






目录
BLEU(Bilingual Evaluation Understudy)
METEOR(metric for Evaluation of Translation with Explicit Ordering)
多模态预训练模型
CLIP
BLIP
《Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation》

Model:
BLIP模型结构如上,Image encoder部分就是一个N层的ViT模块;而文本模型分为三个,其中第一个Text Encoder是N层的transformer结构,主要目的就是用来感知,其输出和Image Encoder输出做一个对比学习的Image Text Constrast Loss;Image-grounded Text encoder模块和Image Encoder共用权重,但是增加了Cross Attention融合image信息,Loss是image-text matching loss;最后decoder模块则依然是服用Text Encoder相关的一些权重,但是Self-Attention是新的,融合image信息作生成式的相关任务,Loss则使用对应任务的Loss。可以看到上图中颜色相同的模块是共享权重的,BLIP在三种类型的任务中有很多共用的模块。
Data
在BLIP的使用的数据中,网上扒下来的数据CC12M是有noise的,他带了脏数据(图片文本对不匹配),而coco的数据却是比较干净的,所以作者这里使用了CapFilt来筛选、生成数据,逐步获取干净的大规模数据。
如下图所示,一开始数据集中包含所有数据做一个预训练得到MED(Mixture of Encoder-Decoder)模型,再用干净的COCO数据去finetune预训练模型得到Filter模型和Captioner模型,1)利用filter晒去CC12M中不匹配的文本对;2)利用captioner给Iw生成新的Ts;留下filter校验过的CC12M、captioner生成的CC12M的文本加上准确的COCO数据重新预训练MED模型,如此往复就可以提升模型效果。

在BLIP2中提出了一个新的结构Q-Former,来利用已经冻结的预训练视觉大模型,从其中提取到文本能使用的视觉特征。其结构如下,Q-Former有一些learnable Queries和image encoder的输出embeddings做cross attention。他的训练分成两步:1)vision language representation学习,利用ITC(图文对比)、ITM(图像检索)、ITG(caption生成)任务来训练;2)把Q-Former接入大语言模型,作为soft prompt,训练生成任务。

LLM
GPT3
整体训练方法和GPT相似,增加了prompt tuning,在输入中提供交互式的prompt,使用instruction+demonstration的方式,引导模型输出对应结果,甚至完成未见过的新任务。
Data
如下是Few-Shot、One-Shot、Zero-shot、Fine-Tuning的数据形式。

Few-Shot方式,会为模型提供10~100个样例(取决于模型context window=2048),这种方式在某些任务下取得的结果接近于该任务下finetune后的SOTA。One-Shot即提供1个样例。Zero-shot则给模型输入一个自然语言的指令来描述任务而不给样例,这种方式在某些任务下会让人都难以理解其目的,但是在某些任务中却很简明。
1)基于和一系列高质量的语料库相似度,清洗CommonCrawl
使用WebText、Wikiedia和自己的web books语料库座位正样本,未过滤过的Common Crawl作为负样本。使用Spark's standard tokenizer和HashingTF提取的特征。训练一个logistic regression模型,给这些Common Crawl documents打分,保留符合如下条件的数据
![]()
2)文件级的fuzzy去重
同上使用Spark's MinHashLSH implementation with 10 hashes,消除相似度较高的文本。
3)加入已知的高质量语料库到CommonCrawl。
同时为了避免训练集中有下游任务测试集、验证集中的数据,直接移除重合部分。

Model Architecture
和GPT2一样的结构

Training Process

Evaluation
对于few-shot情况,每一个评测的样本,会从该任务的训练样本中抽取K个样本作为样例,这些样例间用换行符来分隔。同具体context内容如下:

InstructGPT
《Training language models to follow instructions with human feedback》
拿现有与训练模型如GPT3作为初始模型
step1:通过标注人员给一些问题写答案来获取一部分监督数据,这些数据来源于标注人员自己写的prompt和答案、限定指令下的答案、用户反馈的问题。利用这些数据做SFT(supervised Finetuning)。
step2:用step1的模型给prompt做可能的答案,让标注人员给这些候选答案按由好到坏排序,这些排序数据可以训练一个RM(rewarding model)用于给答案评分 。我们RM是基于step1的SFT模型来训练,去除最后一层,增加一个线性层回归一个分数,RM模型的输入是prompt+response。
step3:适用强化学习,利用RM给答案的评分优化模型得到更好的答案。这里使用强化学习的原因就是因为,更新LLM模型后相当于环境变化了,如果不使用强化学习RM给新的response提供reward,就需要靠人来标,这是不可取的。目标函数如下:

参考文献
RLHF:《Learning to summarize from human feedback》
FLAN
《finetuned language models are zero-shot learners》
instruction tuning,使用数据集微调语言模型,可以大大提升其在没有见过的任务上的泛化性能,这个专用数据集是使用instruction指令描述的。在文中的具体例子,是使用60个NLP数据集微调一个137B的预训练语言模型,这60个数据集是通过自然语言指令模板表达的,最终这个模型相比没有instruction tuning有很大的提升,甚至在zero-shot能力上25个任务中有20个任务超过175B的模型。

Data

作者把tensorflow Datasets上可用的62个公开文本数据集划分成12大类。然后用模板把这些数据改写成instructions的形式,同一个类型的数据里面会混合多个类似的模板以提升数据多样性,如图所示:

在评测的时候,就按照大类catergory,某一个category中数据集只用来测试,其他的数据用来instructions tuning,看在这个未使用的数据上zero-shot的能力如何。
ablation results
scaling laws,在小模型上instruction tuning有负作用,大一些的模型上才能起作用。

chain of thought
《Chain-of-thought prompting elicits reasoning in large language models》
100B的模型在快速的sentiment classification这些问题上就能取得很好的结果,但是在数学计算、逻辑推理问题上却不能取得好的效果。chain of thought就是一种激发语言模型推理能力的一种prompting方法,让模型像人一样step by step地去思考问题。
训练好的大模型求解推理结果有几种方式:i)一种是直接让模型回答提问,后面带上The answer is;ii)在问题后加上Let's think step by step,这时模型会生成一些中间推理结果;iii)手动构造一些examples,给到输入,其实这里就是利用模型的few-shot能力仿照样例来一步一步推理(这就是引文的方法);iv)还有一种是用自动的方法即Auto-CoT,自动构造few-shot样例,即在数据中抽样相似问题并接上Let's think step by step得到答案作为你真正要的问题的前面作为输入。



ToolFormer
《Toolformer: Language Models Can Teach Themselves to Use Tools》
LLM能够依据指令很好的完成一些任务,但是在一些基础功能如算数、事实查找还比不过一些小模型。这篇文章就是让模型能够教自己使用外部工具,调用一些API。文中是自监督的方式,仅仅对api进行一些描述,就能使用包括计算器、问答系统、搜索引擎、翻译系统和日历等。这方法提升了很多下游任务,而没有牺牲他的核心语言模型能力。
方法
文中需要API的输入输出是文本序列,这样才能无缝地使用特殊tokens标记调用的起始,把API调用插入所给的文本。如下"<API>","</API>"和"->"是特殊符号(实际使用中,用"[","]"表示"<API>","</API>"),ac就是API名,ic是入参,r是结果。

下面是toolformer的一些例子,分别调用了QA、计算器、翻译、wikipedia工具。

数据制作
需要把数据集![]() 转化成API增强过的数据集。主要通过如下三步来实现:
转化成API增强过的数据集。主要通过如下三步来实现:

sample API calls:对于每一个API,我们写一个提示P(x)来引导LLM去用API调用来标记输入sequence,例如QA的提示可以写成如下:

这样就能获得在那些地方要插入api call,但是文中还用概率阈值来约束input中保留几段api call。设pM(zn+1 | z1,...,zn)是M预测第n+1个token为zn+1的概率,那么对于每个模型M预测"<API>"的地方有:
![]()
只保留top-k个概率大于阈值Ts的API call。对于每个为"<API>"的位置,还需要模型M来预测m个API的输入参数(前缀为![]() )结尾为"</API>"。
)结尾为"</API>"。
execute api calls:然后利用生成的API call来调用API得到文本序列结果ri。
filter API calls:使用API call和结果ri作为前缀求模型后面生成的token,用这些后置的token来计算交叉熵损失![]() ,如果api call作为前缀生成的后面的token没有降低loss,则抛弃这些api call。
,如果api call作为前缀生成的后面的token没有降低loss,则抛弃这些api call。

![]() ,
,![]() 代表空的序列。
代表空的序列。
model finetuning:生成了api call后,文中把对应的API call和结果ri合并到了原来的文本序列中,形成了新的数据,这个数据集出了增强过的数据,还是要保留原来的数据。在这样的数据上微调后,LLM可以更好的决定预测未来应该是什么TOKEN。
推理:当生成"->"token时,这意味着要使用API获得结果填入对应位置。
QWEN
Data
webdata:从HTML提取文本,使用language identification tools分辨语言,同时还要去重。还有一些基于规则的、机器学习的方法给内容打分,去除低质量数据。同时使用多任务指令能够提升模型的zero-shot,few-shot能力。
Tokenization
BPE(byte pair encoding),用了tiktoken(Shantanu Jain. tiktoken: A fast BPE tokeniser for use with OpenAI’s models, 2022. URL https://github.com/openai/tiktoken/.)加入了中文字符。
Architecture

用的LLaMA模型,修改部分为:
Embedding和output projection
Positional embedding使用RoPE(Rotary Positional Embedding)
Bias去除大部分层的偏置,保留QKV层偏置。
RMSNorm改变transformer的normalization
activation function选用SwiGLU。
Training
还是采用和GPT一样的自回归方式做预训练,输入前序tokens预测下一个token,context length 2048。为了节省存储空间,使用flash attention(Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher RÅLe. FlashAttention:Fast and memory-efficient exact attention with io-awareness. In NeurIPS,2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/67d57c32e20fd0a7a302cb81d36e40d5-Abstract-Conference.html.)使用AdamW,参数0.9,0.95,10-8. 余弦退火lr训练策略。BFloat16精度混合。
Context length extension
NTK-aware interpolation(
NTK-aware scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation., 2023. URL https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/.)
LogN-Scaling(
David Chiang and Peter Cholak. Overcoming a theoretical limitation of self-attention. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 7654–7664, 2022. ) and window attention(Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150, 2020.)
Alignment
利用SFT supervised finetuning,采用一些chat-style的数据,包括询问和回答。训练optimizer用的AdamW,参数0.9,0.95,10-8,序列长度2048,batchsize128,步数4000,学习旅最大2x10-6,weight decay 0.1,dropout 0.1,梯度clipping未1.0。
RLHF(Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin,Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In NeurIPS, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html.)在构造Reward Model时,同样采用先preference model pretraining,后用更好的分级标注数据finetune。proximal policy optimization:强化学习算法需要看一下。
参考文献:
chain of thought
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022c.
RLHF
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin,Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, JacobHilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In NeurIPS, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html.
AI agent
use tool:Timo Schick, Jane Dwivedi-Yu, Roberto Dess`ı, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer,Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023.
use other data: Chenxu Hu, Jie Fu, Chenzhuang Du, Simian Luo, Junbo Zhao, and Hang Zhao. Chatdb: Augmenting llms with databases as their symbolic memory. arXiv preprint arXiv:2306.03901, 2023.
embodied intelligence: Palm-e: Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378, 2023.
embodied intelligence: Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023a.
Llama3
Pretraining
预训练要解决的问题主要是这几个:1)清洗出大规模数据集;2)确定模型架构和对应的参数规模、数据规模(和scaling law相关);3)大模型预训练相关的工程技术;4)预训练开发的方法。
数据
未公开,只说用了多种多样的数据源,并使用了多种去重和清洗方法处理。
数据筛查:网络数据,去除了个人身份信息相关的内容、成人内容。自己弄了一个HTML内容抽取器,用人为评估的方法进行了HTML parser的质量评估。去重方面,使用了URL级(保留对应URL 最新的版本)、文本级(global MinHash方法去重)、行级去重;启发式的去除低质量的文本,如计算n-gram覆盖比率以去除如logging、error的信息;脏话太多的文本去除;计算文本间KL散度,如果和训练语料库相差太远的说明是不好的文本。基于模型的质量筛查,通过模型给文本分类、打分。
针对代码和推理要专门的parser提取高质量的数据。
还准备了多语言的数据。
数据混合:针对自己模型应用不同的策略来混合上述采集到的数据,给不同类型的数据分配不同的采样率。这里作者做了几个事1)训练分类器,给数据分类如打上艺术娱乐的标签类型。2)在几个小的模型上实验数据混合策略,来预测大模型表现。3)最终的比例50%通用知识,25%数学推理数据,17%代码,8%多语言。
数据退火:在你想要提高的领域,可以用退火的方法在对应的小数据上finetune,这方法可以在对应测试集上提高其表现。
模型架构
整体而言是数据扩大、多样性增加,加大了模型规模的结果,整体上模型结构和Llama和Llama2差不多。
scaling laws:用小模型预训练的loss去预测大模型的预计表现,从而确定大模型和数据量的最佳配置。1)建立对应任务测试集上negative log-likelihood和训练消耗算力FLOPs的关系;2)论文中使用之前Lllama2中训练过的模型数据和一些新的小模型;其算力消耗和验证集表现如下:

左图横坐标为训练使用训练出来的模型数据和验证loss的关系,可见相同使用算力下训练数据和loss会有一个最优点,而算力使用越多整个loss是下降,可以拟合出这个算力消耗和loss关系曲线从而预测最优的数据量和模型大小。右图算力对数和训练数据间关系,可以取你能消耗的算力推测出最大模型。
VLM
LLaVa
《Visual Instruction Tuning》
QWen-VL
基于Qwen-7B语言模型,通过引入新的视觉感受器(包括视觉语言对齐的encoder,position-aware adapter),赋予了视觉理解能力。从而能够完成多种任务,包括图像描述、问答和visual grounding。
Architecture
LLM模型基于Qwen-7B预训练权重初始化。Visual Encoder基于ViT,使用了openclip的ViT-bigG权重初始化,训练中resize到固定尺寸,然后把图像切分成块,stride 14,生成多个image features。Position-aware VL adapter,主要用来压缩图像特征,该模块是由可训练的embeddings组成,作为query,视觉encoder的输出作为key做cross attention,最终会把视觉特征序列压缩成256维的固定长度。2D的绝对位置编码在query-key对中也要用到,以避免位置信息的丢失。

image input:为了区分视觉特征和文本特征,在visual features首位添加了特殊tokens(<img></img>)。
bounding box input & output:为了区分检测字符串和普通文本字符串,在bbox字符前后增加特殊tokens(<box></box>),bbox字符格式为"(Xtop_left,Ytopleft),(Xbottom_right,Ybottom_right)"。如果需要关联一些描述性文本,这些文本首位添加特殊tokens(<ref></ref>)。
Training
pretraining stage1:
第一阶段,使用大规模、弱标签、网上爬取的图文对,包括一些公开的数据和内部数据。从5billion图文对清洗到1.4B。冻结LLM模型,只训练视觉编码器、VL adapter。输入图像resize 224x224,训练目标是最小化文本token的交叉熵,最大学习率2e-4,batchsize30720,整个第一阶段50000steps,训练样本近1.5B图像文本对。

multitask pre-training
这一步使用高质量、精细的视觉语言标注数据,有更高的分辨率和图像文本数据。我们同步训练了7个任务,text generation、captioning、VQA、Grounding、ref grounding、grounded cap、OCR、pure-text autoregression。视觉encoder分辨率从224提升到448,降低下采样造成的信息丢失,LLM参数也放开来训练,目标函数和第一阶段一样。

supervised fine-tuning
利用intruction fine-tuing加强指令理解和对话能力,训练出了Qwen-VL-Chat模型。这里使用的数据集还包括了额外的,通过人工标注、模型生成、策略联合来构建的,目的是让模型有localization、多图像理解能力。instruction tuning数据有350k,这个阶段的数据要冻结视觉encoder,优化语言模型和adapter模块。
Data
多任务预训练数据格式如下

自监督数据格式

参考文献
Instruction finetuning: Finetuned Language Models Are Zero-Shot Learners.通过给定指令或指导+-来训练模型,使其按照给定的指导执行特定任务,通常结合强化学习,通过奖励模型正确执行指导的任务,从而优化生成的结果。
prompt tuning:通过在提示词中添加特定提示从而引导模型生成特定类型的响应。整个输入变成了prompt embeddings + input embeddings,输入对应引导任务的结果。
应用
浙江的人形机器人初创企业有鹿机器人近期就基于通义千问开源模型,开发了具身智能大模型LPLM这个“通用机器人大脑”,并达成了一笔超千万的商业订单,证明了这套开源大模型的强大。
百度选择的是与人形机器人头部企业优必选强强联手,共同探索中国AI大模型+人形机器人的应用。优必选人形机器人Walker S通过百度智能云千帆AppBuilder平台接入百度文心大模型进行任务调度应用开发,主要提升快速构建任务规划与执行能力。
腾讯终于交出了「GPTs」和大模型助手 App 的答卷,RoboticsX 机器人实验室也把 AI 模型应用到了自研的机器狗上,但由于腾讯的大模型能力偏向于软件功能侧,机器人企业应用后研发进展缓慢,对于语义理解和控制决策层帮助不大。
最近的消息是,乐聚选择与华为达成战略合作,以华为盘古大模型为核心,结合夸父人形机器人技术,共同探寻并构建通用具身智能解决方案。
VideoChat
《VideoChat:Chat-Centric Video Understanding》
https://github.com/OpenGVLab/Ask-Anything
由于第一种VideoChat-Embed方法是先将video转成text,有一定的信息丢失。所以这里我们选取VideoChat-Embed这部分详细记录。
Model Architecture

在这个结构中,有预训练的ViT-G with Global Multi-head relation Aggregation(GMHRA),有预训练好的QFormer+linear线性映射层(QFormer增加了额外的query tokens来表达视频的上下文)。训练时冻结大部分权重除了新引入的GMHRA、QFormer新增的tokens、线性映射层。
训练分为两个步骤:1)通过大规模视频-文本对来对齐video encoder和LLM。2)利用详尽的视频描述指令数据、视频问答数据微调。
数据
视频多模态指令数据是基于WebVid-10M建立的,对应的详细描述和问答是通过ChatGPT(增加了VIdeoChat-Text生成的文本加入到prompt)生成的。
Video-ChatGPT
《Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models》

Qwen2-VL
《Qwen2-VL: Enhancing Vision-Language Model’s Perception of theWorld at Any Resolution》
Introduction
Qwen2-VL有2B、7B、72B参数量的三个模型,Qwen2-VL的几个主要的贡献是:
1)支持不同的分辨率和纵横比的输入,在DocVQA、InfoVQA、RealWorldQA、MTVQA、MathVista等上获得了SOTA。
2)能够理解超过20min长度的视频
3)可应用于各种设备的鲁棒的agent能力,例如手机、机器人等。
4)支持多种语言。
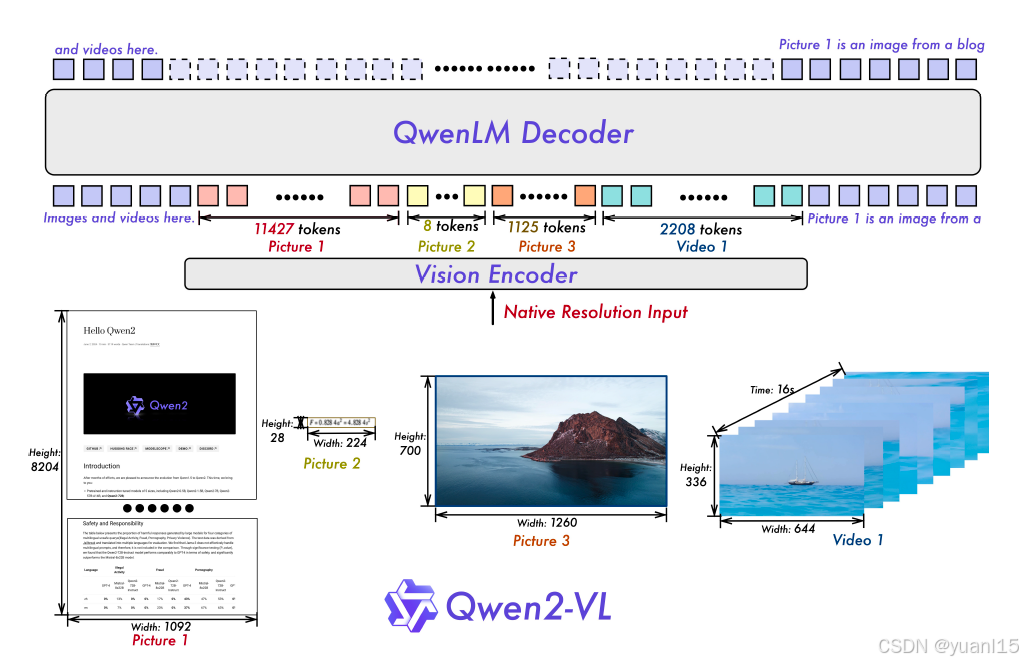
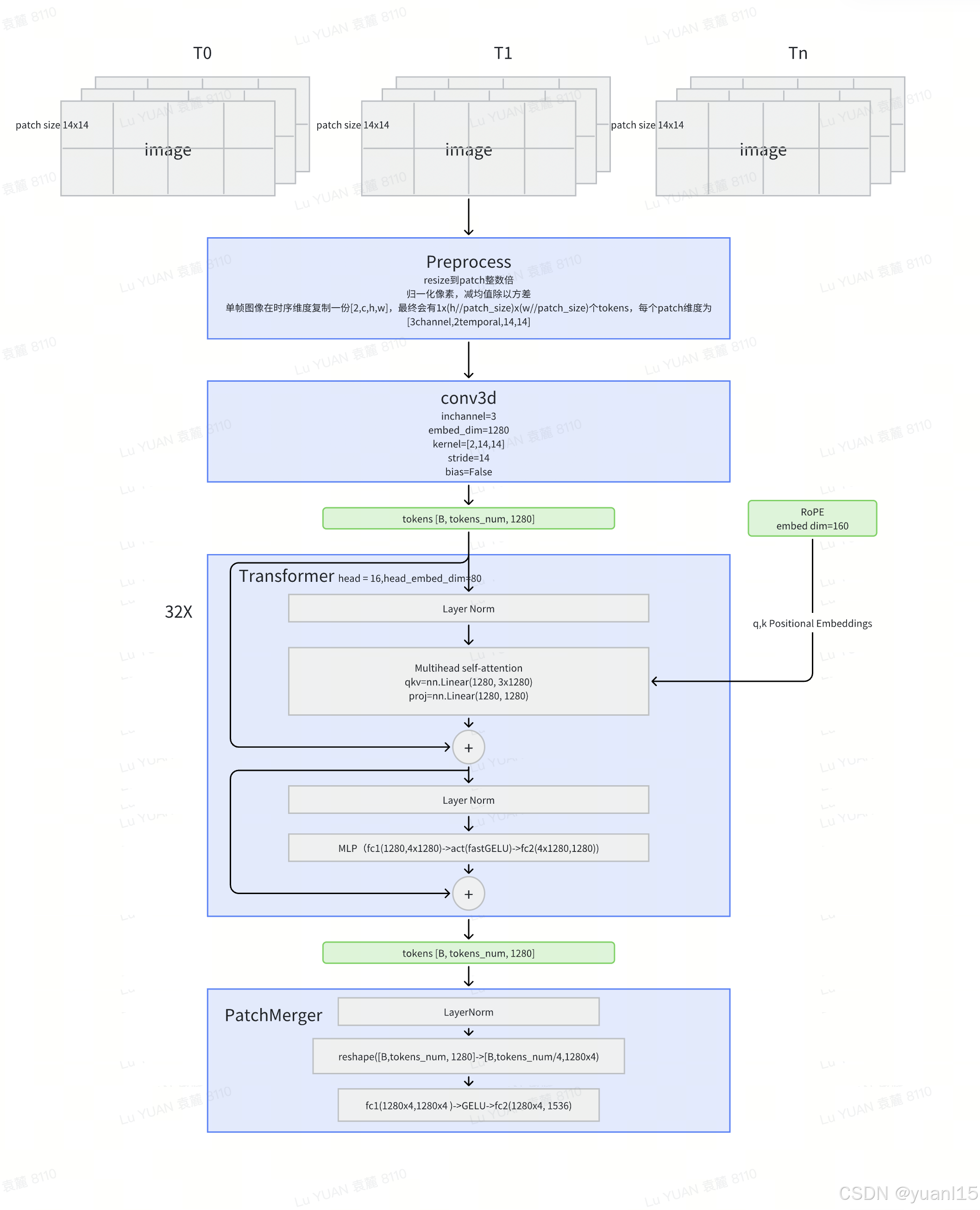
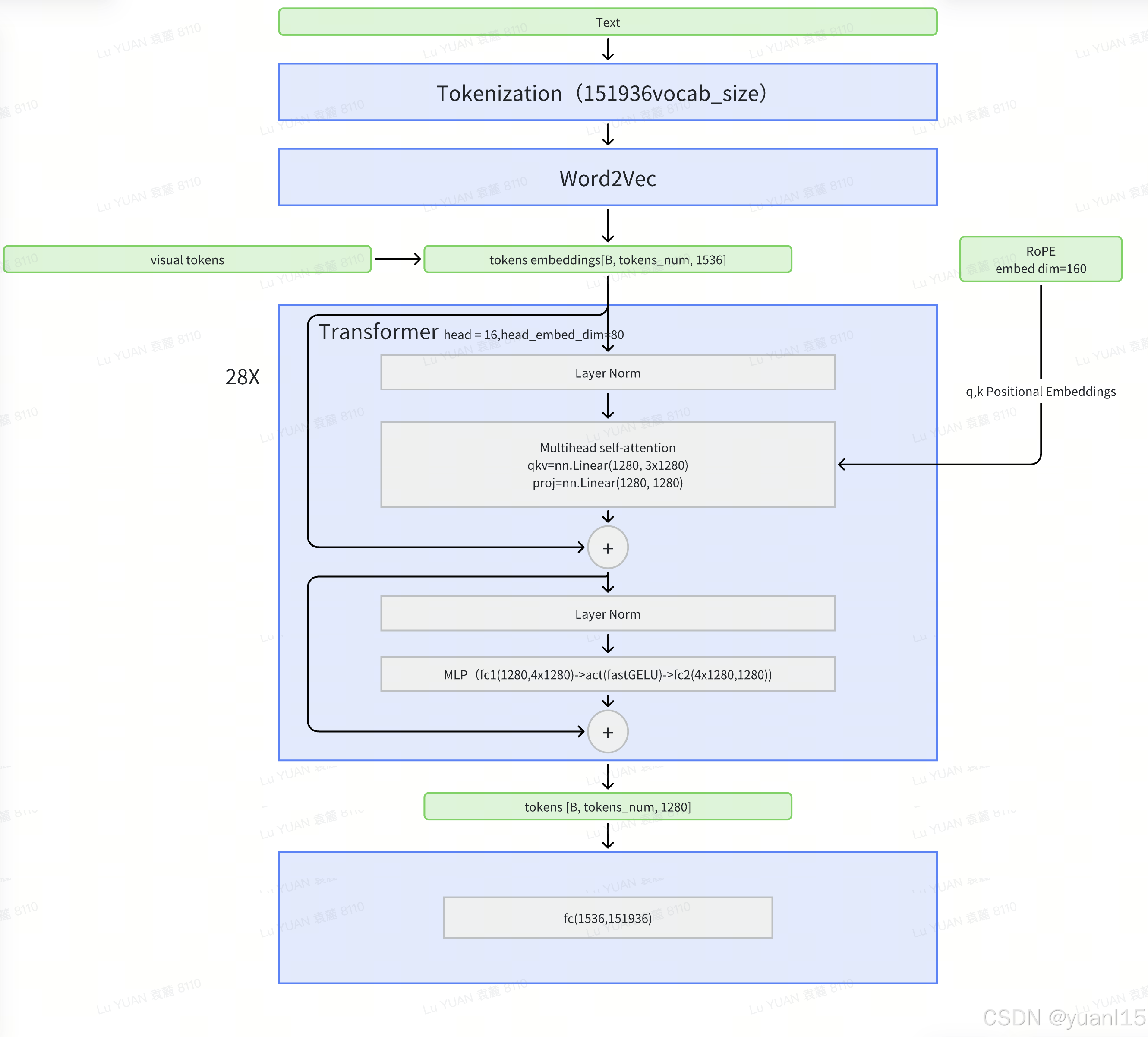
如上是Qwen2-VL的整体架构,保留了Qwen-VL的框架,为了适应不同的尺寸,应用了一个约675million参数量的ViT视觉编码器。
动态分辨率:ViT部分不使用原本的绝对position embeddings,引入了2D-RoPE来获取图像两维位置信息。在推理阶段,图像被打包成一个序列。为了减少每个图像的视觉tokens长度,接入MLP层,将相邻的2x2个tokens压缩成1个token,最后在visual tokens首尾加入<|vision_start|><|vision_end|>特殊token。结果来说,224x224的图像,patch_size=14会被压缩成66个tokens。
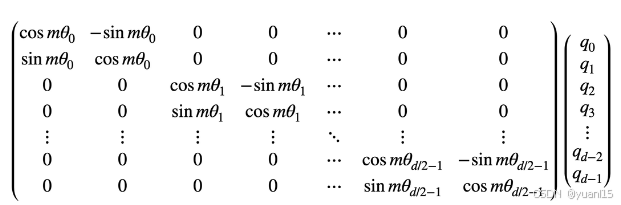
Multimodal Rotary Position Embedding(M-RoPE)
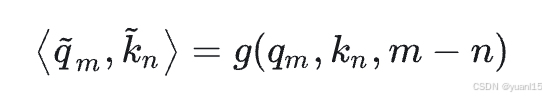 如图所示,qm和kn是经过位置编码后的query和key,位置编码在做的事就是让q和k做内积的结果是q,k及其相对位置m-n的函数,这样就让attention的运算具有了token之间相对位置的信息。 RoPE对于输入x的编码如下,q是x各个维度的数值。
如图所示,qm和kn是经过位置编码后的query和key,位置编码在做的事就是让q和k做内积的结果是q,k及其相对位置m-n的函数,这样就让attention的运算具有了token之间相对位置的信息。 RoPE对于输入x的编码如下,q是x各个维度的数值。
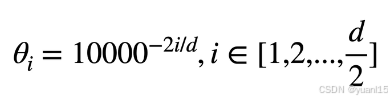
统一图像与视频理解
为了尽可能保存视频信息,我们对视频进行每秒2帧的采样,此外还用了深度为2的3D卷积来处理视频输入,这样模型可以处理3d块而不是2d块。这些方法可以不增加token序列长度去处理更多的视频帧。为了保证一致性,每个图像被当作2帧相同的帧输入模型。在训练阶段,为了平衡长视频处理算力和训练效率,动态地调整每个视频帧的分辨率以限制其tokens在16384以内。
训练
1)第一步聚焦于ViT模块,利用大量的图文对来增强LLM的语义理解;2)二阶段解冻所有参数,用更大的数据来训练模型;3)冻结ViT,用instruct tuning来训练LLM。
LLM参数来自于Qwen2,ViT参数来自于DFN。第一阶段的目标集中于学习图文关系、文本内容识别,数据集来源于OCR、图像分类任务,共计600B tokens。第二阶段包含另外800B tokens的图像相关数据。instruct tuning阶段则包含了一些纯文本对话、多模态对话数据,多模态的数据中有VQA、文档解析、多帧图像对比、视频理解、视频流对话、agent-based interactions。
数据格式
视觉数据<|im_start|><|vision_start|>picture.jpg<|vision_end|> some text <|im_end|>
bbox坐标用[0,1000)归一化,表达成(Xtopleft,Ytop left),(Xbottom right,Ybottom right),如下
<|vision_start|>Picture1.jpg<vision_end|>
<|object_ref_start>the eyes on a giraffe<|object_ref_end|><|box_start|>(,)(,)<|box_end|>
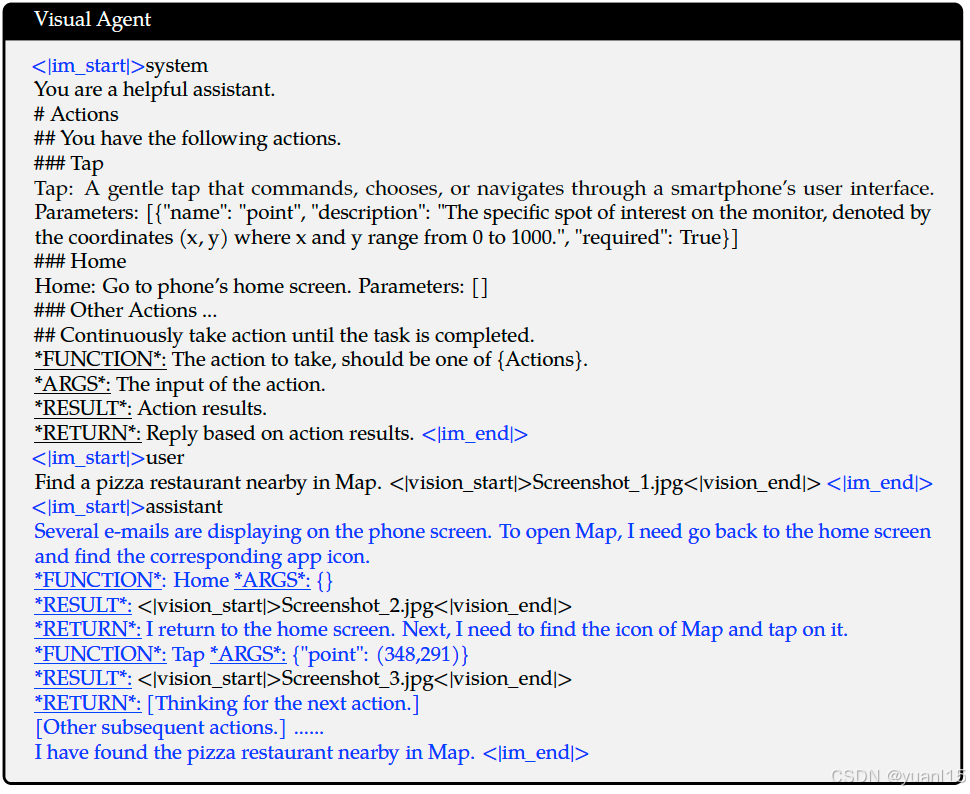
在视觉Agent方面,可以给定一些完成任务可选的action,让了模型持续交互直到完成任务,数据格式如下:
Fine Tuning
全量微调Full-SFT
对整个模型的所有参数进行训练更新,以适应目标任务的需求,这种微调方法通常适用于预训模型和下游任务有较大差异。这种方法会消耗较大计算资源和时间,但是可以获得更好的性能。
部分微调Repurposing
训练只更新模型的部分层参数,如保持底层参数不变,只更新最后几层的参数,这种方法适用于预训练模型和下游任务有一定相似性,或者迁移的任务数据集较小。这种方法消耗资源较少,但是某些情况下会有性能下降。
Prompt Tuning
prompt-tuning不改变预训练模型,而是通过添加少量参数来针对特定任务进行优化,他的缺点就是会占据一部分prompt长度,在Lora的论文中怀疑这是prompt-tuning性能相比其他方法弱的原因。p-tuning分为
1)hard prompt
应用自然语言prompt去引导模型执行不同任务,让他理解用户的指令。(in-context learning)
例如可以通过如下的模板让模型完成不同的任务,而不必去用数据做finetune。
情感分析:“这个电影概要是[X],他部电影是积极的还是消极的:”
主题分析:“Context:[X],这个主题是:”
阅读理解:“Question:[q].Passage:[p].Answer:”
2)soft prompt
最简单的一种形式是在原有的prompt前增加一个可训练的embeddings作为pseudo prompt,即pretrained-model的输入是pseudo prompt + 原来prompt embeddings。如果在pseudo prompt后再加一个MLP层做映射再和prompt embeddings连接到一起输入模型,就是p-tuning。
低秩适配LoRA
《Low Rank Adaptation of large language models》
全量微调是一项资源密集的任务,通常情况下优化器状态、梯度所占的内存空间约为模型的几倍。即使是LLaMA-7B也需要大量计算资源来微调,因此出现了PEFT(参数高效微调),这些微调策略中LoRA(低秩适配)目标就是通过优化较少的参数最大限度地减少资源利用加速训练周期。
LoRA基于的假设是:微调权重和初始预训练权重之间的这种差距可以表示为两个较小的矩阵的乘积,即微调增量矩阵是低秩的,可以用低秩分解的方法去近似全参数微调。如下图所示,保持预训练模型权重不变,通过对附加的A,B两个矩阵进行微调,可以对与预训练模型多层都采用这种方式,其效果会接近于全量微调,同时计算资源却因为AB的低维度而大大降低,但要注意收敛速度不会增快。LoRA的优势总结为这几点:1)可以通过冻结pretrained-model,仅仅替换A、B矩阵高效地迁移各种任务;2)不需要存储全量权重优化信息、梯度信息,可以将硬件资源消耗降低3倍;3)LoRA是简单的线性相加,部署时可以将微调的权重合并到原来的权重,推理时延不会增加;4)LoRA和其他方法是能够组合搭配的,如prefix-tuning。

其等效结果如公式所示,用B是dxr(r是低秩维度,r<<d)维度,A是rxk(k是输入x的维度)维度,是dxd维度:
![]()
应用LoRA到Transformer
transformer架构由4个self-attention权重矩阵(Wq、Wk、Wv、Wo)、2个MLP的权重矩阵,原文中作者只在attention模块用LoRA分解,MLP模块保持freeze。在实验中降低了2/3显存,GPT-3 175B从1.2TB显存降到了350GB,如果设置r=4且只在query、value映射矩阵使用LoRA,checkpoint可以从350GB降到35MB。
LoRA使用经验:
1)哪些权重需要用LoRA?如果训练参数有限,我们只考虑self-attention中的模块使用LoRA,GPT-3 175B在文中就只用了18M参数,r=8。

2)最优的r应选取多少?

3) 和W联系是什么
相比于随机的矩阵,这两个矩阵间有着强烈的相关性,这意味着增强了W中已有的一些特征。增强的特征并不是W中突出的特征,而且其放大因子也很大。
模型小型化
知识蒸馏
《MiniLLM: Knowledge Distillation of Large Language Models》
Metrics
BLEU(Bilingual Evaluation Understudy)
通常用于评估机器翻译和文本生成任务,计算生成文本与参考文本之间的相似度。

 BLEU所依赖的n-gram是NLP中常用的算法,n-gram以滑窗的形式将连续n个词作为一个整体,这样整个句子就分成了很多组,每组长度为n,去跟GT做匹配,匹配上的组数量/机器生成的组数量即为n-gram的评分。很容易理解n越大则代表的语义越完整,1-gram反映有多少词被翻译出来、2-gram以上可以反映译文流畅性。但是n-gram没有反映出GT的召回率,比如GT:“Today is a good day",机器翻译为:“is is is is is“,那么1-gram评分为5/5。所以BLEU对此进行了改进:
BLEU所依赖的n-gram是NLP中常用的算法,n-gram以滑窗的形式将连续n个词作为一个整体,这样整个句子就分成了很多组,每组长度为n,去跟GT做匹配,匹配上的组数量/机器生成的组数量即为n-gram的评分。很容易理解n越大则代表的语义越完整,1-gram反映有多少词被翻译出来、2-gram以上可以反映译文流畅性。但是n-gram没有反映出GT的召回率,比如GT:“Today is a good day",机器翻译为:“is is is is is“,那么1-gram评分为5/5。所以BLEU对此进行了改进:
![]() n-gram在机器翻译译文N-gram出现次数、GT中出现次数最小值。分母为机器译文中n-gram个数,整个pn计算公式如下:
n-gram在机器翻译译文N-gram出现次数、GT中出现次数最小值。分母为机器译文中n-gram个数,整个pn计算公式如下:

以刚才的例子为例来计算Pn=1/5。
那么总的BLEU要将n=1,2,3,4都算进去,进行一个加权平均,因为n越大评分容易越低,要拉平。总的来说BLEU是一个更偏precision的指标。
ROUGE
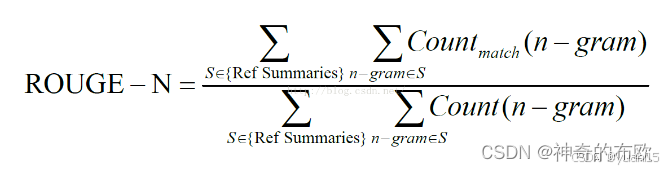
分子是GT和生成匹配上的n-gram数量,分母是参考GT中的n-gram数量。ROUGE更是偏向于recall的指标。常用于评估摘要。
METEOR(metric for Evaluation of Translation with Explicit Ordering)
与BLEU相比,METEOR考虑了更多因素,如同义词匹配、词干匹配、词序等,因此它通常被认为是一个更全面的评价指标。通俗来说METEOR考虑了单词的词形,同时用wordNet等知识源扩充了同义词集,将评估标准放宽了,比如“friend”翻译为“friends”,“buddy”不算错误。他的步骤如下:
1.1-gram对齐,机器翻译结果和参考结果的unigram之间对应关系是一对一或着一对0。选择对应对数最多的匹配方式,同时是映射连线交叉最少的那组(即考虑了词顺序)。
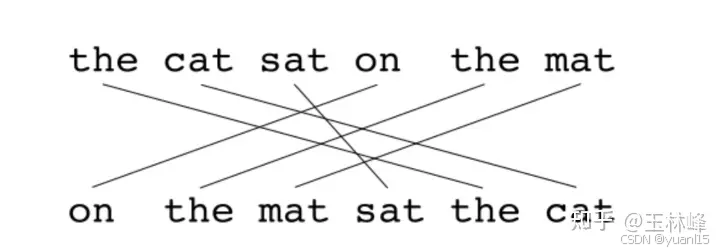
对齐过程是由三个单词映射模块逐步产生的。METEOR扩展了BLEU有关“共现”的概念,提出了三个统计共现次数的模块:
-
一是“绝对”模块("exact" module),即统计待测译文与参考译文中绝对一致单词的共现次数;
-
二是“波特词干”模块(porter stem module),即基于波特词干算法计算待测译文与参考译文中词干相同的词语“变体”的共现次数,如happy和happiness将在此模块中被认定为共现词;
-
三是“WN同义词”模块(WN synonymy module),即基于WordNet词典匹配待测译文与参考译文中的同义词,计入共现次数,如sunlight与sunshine。


应用
DriveVLM
《DRIVEVLM: The Convergence of Autonomous Driving and Large Vision-Language Models》
该文是理想和叉院合作的端到端的智驾方案。为了解决长尾和复杂场景问题,引入VLM大模型,利用大模型能力分别做了场景描述、场景分析、分级规划。除此之外因为大模型的推理性能问题,结合传统自动驾驶系统形成了快慢双系统VLM-dual。
引言:
现有的智能驾驶系统包括了3d感知、运动预测和规划模块,但是对于场景的理解一直表现不好,尤其是3D的感知只能局限于检测跟踪熟悉的目标,运动预测和规划则只关注到轨迹级的动作,忽略了和目标间决策级的交互。
优势:DriveVLM则采用CoT处理三个关键目标:场景描述、场景分析、分级规划,场景描述描绘了驾驶环境、识别关键目标,场景分析则关注关键目标的特性和他们对于自车的影响,分级的规划模块则一步一步地从meta-actions和waypoints描述来形成规划结果。
劣势:VLM优势在于视觉理解,但是空间定位和推理方面能力有限,同时算力消耗比较大。这也是为何要搞双系统的原因,让VLM结合传统的3D感知(如3d检测、占据网络)、规划模块,获得3d定位和高频的规划能力。

1)场景描述:包括环境描述(时间、天气、道路条件等,Eweather、Etime、Eroad、Elane)和关键目标识别(最有可能影响当前场景的关键目标的category、bounding box)
2)场景分析:包括关键目标的静态属性Cs,运动状态Cm,特殊行为Cb。
3)分级规划:场景级的总结和路线、自车姿态还有速度一起形成规划的prompt,最终DriveVLM逐步生成驾驶规划meta-actions->decision description->trajectory waypoints。
Meta-actions是一个短期的决策,共17个类别[acceleration,deceleration,turning left,changing lanes,minor positional adjustments,waiting],为了在一段时间内控制车,本文会生成一个meta-action序列。
Decision Description提供了更细粒度的驾驶策略,包括3个元素action、交互目标约束subject、动作执行时间顺序duration。
Trajectory waypoints生成了自车对应的轨迹{(x1,y1),(x2,y2),...},描绘了未来时刻t内的自车运动轨迹。也是以自回归的方式输出语言tokens得到这些waypoints。
dual system
该文中还提到了快慢系统,由于VLM的推理时延较长,智能驾驶系统对于实时性要求较高,故整个系统是一个经典分模块的智驾系统结合VLM的系统,VLM可以借助3d感知模块的目标检测结果提升自己的location能力,也可以将VLM的规划trajectory给基于优化的规划器作为初始轨迹,也可以作为输入query和其他输入特征f一起给到基于网络的规划器。
Dataset
文章构造了一个SUP数据集(scene understanding for planning),定义任务如下:1)场景描述,天气、时间、道路情况、车道情况;2)场景分析,目标级别的分析和总结;3)任务级的决策;4)详细的驾驶决策描述;5)waypoints规划。
评估方法:1)场景描述的评估是通过一个预训练的LLM,用它去比较GT人工描述和模型生成的描述的一致性。2)决策动作评估是使用LLM生成GT序列的同义序列,增加评测的鲁棒性。
数据集构建,文章从长尾问题中筛选,首先定义一系列长尾问题,如奇怪的车、路上碎石、动物横穿等,接着使用基于CLIP的搜索引擎,挖掘出相关的数据,之后人工检查筛除无关数据。此外还有一些驾驶行为变化数据也是我们感兴趣的挑战场景。这些数据都是短视频clips,我们挑选这些场景中速度显著变化、方向变化的钱0.5s~1s作为关键帧,如果没有驾驶动作的变化,则选择和当前场景相关的一帧作为关键帧。
如下图是标注结果,还会有3个标注人员检查,确保结果一致。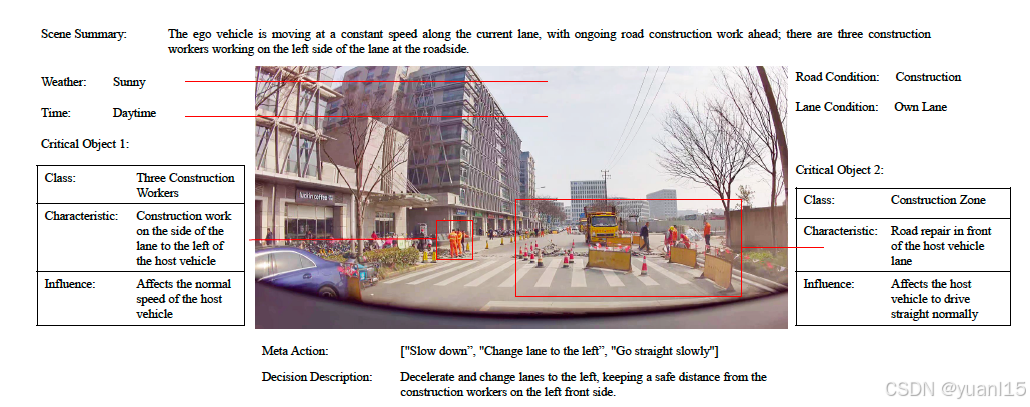
训练
除了SUP数据集,为了保持模型的通用性能,还引入了其他训练集做联合训练,包括了nuScenes数据集、Talk2Car,BDDX,Drama,SUTD,和LLAVA数据集,采样比例与SUP-AD、nuScenes数据集保持1:1,这样下来SUP-AD性能没变,但是保留了其他任务的能力。基础模型是采用的Qwen-VL 7B,输入图像是T,T-1,T-2,T-3时间降序排列。最终SUP-AD上效果比GPT-4V好,nuScenes规划数据集上双系统取得了SOTA超过VAD。
部署
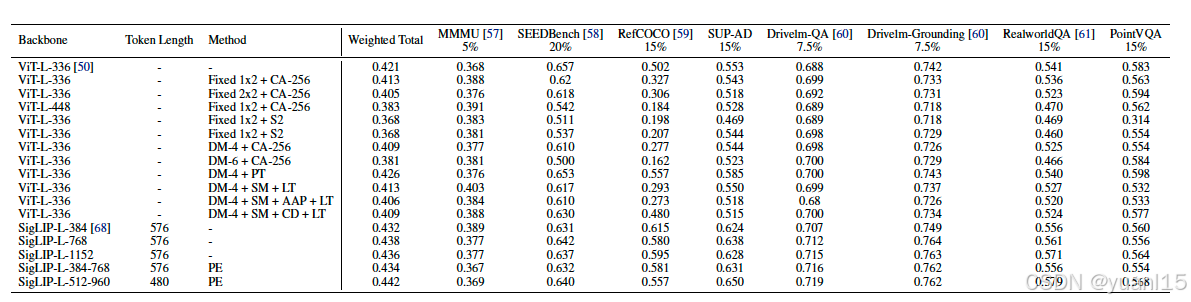
在基础模型选型时,作者也在不同的测试集上对使用公开数据集+SUP数据集微调后的模型进行了latency和performance测试,如下图所示,Base LLM在不同的数据集上的测试结果,并且作者给了更关注的一些测试集更高的权重以获得最终综合评分。可以看到Qwen系列的模型效果更好。

如下图是推理时延的结果,层数更少但是特征更多的Qwen系列推理时间更短。

visual encoder对比选择
 visual Token compression,利用了LDPNetv2来减少了75%的图像token,而不牺牲性能。还通过将LDPNetv2中的average pooling换成卷积层提升了性能。
visual Token compression,利用了LDPNetv2来减少了75%的图像token,而不牺牲性能。还通过将LDPNetv2中的average pooling换成卷积层提升了性能。

时序融合方面,作者应用了一个短期memorybank策略,将历史帧的visual feature存下来,在映射到LLM前,将本时刻的特征和历史特征进行融合,多帧间融合权重文中是引入了SE blocks给权重。
SUP-AD Dataset
meta-actions可以划分为三大类速度控制(speed up,slow down,slow down rapidly,go straight slowly, go straight at a constant speed,stop,wait,reverse)、转向(turn left,turn right, turn around)、车道控制(change lane to left,change lane to the right, shift slightly to the left,shift slightly to the right)。
sup数据有1000clips横跨40个场景类别。
环境描述评测,文中引入了GPT4,给出prompt让他去对比GT和output关键信息相同,并且根据分数计算方法给出评分。meta action评测中,会让GPT4生成GT meta actions的同义序列,然后利用DP动态规划去做GT和Ref匹配,多余的计为redundant,没匹配上的即为missing,最后除以meta-action的长度。
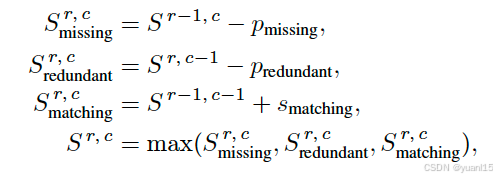
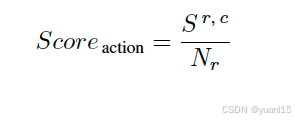
PlanAgent
《PlanAgent:A Multi-modal Large Language Agent for Closed-loop Vehicle Motion Planning》
架构

整体由三部分组成,Environment transformation负责从环境中提取关键信息构建BEV map和基于车道图的文本描述作为第二个模块Reason Engine的场景prompts,Reason Engine生成规划结果,最终Reflection模块评估这个规划结果。
Environment Transformation:这个模块将场景信息分为全局和局部信息。全局信息(BEV Map)代表场景类型,提供自车运动规划的先验信息,如在环形交叉路口要注意汇入车辆、单行车道禁止变道等等。局部信息(lane-graph转化成文本描述)表示自车和周边其他车的运动,这些信息直接影响到自车横向纵向动作规划。
BEV Map:首先从环境中提取地图信息、他车信息和障碍物信息,地图信息包含1)中心线2)人行横道3)车道;目标信息包括4)自车5)他车6)两轮车7)行人,障碍物信息表示8)静态障碍物。在建立BEV map时,这8个道路元素用不同的颜色可视化来加强多模态大模型对道路结构的理解。为了描绘场景动静态信息,每一个目标用红色箭头表征他的速度信息。
Textual Description:之前的方法把所有的agent信息和道路信息直接以数学坐标的方式送给LLM模型,这是冗余且无效的,而且大量的坐标不一定能和LLM的语义空间相适应。将每一段路等分成多个节点,节点的位置和连接关系提供了一个好的语义和几何表达。如下图所示将,一个三车道场景,每一个节点周边有8个相邻的节点,我们把节点间的位置和连接关系转化为文本描述,以有效地表达现实世界中道路信息。为了保证信息有效性,我们只保留八个相邻节点的目标、障碍物、交通灯信息(速度、距离)。

Reasoning Engine
引入MLLM的目的,就是希望借助大模型的常识、逻辑推理、泛化能力解决自动驾驶领域的问题。如上所述,multimodal Large language models的输入是ETM模块的环境信息prompt加上预设的系统prompts。紧接着MLLM通过多轮的分级思维链指引下的推理,应用IDM规划器(nuPlan提供的规划器)生成规划结果。提示词分为两部分:1)场景提示词,用以描述场景2)系统提示词,定义任务、导入驾驶常识、指引分级推理。(这里MLLM没有做微调,直接用的GPT-4V),所以你的提示词需要提供任务定义、格式,还有合理的planner生成样例(讲清楚调用IDM的输入参数代表着什么)。同时这里还引入了思维链指导MLLM一步一步理解场景、给出action规划、生成规划器调用代码。

Reflection
MLLM生成的规划结果有不确定性,生成的决策会进入PDM-Closed中的仿真(评估潜在的碰撞等级)进行评分,如果低于阈值Reasoning Engine会被要求重新生成新的规划。为了减少长时间仿真的累积误差,我们只进行短期的仿真,同时约束重新决策的次数,超过次数采用最后一次的决策。
Result


















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









