







知识图谱是Google在2012年5月17日提出的,其初衷是为了提高搜索引擎的能力,改善用户的搜索质量以及搜索体验。当前的人工智能技术其实可以简单地划分为感知智能(主要是图像、视频、语音、文字等识别)和认知智能(涉及知识推理、因果分析等),知识图谱技术就是认知智能领域中的主要技术,是人工智能技术的组成部分,其强大的语义处理和互联组织能力,为智能化信息应用提供了基础。
一个知识图谱旨在描述现实世界中存在的实体以及实体之间的关系。随着人工智能技术的发展和应用,知识图谱作为关键技术之一,已被广泛应用于智能搜索、智能问答、个性化推荐、内容分发等领域。
从使用范围来说,知识图谱分为通用知识图谱和领域知识图谱,通用知识图谱强调的是广度,数据多来自于互联网,而领域知识图谱应用于垂直领域,成为了基础数据服务。
知识图谱的定义
知识图谱旨在描述真实世界中存在的各种实体或概念及其关系,其构成一张巨大的语义网络图,节点表示实体或概念,边则由属性或关系构成。现在的知识图谱已被用来泛指各种大规模的知识库。
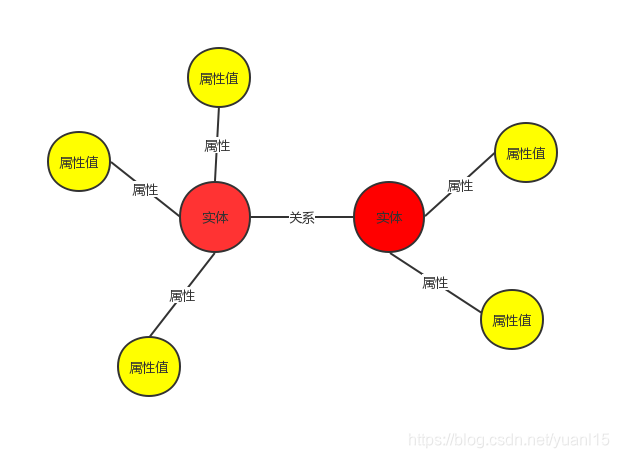
如上图所示,知识图谱中包含三种节点,其基本形式为(实体1-关系-实体2)、(实体-属性-属性值)。
实体:指的是有可区别性且独立存在的事物。如某个国家:中国、英国等;某个城市:北京、伦敦等。
语义类:具有某种特性的实体构成的集合,如国家、城市、民族等。
属性值:实体指向的属性的值。例如中国(实体)面积(属性)960万平方公里(属性值)。
关系:在知识图谱上,关系是把kk个图节点(实体、语义类、属性值)映射到布尔值的函数。
基于上述的语义图概念,我们可以构建一个国家的知识图谱作为例子,如下:
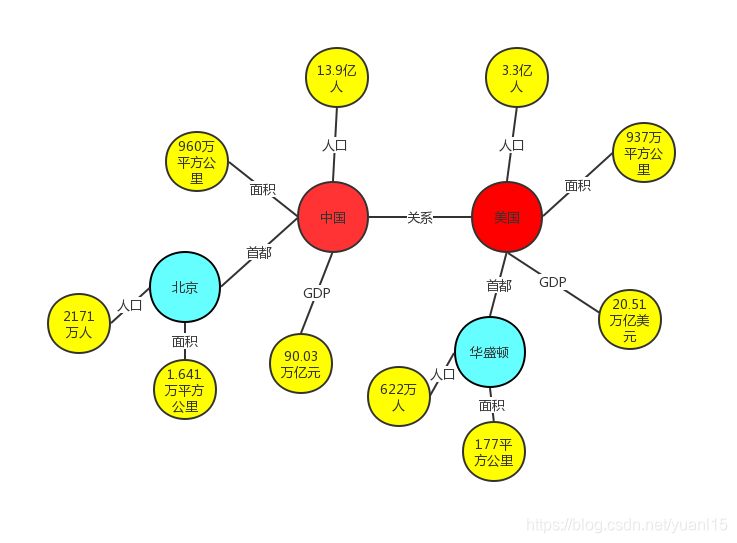
这个知识图谱显示中国、美国和其首都的关系,还有其属性值。
知识图谱架构
知识图谱架构包括自身逻辑结构以及构建知识图谱所采用的技术架构。
知识图谱的逻辑结构:知识图谱在逻辑上可分为模式层与数据层两个层次。数据层主要是由一系列的事实组成的,通常使用三元组来表达这些事实,因而可以选择图数据库来作为存储介质,存储这些三元组。常用的图数据库有Neo4j、twitter的FlockDB、sones的GraphDB等。模式层则构建在数据层之上,是知识图谱的核心,通常采用本体库来管理知识图谱的模式层。通过本体库形成的知识库不仅层次结构较强,并且冗余较小。
本体库:本体是指一种“形式化的,对于共享概念体系的明确而又详细的说明”,换言之即对于特定领域之中某套概念及其相互之间关系的形式化表达。
常见的本体构成要素包括:实体、语义类、属性、关系等。例如NetworkConnection的概念,其中包含NetProvider、NetSpeed实体,还有NetProvider和NetSpeed之间的关系概念,这些实体的属性概念。

上图中虚线框中的部分为知识图谱的构建过程,也包含知识图谱的更新过程。这一过程包括:信息抽取、知识表示、知识融合、知识推理四个过程。首先从最原始的数据(包括结构化、半结构化、非结构化数据)出发,采用一系列自动化或半自动化的技术手段,从原始数据中提取出实体、关系、属性等知识要素,通过一定的手段对知识要素进行表示,便于进一步处理,然后通过知识融合消除实体、关系、属性等指称项与事实对象之间的歧义,形成高质量知识库,并将其存入知识库的数据层和模式层。最后利用知识推理在已有知识库的基础上进一步挖掘隐含的知识,从而丰富扩展知识库。
知识图谱的构建方式主要有两种,自顶向下(top-down)与自底向上(bottom-up)两种构建方式。
自顶向下:指的是先定义好本体与数据模式,再将实体加入到知识库。该构建方式需要利用一些现有的结构化知识库作为其基础知识库。FreeBase项目就是采用这种方式。
自底向上:指的是从一些开放链接的数据中提取出实体,选择其中置信度较高的加入到知识库,再构建顶层的本体模式。大多数知识图谱都采用自底向上的方式进行构建,其中最典型的就是Google的Knowledge Vault和微软的Satori知识库。这也符合互联网数据内容知识产生的特点。
业界代表性知识图谱
| 知识图谱库名称 | 机构 | 特点、构建手段 | 应用产品 |
| 知识图谱 | 组织 | 特点 | 应用 |
|
FreeBase |
MetaWeb | •实体、语义类、属性、关系 •自动+人工,部分数据从维基百科等数据源抽取,另一部分数据来自人工协同编辑 •https://developers.google.com/freebase/ | •Google Search Engine •Google Now |
|
Knowledge Vault |
| •实体、语义类、属性、关系 •超大规模数据库,源自维基百科、FreeBase、《世界各国纪实年鉴》 •https://research.google.com/pubs/pub45634 | •Google Search Engine •Google Now |
| DBPedia | 莱比锡大学、柏林自由大学、OpenLink Software | •实体、语义类、属性、关系 •从维基百科抽取 |
DBPedia |
| 维基数据 | 维基媒体基金会 | •实体、语义类、属性、关系,与维基百科紧密结合 •人工(协同编辑) |
WikiPedia |
| Facebook Social Graph | | •Facebook社交网络数据 | Social Graph Search |
| 百度知识图谱 | 百度 | •搜索结构化数据 | 百度搜索 |
| 搜狗知立方 | 搜狗 | •搜索结构化数据 | 搜狗搜索 |
| ImageNet | 斯坦福大学 | •搜索引擎 •亚马逊AMT | 计算机视觉相关应用 |
知识图谱相关产品CN-DBpedia
CN-DBpedia是由复旦大学知识工场实验室研发并维护的大规模通用领域结构化百科。CN-DBpedia主要从中文百科类网站(如百度百科、互动百科、中文维基百科等)的纯文本页面中提取信息,经过滤、融合、推断等操作后,最终形成高质量的结构化数据,供机器和人使用。
CN-DBpedia的入口:http://kw.fudan.edu.cn/cndbpedia/intro/,在这里我们尝试使用它的部分功能作为示例。
搜索
http://kw.fudan.edu.cn/cndbpedia/search/
通过上示地址进入CN-DBpedia搜索页面,搜索“周杰伦”,可以获得“周杰伦”的实体和实体关系、属性等。点击curiosity可以得到动态的可视化效果。

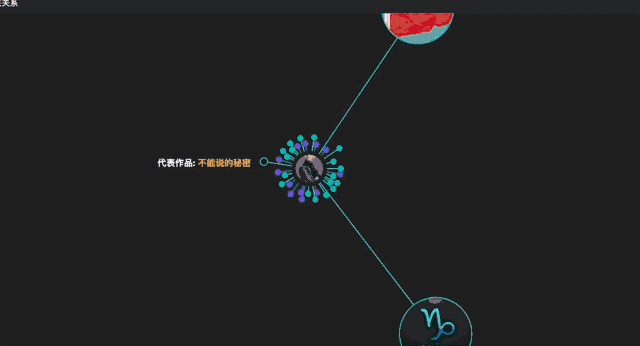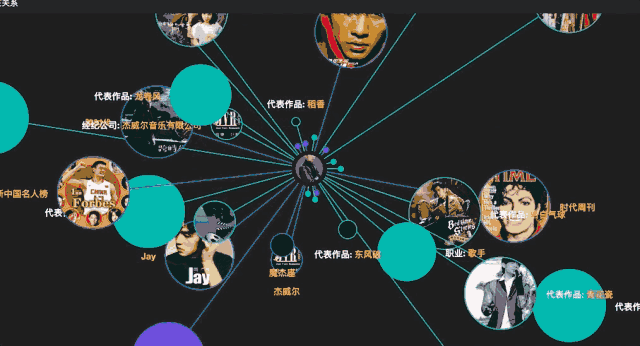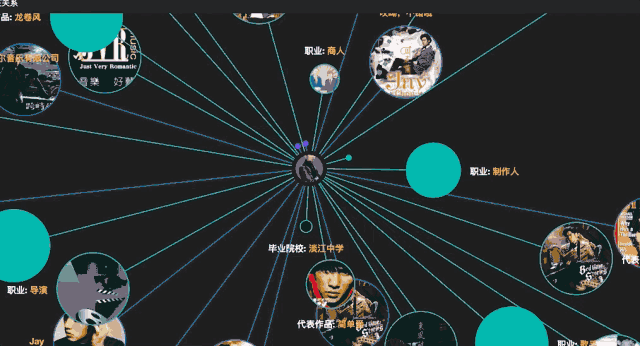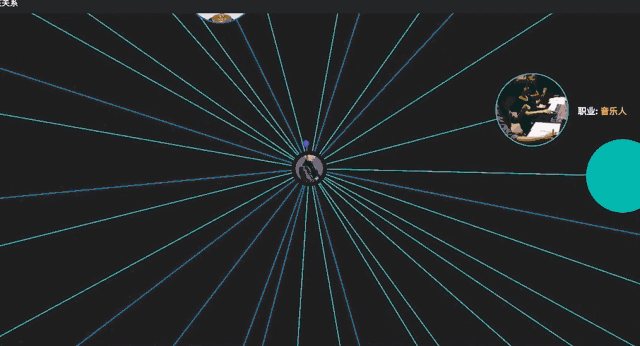
参考
[1] https://blog.csdn.net/Leohfan/article/details/82630573
[2] Bo Xu, Yong Xu, Jiaqing Liang, Chenhao Xie, Bin Liang, Wanyun Cui, and Yanghua Xiao. CN-DBpedia: A Never-Ending Chinese Knowledge Extraction System. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, pp. 428-438. Springer, Cham, 2017.

















 1536
1536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









