







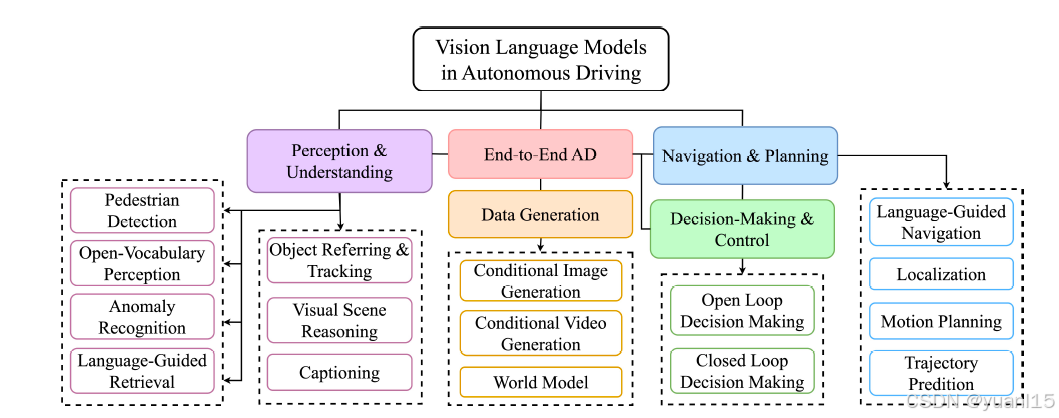
目录
VLM在自动驾驶中的任务
single or multiple Object Referring
即带条件的目标检测,用语言指示模型识别图像中特定目标。
Referred Object Tracking
和Object Referring相比,Object Referring Tracking会根据自然语言描述在连续帧中对目标进行跟踪。
Open-Vocabulary 3D Object Detection
开放式3D目标检测,利用VLM的zero-shot能力检测场景中在白名单之外的目标类型。
Visual Question Answering
交通场景视觉问答,这需要vlm的高维场景理解能力。自动驾驶领域的问答可以划分为感知、规划、空间推理、时序推理、因果逻辑推理。感知问题可以用来识别交通参与者,如外观描述、存在性、数量、状态等。planning问题则可用于基于当前交通状态做决策。空间推理可以确定目标的相对、绝对位置。时序推理则可以过去或未来的目标行驶轨迹、行为。因果推理则可以通过逻辑推理分析事件的原因。

Captioning
生成一个对于环境的文本描述。和VQA任务不同之处,captioning更关注于特定的任务如场景描述重要性排序、行为解释。Captioning也可以理解为固定问题的VQA。
captioning和VQA的metrics评测指标都是open-ended VQA。在选择题VQA任务中,正确答案出现次数除以总问题数即为accuracy。在开放式问题形式中BLEU、METEOR、ROUGE、CIDEr等评测指标作为评估预测结果和答案的相关性、正确性。

Language-Guided Navigation
根据语言指令指示VLM找到目标位置并给出到达目标位置的规划结果。
Conditional Autonomous Driving Data Generation
即可控的自动驾驶数据生成,应用大模型合成真实的驾驶场景图片。可控的数据生成可以加入prompts控制,可以让他生成BEV图像,可以让他有特定的行为等等。
E2E
相关端到端文章
《DriveGPT4:Gpt-driver: Learning to drive with gpt》
motion planners需要处理各种不同的输入,如自车信息、地图和感知结果,并预测精确的waypoint坐标。因此在利用LLM做运动规划的时候,需要将不同的输入转化为统一的语言tokens,并把自动驾驶问题转化为语言模型的问题。motion planning问题可以建模如下:
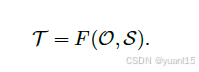 输入是O(Observations)、S(ego states),输出是T(trajectory)。其轨迹可以表示为一个waypoints的集合T:
输入是O(Observations)、S(ego states),输出是T(trajectory)。其轨迹可以表示为一个waypoints的集合T:
![]()
其中ego states S包含了自车的历史轨迹和他现在的速度、加速度等,observations O包含了感知、预测的输出,如检测到的目标框及他们未来的运动。这样基于学习的motion planners通过模仿人类司机的轨迹即可输出trajectory,Loss函数即选用L1 loss。
在LLM中问题需要特殊处理,![]() 轨迹通过tokenizer K转化为tokens,这些tokens就是LLM需要输出的结果,目标函数变成如下:
轨迹通过tokenizer K转化为tokens,这些tokens就是LLM需要输出的结果,目标函数变成如下:
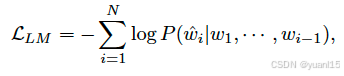 w1~wi-1是已经规划的轨迹,
w1~wi-1是已经规划的轨迹,是人类驾驶员轨迹,目标就是最大化这个概率P。自然语言的结果是输出token,而不是一个回归问题,所以他需要精确地输出结果,例如规划的waypoint是23米,那么LLM只有输出23这个token才是对的,输出22则是完全不同的token。
在本文中,作者还prompting-reasoning-finetuning的方法来激发语言模型潜在的motion planning能力,让模型给出推理逻辑,让规划结果更透明。

作者将自动驾驶领域COT分解为3步,1)从感知结果识别影响驾驶的关键目标;2)从预测结果分析这些关键目标未来的运动,给出关键目标影响自车的时间、地点、方式。3)从之前分析结果,规划器需要给出一个高层的驾驶决策和轨迹。其模型输出结果如下图所示:

最后文中通过驾驶日志采集了人类驾驶员轨迹,作为真值去微调LLM。
在结果对比中,作者用了nuscenes的数据来做评测,评测了和GT trajectory的L2距离、3s预测轨迹碰撞率,其结果L2大幅领先,碰撞率接近最优。还对比了few shots能力,用更少的数据比uniad效果好。还比较了in-context learning和finetuning,证明finetuning的必要性。
《DriveVLM》
参见博客DriveVLM
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









