






大模型输出数学公式的格式化
最近在做大模型的输出格式化时遇到一个问题,就是数学公式的格式化处理比较差,我是使用的React的react-markdown这个库,它可以通过添加数学的插件数学插件(如 rehype-katex 或 remark-math)来识别数学latex格式的数学公式。
但是在实际的使用过程中,效果并不好,具体来说,他们是基于markdown格式的数学公式来进行渲染,也就是单个$或一对$$美元符号包裹的,但是各家大模型输出的数学公式格式有一定的差别,具体如下图:

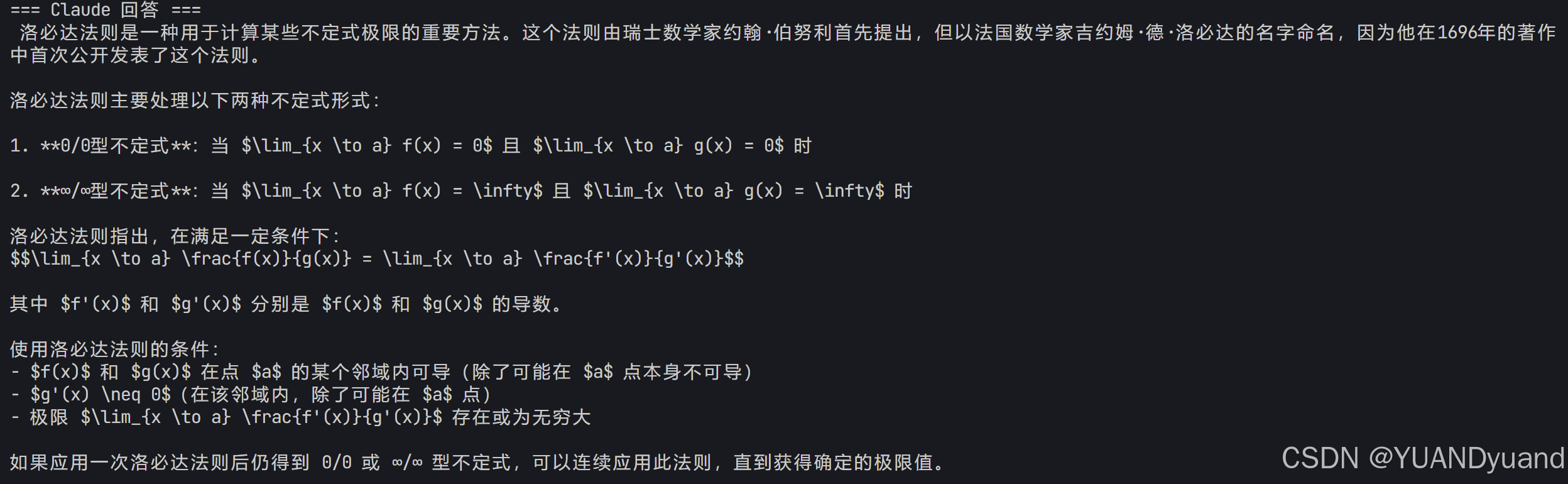
deepseek回答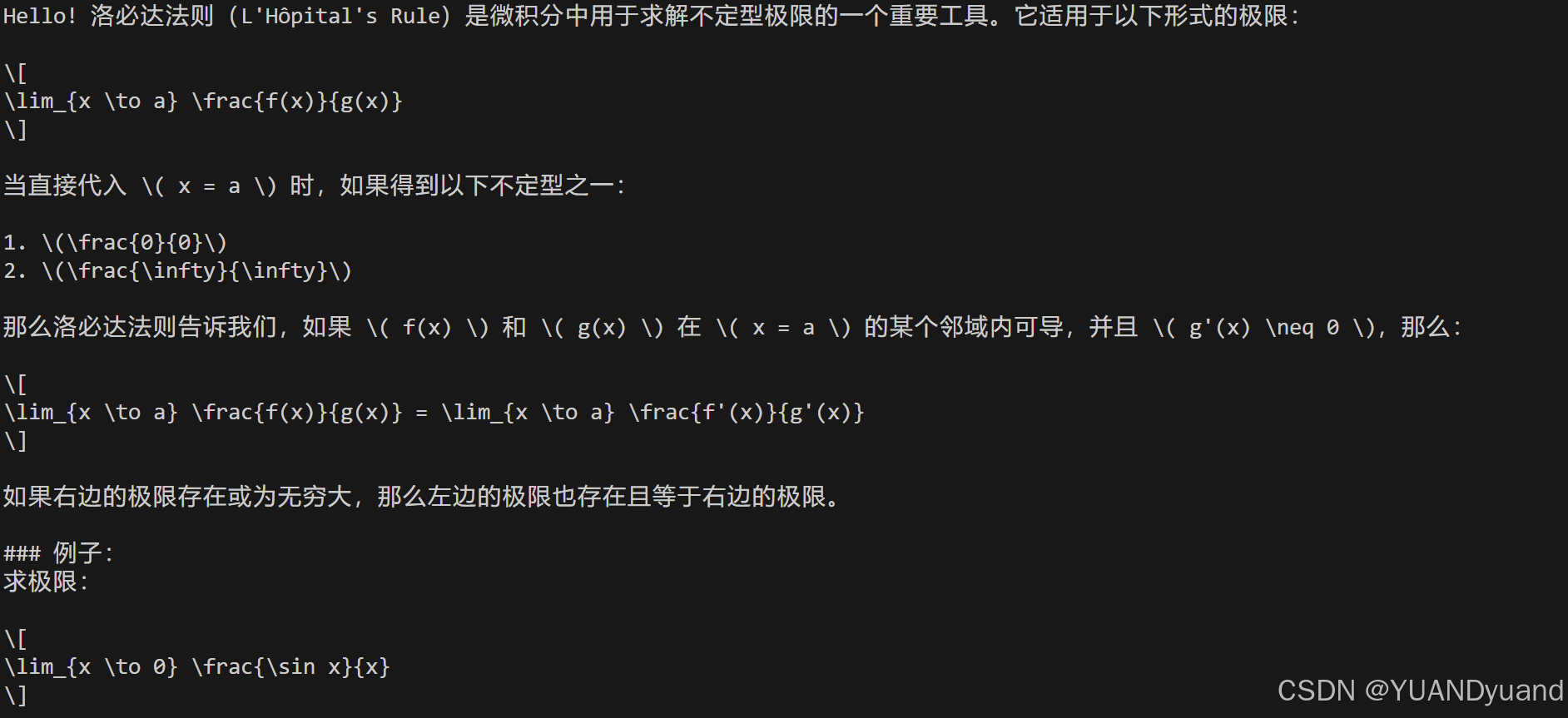
可以看到chatgpt和deepseek的回答会是标准的latex格式\(\)或者\[\] 不能正常渲染,而Claude则是一个markdown格式的数学公,即$或$$。
这样就比较难处理,为了使现代的这种latex能够在react-markdown正常渲染,就需要在渲染前做一些处理,简单来说就是把数学公式加上$符号,当然其中还需做一些处理防止误判。
对于这个问题,可以借鉴一下这个开源代码里的解决方案,具体代码和步骤可以分为:
export function preprocessLaTeX(content: string): string {
// 步骤一:保护代码块
const codeBlocks: string[] = [];
content = content.replace(/(```[\s\S]*?```|`[^`\n]+`)/g, (match, code) => {
codeBlocks.push(code);
return `<<CODE_BLOCK_${codeBlocks.length - 1}>>`;
});
// 步骤二:保护 LaTeX 表达式
const latexExpressions: string[] = [];
content = content.replace(/(\$\$[\s\S]*?\$\$|\\\[[\s\S]*?\\\]|\\\(.*?\\\))/g, (match) => {
latexExpressions.push(match);
return `<<LATEX_${latexExpressions.length - 1}>>`;
});
// 步骤三:将内容中后跟数字的 $(如 $100)转义为 \$,以避免将其误认为是 LaTeX 行内公式的分隔符。
content = content.replace(/\$(?=\d)/g, '\\$');
// 步骤四: 将占位符 <<LATEX_n>> 替换回原始的 LaTeX 表达式,确保数学公式内容恢复。
content = content.replace(/<<LATEX_(\d+)>>/g, (_, index) => latexExpressions[parseInt(index)]);
// 步骤五: 将占位符 <<CODE_BLOCK_n>> 替换回原始代码块内容。
content = content.replace(/<<CODE_BLOCK_(\d+)>>/g, (_, index) => codeBlocks[parseInt(index)]);
// 步骤六:将 \[...\] 和 \(...\) 转换为 $$...$$ 和 $...$
content = escapeBrackets(content);
// 对化学公式中的 \ce{} 和 \pu{} 命令添加额外的反斜杠转义(如 $\\ce{} 变为 $\\\\ce{}),以防止解析错误。
content = escapeMhchem(content);
return content;
}替换的函数:
具体来说就是将代码块的,行内的(\(\)),行级的(\[\])都匹配到,然后依次进行处理
export function escapeBrackets(text: string): string {
const pattern = /(```[\S\s]*?```|`.*?`)|\\\[([\S\s]*?[^\\])\\]|\\\((.*?)\\\)/g;
return text.replace(
pattern,
(
match: string,
codeBlock: string | undefined,
squareBracket: string | undefined,
roundBracket: string | undefined,
): string => {
if (codeBlock != null) {
return codeBlock;
} else if (squareBracket != null) {
return `$$${squareBracket}$$`;
} else if (roundBracket != null) {
return `$${roundBracket}$`;
}
return match;
},
);
}
// 处理特殊的化学函数
export function escapeMhchem(text: string) {
return text.replaceAll('$\\ce{', '$\\\\ce{').replaceAll('$\\pu{', '$\\\\pu{');
}
最后在匹配前调用这个预处理:
const Markdown = ({ children }: { children: string }) => {
const processedContent = preprocessLaTeX(children);
return (
<ReactMarkdown
remarkPlugins={remarkPlugins}
rehypePlugins={[
[rehypeKatex],
[
rehypeHighlight,
]
]}
components={components}
>
{processedContent}
</ReactMarkdown>
);
};具体效果如图展示:


















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









