=1)
# model_dict['knn3'] = KNeighborsClassifier(n_neighbors=3)
# model_dict['knn5'] = KNeighborsClassifier(n_neighbors=5)
# model_dict['knn7'] = KNeighborsClassifier(n_neighbors=7)
# model_dict['knn9'] = KNeighborsClassifier(n_neighbors=9)
model_dict['svm1_with_std'] = make_pipeline(StandardScaler(),
SVC(C=0.1,kernel='rbf',gamma=0.05,probability=True))
model_dict['svm2_with_std'] = make_pipeline(StandardScaler(),
SVC(C=0.1,kernel='rbf',gamma=0.005,
probability=True))
model_dict['svm3_with_std'] = make_pipeline(StandardScaler(),
SVC(C=0.01,kernel='linear',probability=True))
model_dict['svm4_with_std'] = make_pipeline(StandardScaler(),
SVC(C=1.0,kernel='linear',probability=True))
model_dict['svm5_with_std'] = make_pipeline(StandardScaler(),
SVC(C=10.0,kernel='linear',probability=True))
# define the voting ensemble
ensemble = VotingClassifier(estimators=self.model_dict2list(model_dict), voting=self.voting) # voting="soft"为软投票 hard为硬投票
return ensemble,model_dict
# get a voting ensemble of models, the base models are different
def get_voting_diffbasemodel(self):
# define the base models
model_dict = dict()
model_dict['lr'] = LogisticRegression(max_iter=3000) #迭代次数少会报错,原因待查
model_dict['lr_with_std'] = make_pipeline(StandardScaler(),LogisticRegression())
model_dict['svm'] = SVC(probability=True)
model_dict['svm_with_std'] = make_pipeline(StandardScaler(),SVC(probability=True))
model_dict['dt3'] = DecisionTreeClassifier(max_depth=3)
model_dict['dt3_with_std'] = make_pipeline(StandardScaler(),DecisionTreeClassifier(max_depth=3))
model_dict['knn5'] = KNeighborsClassifier(n_neighbors=5)
model_dict['knn5_with_std'] = make_pipeline(StandardScaler(),KNeighborsClassifier(n_neighbors=5))
model_dict['nb'] = GaussianNB()
model_dict['nb_with_std'] = make_pipeline(StandardScaler(), GaussianNB())
model_dict['rf'] = RandomForestClassifier(n_estimators=30)
model_dict['rf_with_std'] = make_pipeline(StandardScaler(),RandomForestClassifier(n_estimators=30))
# define the voting ensemble
ensemble = VotingClassifier(estimators=self.model_dict2list(model_dict), voting=self.voting) # voting="soft"为软投票 hard为硬投票
return ensemble,model_dict
def model_dict2list(self,model_dict):
models = list()
for key in model_dict.keys():
models.append((key,model_dict[key]))
return models
# get a list of models to evaluate
def get_models(self):
models = dict()
if(self.basemodel == "diff"):
voting_model,models = self.get_voting_diffbasemodel()
else :
voting_model,models = self.get_voting_samebasemodel()
if(self.voting == "hard"):
models['hard_voting'] = voting_model
else :
models['soft_voting'] = voting_model
return models
# evaluate a give model using cross-validation
def evaluate_model(self,model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=2, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores
# 设置投票模型采用的数据集、基模型和投票方式
# vc = VoteClassify(dataset = "generate",basemodel = "diff",voting = "soft")
# vc = VoteClassify(dataset = "generate",basemodel = "same",voting = "soft")
vc = VoteClassify(dataset = "breastcancer",basemodel = "diff",voting = "hard")
# vc = VoteClassify(dataset = "breastcancer",basemodel = "diff",voting = "soft")
# vc = VoteClassify(dataset = "breastcancer",basemodel = "same",voting = "hard")
# vc = VoteClassify(dataset = "breastcancer",basemodel = "same",voting = "soft") # svm比knn效果要好
# define dataset
X, y = vc.get_dataset()
# get the models to evaluate
models = vc.get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = vc.evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, np.mean(scores), np.std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
问题1 投票效果一定好于单个模型吗?大概率是的
问题2 软投票的效果一定好于硬投票吗?大概率是的
问题3 不同类型的基模型的集成是不是一定好于同一类基模型?大概率是的
实验
实验1设置:vc = VoteClassify(dataset = “breastcancer”,basemodel = “same”,voting = “hard”)
实验1结果:投票效果比5个基模型中的4个基模型效果好
>svm1_with_std 0.947 (0.023)
>svm2_with_std 0.938 (0.021)
>svm3_with_std 0.967 (0.020)
>svm4_with_std 0.970 (0.018)
>svm5_with_std 0.966 (0.023)
>hard_voting 0.969 (0.023)
实验2设置:vc = VoteClassify(dataset = “breastcancer”,basemodel = “same”,voting = “soft”)
实验2结果:投票效果比5个基模型中的所有基模型效果都要好
>svm1_with_std 0.947 (0.023)
>svm2_with_std 0.938 (0.021)
>svm3_with_std 0.967 (0.020)
>svm4_with_std 0.970 (0.018)
>svm5_with_std 0.966 (0.023)
>soft_voting 0.971 (0.017)
同时,在实验1和实验2 中,软投票比硬投票效果好。
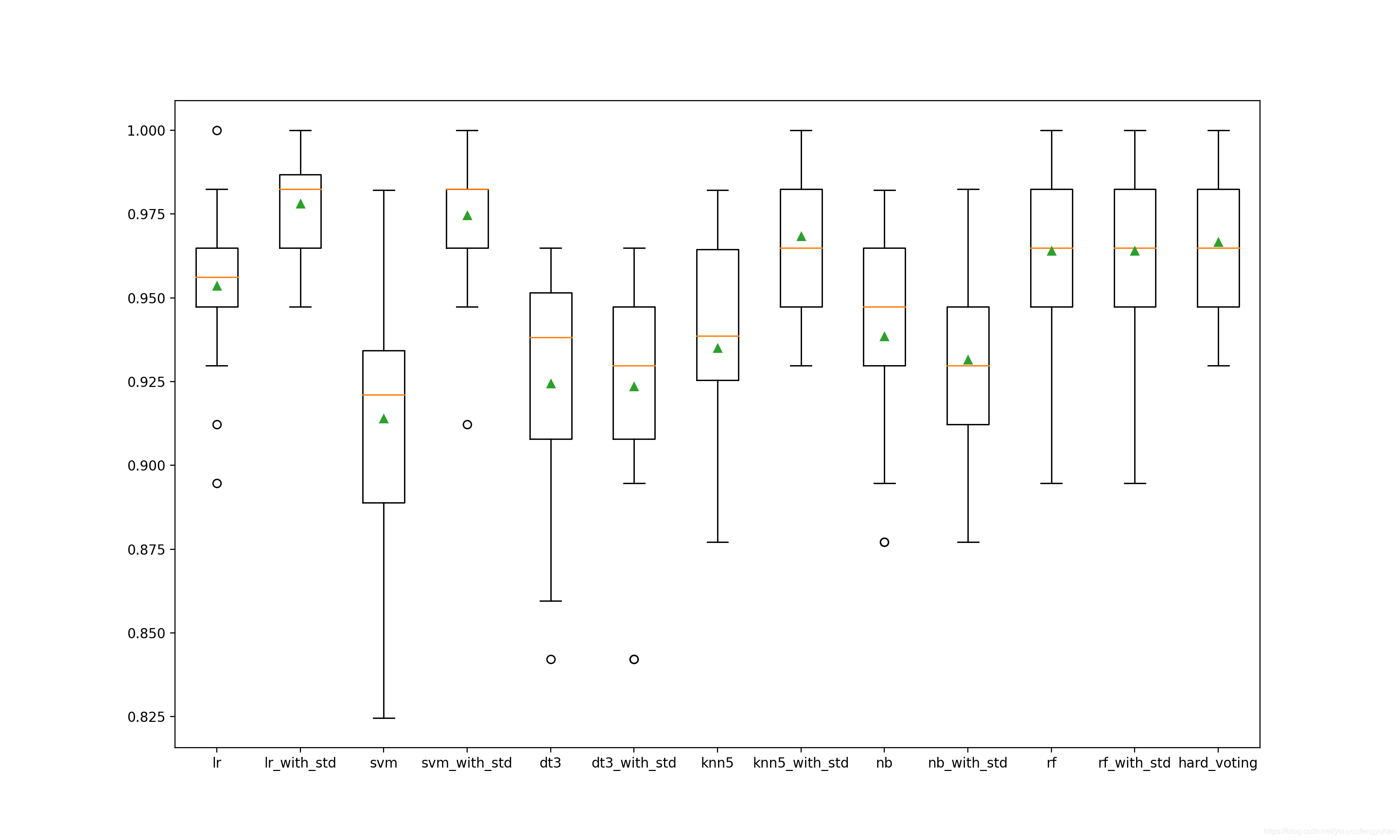
实验3设置:vc = VoteClassify(dataset = “breastcancer”,basemodel = “diff”,voting = “hard”)
实验3结果:投票效果比12个基模型中的9个基模型效果好
>lr_with_std 0.978 (0.017)
>svm 0.914 (0.039)
>svm_with_std 0.975 (0.019)
>dt3 0.919 (0.038)
>dt3_with_std 0.920 (0.041)
>knn5 0.935 (0.030)
>knn5_with_std 0.968 (0.022)
>nb 0.939 (0.030)
>nb_with_std 0.932 (0.030)
>rf 0.963 (0.035)
>rf_with_std 0.961 (0.021)
>hard_voting 0.963 (0.022)
实验4设置:vc = VoteClassify(dataset = “breastcancer”,basemodel = “diff”,voting = “soft”)
实验4结果:投票效果比11个基模型中的8个基模型效果都要好
>lr 0.953 (0.024)
>lr_with_std 0.978 (0.017)
>svm 0.914 (0.039)
>svm_with_std 0.975 (0.019)
>dt3 0.925 (0.035)
>dt3_with_std 0.919 (0.040)
>knn5 0.935 (0.030)
>knn5_with_std 0.968 (0.022)
>nb 0.939 (0.030)
>nb_with_std 0.932 (0.030)
>rf 0.958 (0.027)
>rf_with_std 0.962 (0.030)
>soft_voting 0.963 (0.023)
在实验3和实验4 中,软投票没有比硬投票效果好。
反思
-
我认为我上面的实验结果,不能严谨得得出结论。主要原因在于,我的基模型,并不是已经训练好的,确认过的最佳模型,所以基模型的好坏对最终结果的影响很大。
-
在实际工业生产环境中,还是需要多次尝试。
-
在实验中有一个意外小收获,第一次真切感受到标准化的力量。
收获:对于部分模型(比如lr、svm、knn)来说,数据进行标准化会使得模型效果大幅提升(精确率提升且方差变小),当然,也有下降的(比如NB)。
还有一些疑惑
-
基模型是已被训练好的模型,是否还有必要在投票模型中整体调参呢?
-
硬投票,如果1:1平怎么办?

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









