







全连接网络训练中的优化技巧
欠拟合:
根本原因是特征维度过少,模型过于简单,导致拟合的函数无法满足训练集,误差较大。
解决方法:增加特征维度,增加训练数据;
过拟合:
根本原因是特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美的预测训练集,但对新数据的测试集预测结果差。 过度的拟合了训练数据,而没有考虑到泛化能力。
避免过拟合常用的方法:
- early stopping: 在发生过拟合之前提前结束训练;理论上是可以,但这一点不好把握。
- 数据集扩增:就是让模型见到更多的情况,可以最大化的满足全样本,但是实际应用中对未来事件的预测却显得鞭长莫及。
- 正则化:是通过引入范数概念,增强模型的泛化能力,包括L1、L2
- dropout:使网络模型的一种方法,每次训练是舍去一些节点来增强泛化能力。
后两种重点介绍:
1.正则化:
就是在神经网络计算损失值的过程中,在损失值再加一项。
- L1:所有学习参数w的绝对值的和
- L2:所有学习参数w的平方和然后求平方根
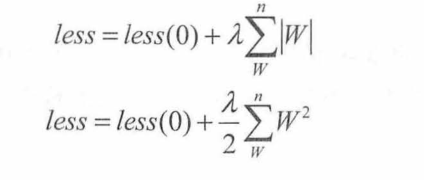
其中,less(0)代表真实的loss值,它后面的那一项就代表正则化了,入为一个可以调节的参数,用来控制正则化对loss的影响。
对于L2将其乘以1/2是为了反向传播是=时对其求导正好将数据规整。
注意:上面的公式记不记不是很重要,因为tensorflow已经有封装好的函数拿来直接用
 # t为权重w
# t为权重w
reg = 0.01 #入为0.01
loss=tf.reduce_mean((y_pred-y)**2)+tf.nn.l2_loss(weights['h1'])*reg+tf.nn.l2_loss(weights['h2'])*reg
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)2.dropout:
在训练过程中每次随机选择一部分节点不要去“学习”。
这是因为,数据本身是不可能很纯净,即任何一个模型不能100%把数据完全分开,再某一类中一定会有异常数据,过拟合的问题恰恰是把这些异常数据当成规律来学习了。
注意:
由于dropout让一部分节点不去学习,所以在增加模型的泛化能力的同时,会使学习速度降低,使模型不太容易学成,所以在使用过程需要合理的调节到底丢掉多少节点,不是越多越好。


在构建一层网络时dropout一下,然后将dropout后的传入第二层。
layer_1 = tf.nn.relu(tf.add(tf.matmul(x, weights['h1']), biases['h1']))
keep_prob = tf.placeholder("float")
layer_1_drop = tf.nn.dropout(layer_1, keep_prob)
layer2 =tf.add(tf.matmul(layer_1_drop, weights['h2']),biases['h2'])
y_pred = tf.maximum(layer2,0.01*layer2)然后将舍去多少节点的值传入(因为这里使用的是占位符定义keep_prob)。
_, loss_val = sess.run([train_step, loss], feed_dict={x: X, y: Y,keep_prob:0.6})最后测试的时候记得更改keep_prob为1。
print ("loss:\n", sess.run(loss, feed_dict={x: xTrain, y: yTrain,keep_prob:1.0}))#延伸
基于退化学习率dropout技术来拟合异或数据

从上面的结果看,损失值在10000时是0.08,后来又涨到0.09,尤其在最后几次,出现了抖动,这表明后期的学习率有点大了
使用退化学习率:
global_step = tf.Variable(0, trainable=False)
decaylearning_rate = tf.train.exponential_decay(learning_rate, global_step,1000, 0.9)
#train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)
train_step = tf.train.AdamOptimizer(decaylearning_rate).minimize(loss,global_step=global_step)在使用优化器的代码部分添加decaylearning_rate,设置总步数为20000,每执行1000步,学习率缩减0.9,如上述代码。

















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









