







 本文介绍KeepAugment方法,通过引入显著性映射来衡量图像区域的重要性,并据此优化数据增强过程,避免重要区域被遮挡或修改,从而提高模型性能。
本文介绍KeepAugment方法,通过引入显著性映射来衡量图像区域的重要性,并据此优化数据增强过程,避免重要区域被遮挡或修改,从而提高模型性能。

论文链接:https://arxiv.org/pdf/2011.11778.pdf.
CVPR 2021
1 Background
近年,数据增强在解决很多深度学习的问题上是一个至关重要的的技术。比较典型的例子有区域级数据增强方法,它的mask或者修改是随机选择图像的矩形区域。还有图像级增强方法,它是利用加强学习来发现选择和组合不同的标签不变性变换】的最优策略。
虽然数据增强增加了有效数据的大小,并且提升了训练样本的多样性,但是它不可避免的在训练过程中引入了噪声和歧义性。因此如果数据增强没有被适当的调整的话,整个性能将会变坏
虽然KeepAugment是一个非常简单并且没有消耗资源,但是在不同视觉任务上的结果证明我们可以显著提升现有的数据增强baseline。特别的,对于图像分类,我们实现了实质性提升在现存的数据增强技术上,跨各种神经结构提高CIFAR-10和ImageNet的性能。此外,本文的方法可以应用到自监督学习上,使用本文的方法训练的 ImageNet模型可以被应用到COCO 2017目标检测任务上,并且允许我们去提升强壮的 Detectron2的baselines
下面了解一下数据增强以及几种特殊的数据增强方法:
- 数据增强(DA)是实现深度学习有效涨点的技巧;
- 在计算机视觉方向,数据增强的本质是人为地引入人视觉上的先验知识,可以很好地提升模型的性能,目前基本成为模型的标配;
- 数据增强的作用:(1)避免过拟合(2)模型鲁棒性,降低模型对图像的敏感度(3)增加训练数据,提高模型泛化能力(4)避免样本不均衡;
- 数据增强的分类:(1)离线增强是在训练前对数据集进行处理,往往能得到多倍的数据集,适用于小型数据集 ;(2)在线增强是在训练时对加载数据进行预处理,不改变训练数据的数量,适用于大型数据集;
- 常用的方法: (1)几何变换方法主要有:翻转,旋转,裁剪,缩放,平移,抖动(要注意标签数据的变换);(2)像素变换方法主要有:加椒盐噪声,高斯噪声,进行高斯模糊,调整HSV对比度,调节亮度,饱和度,直方图均衡化,调整白平衡等。
Cutout(2017):对一张图像随机选取一个小正方形区域,在这个区域的像素值设置为0,分类的结果不变;依据是Cutout能够让CNN更好地利用图像的全局信息,而不是依赖于一小部分特定的视觉特征。

Random Erasing(2017):类似于Cutout,这两者同一年发表的。与Cutout不同的是,Random Erasing mask区域的长宽,以及区域中像素值的替代值都是随机的,Cutout是固定使用正方形,替代值都使用同一个。

- Hide-and-Seek(ICCV 2017):主要思想就是将图片划分为S x S的网格,每个网格按一定的概率(0.5)进行mask。其中不可避免地会完全mask掉一个完整的小目标。

- Mixup(ICLR 2018):将在数据集中随机选择两张图片按照一定比例融合,包括标签值。


- CutMix(ICCV 2019):该方法结合了Cutout、Random erasing和Mixup三者的思想,做了一些中间调和的改变,同样是选择一个小区域,进行mask,但mask的方式却是将另一张图片的该区域覆盖到这里。

- GridMask( arxiv 2020):对前几种方法的改进,由于前几种对于mask区域的选择都是随机的,因此容易出现对重要部位全掩盖的情况。而GridMask则最多出现部分掩盖,且几乎一定会出现部分掩盖。使用的方式是排列的正方形区域来进行掩码(具体实现是通过设定每个小正方形的边长,两个mask之间的距离d来确定mask,从而控制mask细粒度)。


-
FenceMask(arxiv 2020):对前面GridMask的改进,认为使用正方形的掩码会对小目标有很大的影响。因此提出了更好的形状,FenceMask具有更好的细粒度。

-
AutoAugment(CVPR 2019):利用增强学习来找到用于选择和组合不同的标签不变变换(例如,旋转、颜色反转、翻转)的最佳策略,训练一个policy去选择合适的augment参数。

-
Fast Autoaugment(NeurIPS 2019) :借鉴AutoAugment的基础上,实现了大幅的提速。它提出了一种方法,避免了调整不同数据增强参数不停的重复训练网络这个超级消耗GPU的步骤,从而获得了100-1000倍的速度提升。

-
RandAugment(CVPR 2020):与AutoAugment是同一个作者。 AutoAugment 的缺点:(1)大规模采用这样的方法会增加训练复杂性、加大计算成本;(2)无法根据模型或数据集大小调整正则化强度。 RandAugment可以将数据增广所产生的增量样本空间大大缩小,从而使其可与模型训练过程捆绑在一起完成,避免将其作为独立的预处理任务来完成。


2 Motivation
- 尽管数据增强会增加有效数据的大小并增加训练的数据的多样性,但仍不可避免地在训练过程中引入具有噪声和歧义的增强样本,从而在推理过程中损害为增强数据的性能。keepAugment提出了一种简单但是高效的方法,以提高增强图像的保真度。

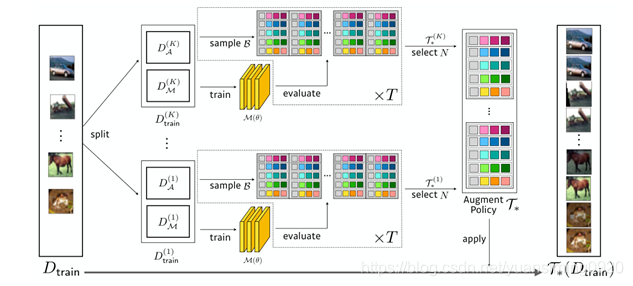
3 Related Work
keepAugment的工作主要关注标签不变的数据增广方法:
- keepAugment的工作主要关注标签不变的数据增广方法 。eg,Cutout, CutMix, random erasing
- Image-Level Augmentation:利用增强学习来找到用于选择和组合不同的标签不变变换(例如,旋转、颜色反转、翻转)的最佳策略。eg, RandAugment ,Fast AutoAugment , AutoAugment
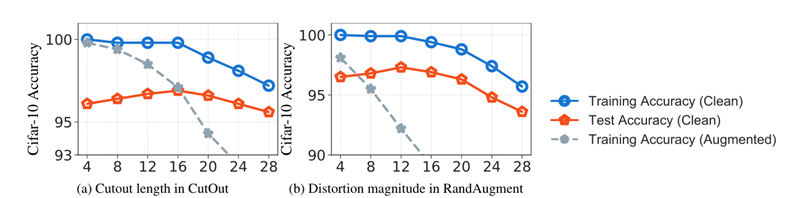
- Data Augmentation and its Trade-offs:图的意思就是:蓝色线表示没有做任何数据增强的情况下训练集的Acc,灰色线表示使用了CutOut和RandAugment方法增强之后的数据集(没有使用本文的方法)。意思就是训练集分为两部分,一部分是没有增强的(蓝色线),一部分是随机增强的(灰色线)。那为什么蓝色线和红色线也会随着横坐标发生变换呢?因为增强后的数据会影响不增强的数据,因此就得到了下图。

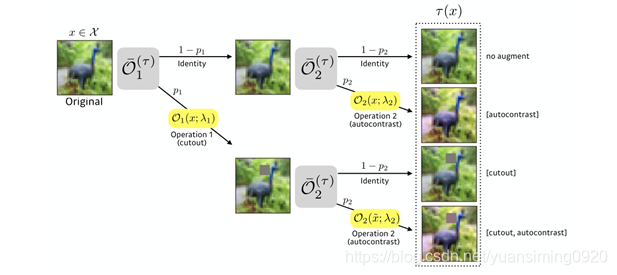
4 Methods
keepAugment的思路是通过saliency map测量矩形区域内的重要性,并确保在数据增强后保留重要性得分高的重要区域

4.1.Saliency Map
Saliency Maps简单来说可以理解为是用来做模型的解释,可以用来知道哪些变量对于模型来说是重要的。我们也可以理解为Saliency map即特征图,可以告诉我们图像中的像素点对图像分类结果的影响.

矩形区域S的重要性分数为:

- x x x表示图像
- y y y表示label
- S S S表示图像矩形区域
- g i j ( x , y ) g_{ij}(x,y) gij(x,y)表示图像 x x x在像素 ( i , j ) (i,j) (i,j)的 saliency map
-
g
i
j
(
x
,
y
)
g_{ij}(x,y)
gij(x,y)为 vanilla gradients的绝对值
∣
▽
x
l
y
(
x
)
∣
|\bigtriangledown _{x}l_{y}(x)|
∣▽xly(x)∣,
l
y
(
x
)
l_{y}(x)
ly(x)为标签的 logit value

4.2.Selective-Cut
对于region-level的数据增强方法,确保切割的区域不会具有较大的重要性得分来控制数据增强的保真度


- M ( S ) = [ M i j ( S ) ] i j M(S)=[M_{ij}(S)]_{ij} M(S)=[Mij(S)]ij为区域 S S S的 binary mask
-
M
i
j
=
I
(
(
i
,
j
)
ϵ
S
)
M_{ij}=\mathbb{I}((i,j)\epsilon S)
Mij=I((i,j)ϵS)

4.3.Selective-Paste
image-level的数据增强修改了整个图像,通过粘贴具有较高重要性的区域来控制数据增强的保真度

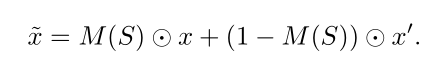
- M ( S ) = [ M i j ( S ) ] i j M(S)=[M_{ij}(S)]_{ij} M(S)=[Mij(S)]ij为区域 S S S的 binary mask
- M i j = I ( ( i , j ) ϵ S ) M_{ij}=\mathbb{I}((i,j)\epsilon S) Mij=I((i,j)ϵS)
-
x
′
x^{'}
x′为图像级方法增强后的图像

4.4.Remark
这里蓝色线和红色线的意义和上边的一样,灰色线是本文中的keepcutout和keeprandaugment,虚线则是cutout和randaugment数据集训练之后的测试结果,它和本文方法没有关系,因此不随横坐标发生变化。
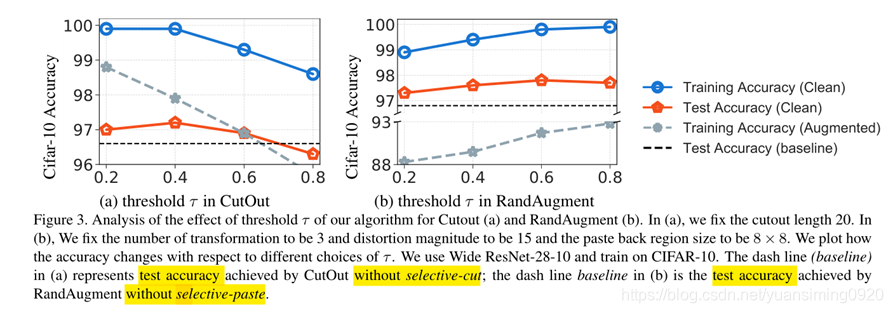
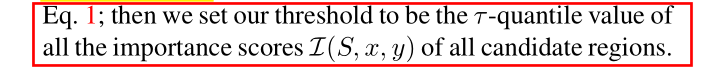

5 Experiments
5.1.Dataset
- CIFAR-10
- ImageNet
- COCO 2017
- Market1501
5.2.CIFAR-10 Classification

1) Training Time Cost

2) Improve on CutOut
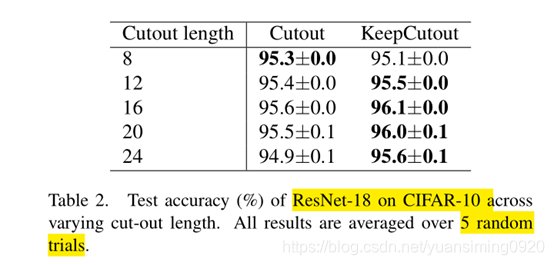
3) Improve on AutoAugment
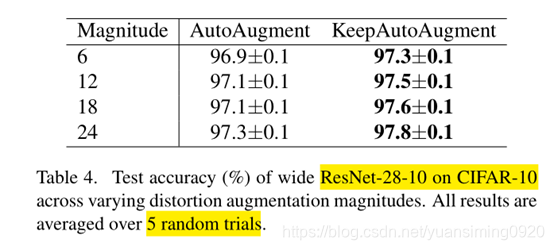
4) Additional Comparisons on CIFAR-10

5.3. ImageNet Classification

5.4. Semi-Supervised Learning

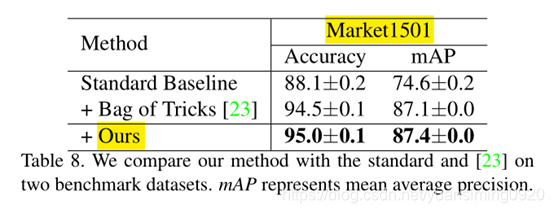
5.5. Multi-View Multi-Camera Tracking
5.6.Transfer Learning: Object Detection



6 Conclusions
- 这篇文章分析表明现有的数据增强方法可能会引入噪音或者歧义的增强样本,从而限制了它们提高整体性能的能力。因此作者使用saliency map来衡量每个区域的重要性,并提出避免避免区域级数据增强方法(例如cutout)切割重要区域;或从原始数据中粘贴关键区域以进行图像级数据增强(例如RandAugment)。总之,KeepAugment是一项能够数据增强有效性的通用方法。

















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









