







Trajectory Similarity Join in Spatial Networks
一.问题:
给定轨迹集P、Q和一个阈值θ,轨迹相似度连接(TS-Join)从这两个集合中找到一个时空相似度超过θ的所有轨迹对的集合a
二BASELINE ALGORITHM
1.Basic Idea
时间优先匹配(TF-Matching)是一个简单的基线方法来计算TS-Join。首先,我们使用层次网格结构来索引时域。然后通过计算轨迹对的时空相似性来细化同一叶节点上的轨迹对(章节3.2和3.3)。通过将叶子节点的结果归并到根节点,当到达根节点时,就会得到连接结果(章节3.4)。利用上下边界对搜索空间进行时空裁剪。每个网格级别的计算可以并行执行。
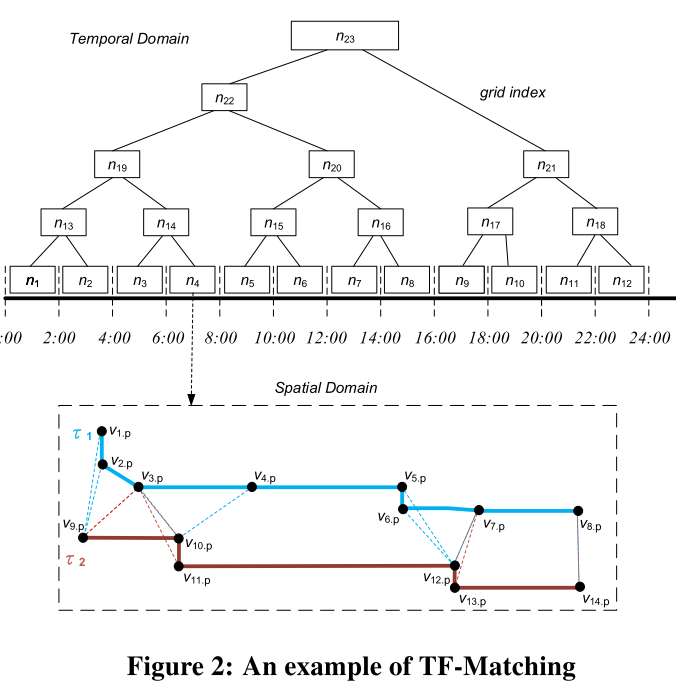
2.Grid Index
网格索引结构建立如下:首先,我们将时域划分为大小相等的时隙,每个时隙对应一个叶节点。接下来,我们以自底向上的方式构建树形结构。
3.Upper and Lower Bounds
我们估计了时间相似度的上界,τ1, τ2。
3.Merging
在计算了叶节点中轨迹对的时空相似性后,我们将叶级的计算结果迭代(自底向上)合并到根级。我们将两个叶节点na和nb合并到它们的父节点nc中
TWO-PHASE ALGORITHM
1Basic Idea
TF匹配有三个主要缺点。首先,该算法由时域驱动,具有较弱的空间裁剪能力。该算法需要处理大量的轨迹对,影响了算法的性能。第二,更多的叶节点(更多的线程)导致更高的合并成本,这不利于并行处理。第三,它可能需要额外的计算来获取网络距离来计算空间相似性(公式1和3),这再次降低了性能。
为了更有效地处理TS-Join,我们开发了一个基于分治策略的两阶段算法(见图3(a))。(1)在轨迹搜索阶段,对于每个轨迹τ P,我们同时探索空间和时间域,并搜索接近τ的轨迹。在空间域,利用每个轨迹样本点的网络扩展[9]来探索空间网络,在时间域,从τ的每个时间戳展开搜索。定义了时空相似度的上界,使搜索空间能够在时空域进行剪枝。此外,提出了一种启发式调度策略,对多个所谓的查询源(空间域上的样本点,时间域上的时间戳)进行有效调度,以进一步提高效率。不同轨迹的搜索过程是相互独立的,因此可以并行进行轨迹搜索。此外,在轨迹搜索过程中,可以直接推导出用于相似度计算的网络距离。(2)在合并阶段,结合所有轨迹的计算结果,求出TS-Join的解。与TF-Matching相比,合并成本现在与线程数量无关。两阶段算法比时间优先匹配算法具有更好的时间复杂度。
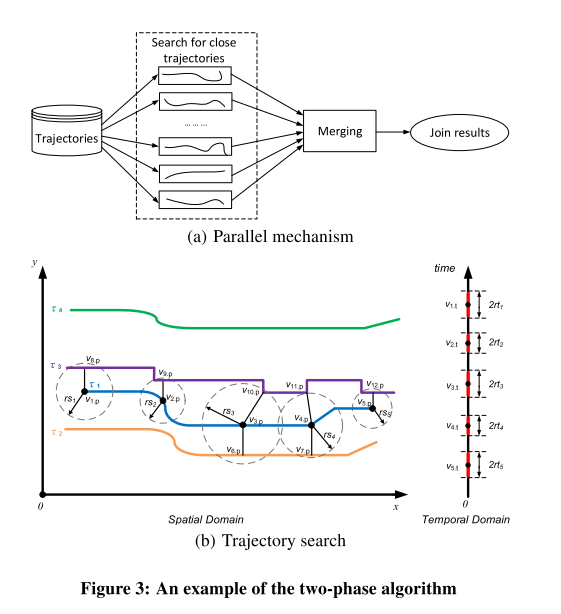
Expansion Search
在空间域中,使用Dijkstra算法从每个样本点vi.p∈τ1进行网络扩展; 在时间域,我们从每个时间戳vi.t τ1扩展搜索。所探索的空间是一个时间范围[vi.t rti, vi.t + rti]
Upper Bound Computation
Filter, Refine, and Merging
如果部分扫描轨迹的全局上界UB小于阈值θ,则在空间域和时间域内的扩展终止,所有在这两个域内未被完全扫描的轨迹都可以安全地进行裁剪。对于每个全扫描轨迹τ,我们有d(vi)的精确值;因此,我们可以进一步细化空间、时间和时空的上限














 564
564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









