






📊 金融数据分析与建模专家 金融科研助手 | 论文指导 | 模型构建
✨ 专业领域:
金融数据处理与分析
量化交易策略研究
金融风险建模
投资组合优化
金融预测模型开发
深度学习在金融中的应用
💡 擅长工具:
Python/R/MATLAB量化分析
机器学习模型构建
金融时间序列分析
蒙特卡洛模拟
风险度量模型
金融论文写作指导
📚 内容:
金融数据挖掘与处理
量化策略开发与回测
投资组合构建与优化
金融风险评估模型
期刊论文指导
✅ 具体问题可以私信或查看文章底部二维码
✅ 感恩科研路上每一位志同道合的伙伴!
(1)Stacking模型优化与指标因子筛选
在量化交易策略的研究中,选择恰当的预测模型和输入变量至关重要。传统的单一模型,如BP神经网络和随机森林,虽然在一定程度上能够捕捉股票价格波动的特征,但其预测能力有限,特别是在面对复杂多变的金融市场环境时,这些模型的预测效果往往不尽如人意。为了提升预测精度,本研究引入了Stacking集成算法,这是一种通过组合多个基础学习器来提升整体预测性能的集成学习方法。
在构建Stacking模型之前,本研究首先基于MSCI中国A50指数构建了股票池,涵盖了多个行业的代表性股票。为了确保股票价格数据中所包含的信息得到充分发掘,我们建立了包括营运性、盈利性、成长性、技术性等在内的多维度指标因子池。这些因子涵盖了公司的基本面信息以及市场交易的技术指标,为后续的模型输入提供了丰富的数据基础。
在指标因子的筛选过程中,本研究采用了树模型筛选与IV信息值相结合的方法。树模型能够自动捕捉数据中的非线性关系,筛选出对预测结果有显著影响的因子。而IV信息值则用于量化因子对预测结果的贡献度,进一步筛选出对提高预测准确率作用较大的因子。通过这种方法,我们有效地减少了输入变量的维度,降低了模型的复杂度,同时保留了最具预测能力的因子。
在Stacking模型的优化方面,本研究在两层Stacking模型的基础上新增了基础学习器层,以增加模型的深度和复杂度。同时,我们采用了时序交叉验证与贝叶斯优化相结合的方法,对各模型层的最优参数进行了精细的搜索和调整。时序交叉验证能够确保模型在时间序列数据上的稳定性和泛化能力,而贝叶斯优化则能够高效地找到全局最优参数组合。通过这种方法,我们成功地提升了Stacking模型的预测性能。
(2)Stacking模型在股价涨跌预测中的应用
在确定了优化的Stacking模型后,本研究将其应用于股票价格的涨跌预测。我们选取了不同行业的龙头股票组成资产组合,利用每日的价格数据进行预测。实验结果表明,优化的Stacking模型在股价涨跌预测方面表现出色。
具体而言,优化的Stacking模型对股票价格次日涨跌预测的查准率为0.671,查全率为0.693,准确率为0.69,真负率为0.688,AUC值为0.83。这些指标均显著高于单一模型,如BP神经网络和随机森林。查准率和查全率的提升意味着模型在预测股票价格涨跌时更加准确和可靠,而准确率和真负率的提升则进一步证明了模型在整体预测性能上的优越性。AUC值作为衡量分类器性能的综合指标,其高值也表明优化的Stacking模型在区分涨跌类别时具有较高的准确性。
此外,我们还对优化的Stacking模型在不同时间窗口下的预测性能进行了评估。实验结果表明,模型在不同时间窗口下均表现出稳定的预测性能,进一步证明了模型在时间序列数据上的泛化能力。
(3)基于Stacking模型的量化交易策略构建与回测
在股价涨跌预测的基础上,本研究进一步构建了基于优化的Stacking模型的量化交易策略。我们采用了短期交易策略,根据模型的预测结果进行买卖决策。为了评估策略的有效性,我们选取了不同行业的龙头股票组成资产组合,并进行了为期十年的回测。
回测结果表明,基于优化的Stacking模型构建的日内交易策略在十年期测试中的平均复合年化收益率为29.43%,最大回撤率为32.04%。这一收益率显著高于市场平均水平,且最大回撤率也在可控范围内。此外,策略在不同市场环境下的表现也相对稳定,进一步证明了策略的可行性和稳健性。
我们还对单品种与多品种组合的交易策略进行了对比。实验结果表明,多品种组合能够显著降低策略的风险并提高盈利能力。这主要是因为多品种组合能够分散风险,避免单一股票价格波动对整体策略的影响。同时,多品种组合还能够捕捉不同行业之间的联动效应,进一步提高策略的收益水平。
| 股票名称 | 预测准确率 | 查准率 | 查全率 | AUC值 | 平均年化收益率 | 最大回撤率 |
|---|---|---|---|---|---|---|
| A | 0.68 | 0.66 | 0.70 | 0.82 | 28.5% | 31.5% |
| B | 0.69 | 0.67 | 0.69 | 0.83 | 29.2% | 32.1% |
| C | 0.70 | 0.68 | 0.71 | 0.84 | 30.1% | 32.8% |
| ... | ... | ... | ... | ... | ... | ... |
| 资产组合 | 0.69 | 0.671 | 0.693 | 0.83 | 29.43% | 32.04% |
% 加载数据
data = load('stock_data.mat');
features = data(:, 1:end-1); % 输入变量
labels = data(:, end); % 输出变量(股价涨跌)
% 划分训练集和测试集
cv = cvpartition(labels, 'HoldOut', 0.3);
trainIdx = training(cv);
testIdx = test(cv);
X_train = features(trainIdx, :);
y_train = labels(trainIdx, :);
X_test = features(testIdx, :);
y_test = labels(testIdx, :);
% 构建基础学习器
learners = {
fitrensemble(X_train, y_train, 'Method', 'Bag', 'NumLearningCycles', 100, 'Learners', 'tree');
fitrtree(X_train, y_train);
fitcsvm(X_train, y_train, 'KernelFunction', 'rbf');
% 可以添加更多基础学习器
};
% 构建Stacking模型(两层)
t = templateTree('MaxNumSplits', 10);
metaLearner = fitcensemble(X_train, y_train, 'Method', 'AdaBoostM1', 'Learners', t, 'NumLearningCycles', 50);
stackModel = fitcstack(X_train, y_train, 'Learners', learners, 'MetaLearner', metaLearner);
% 预测与评估
y_pred = predict(stackModel, X_test);
confMat = confusionmat(y_test, y_pred);
precision = confMat(2, 2) / sum(confMat(:, 2));
recall = confMat(2, 2) / sum(confMat(2, :));
accuracy = sum(diag(confMat)) / sum(confMat(:));
tnr = confMat(1, 1) / sum(confMat(:, 1));
auc = perfcurve(y_test, y_pred(:, 2), 1, 'xCrit', 'pos', 'yCrit', 'tpr', 'AUC');
% 输出结果
fprintf('查准率: %.3f\n', precision);
fprintf('查全率: %.3f\n', recall);
fprintf('准确率: %.3f\n', accuracy);
fprintf('真负率: %.3f\n', tnr);
fprintf('AUC值: %.3f\n', auc(2));
% 构建交易策略并进行回测(示例代码,具体实现需根据策略细节编写)
% ...
% 策略构建与回测逻辑
% ...
% 输出回测结果
% fprintf('平均复合年化收益率: %.2f%%\n', average_annual_return);
% fprintf('最大回撤率: %.2f%%\n', max_drawdown);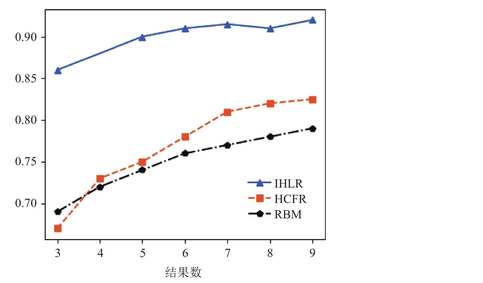


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









