







Computing Trajectory Similarity in Linear Time: A Generic Seed-Guided Neural Metric Learning Appr...
摘要:现有的轨迹相似测度计算成本高,已成为尺度轨迹分析的关键瓶颈。虽然已经有很多关于降低复杂性的研究,但它们都是针对一种相似度度量,通常只能产生有限的加速。为了加快轨迹相似度计算,我们提出了NEUTRAJ算法。NEUTRAJ是通用的,以适应任何现有的轨迹测量,并快速计算一个给定的轨迹对的相似性在线性时间。此外,NEUTRAJ可以灵活地与所有基于空间的轨迹索引方法协作,减少搜索空间。NEUTRAJ从给定的数据库中采样大量的种子轨迹,然后使用它们的成对相似度作为指导,使用神经度量学习框架逼近相似函数。NEUTRAJ的两个新模块实现了相似函数的精确逼近:(1)空间注意记忆模块,增强了现有的循环神经网络的轨迹编码;(2)距离加权排序损失,有效地从基于种子的指导中转录信息。使用这两个模块,NEUTRAJ可以在训练数据较小的情况下产生较高的精度和较快的收敛速度。我们在两个真实的数据集上进行的实验表明,NEUTRAJ在Fr echet、Hausdorff、ERP和DTW测量上达到了80%以上的准确性,持续且显著地优于当前最先进的基线。它获得50x1000x加速比bruteforce方法和3 -500x加速比现有的近似算法,同时产生更精确的相似函数近似。
模型:我们提出了一个模型,大大加快了轨迹相似度计算的任何措施。我们提出的模型名为NEUTRAJ,是一种基于神经度量学习的近似方法。NEUTRAJ从数据库中对种子轨迹库进行采样,并使用它们的配对相似性作为指导。具体来说,NEUTRAJ学习了一个神经网络,该神经网络联合嵌入输入轨迹并逼近距离函数。它具有以下吸引人的特点
1)•通用:与以往的方法不同,NEUTRAJ是通用的,可以支持任何现有的方法。因此,它可以用于加速大多数轨迹挖掘任务。
2)快速:给定一对特殊轨迹,NEUTRAJ能够以O(L)时间复杂度计算它们的相似度,其中L是这对轨迹的长度和。在实践中,我们观察到它至少比精确的蛮力计算快50倍。
3)准确:NEUTRAJ在实践中获得卓越的逼近性能。在两个真实轨迹数据集上,对Fr echet、Hausdorff、DTW和ERP的前10个相似轨迹搜索任务,NEUTRAJ的命中率在80%以上,平均误差距离在50米以下。与目前最先进的轨迹相似度逼近方法[12]相比,该方法的命中率提高了2倍以上。
4)弹性:NEUTRAJ在不丢失空间信息的情况下嵌入轨迹,使其具有弹性,可以通过其他索引和修剪策略进行扩展。在不需要所有对相似性的任务中,减少计算空间。
NEUTRAJ的核心是一个深度度量学习框架,它使用循环神经网络(rnn)生成轨迹嵌入。我们从数据库中取样种子轨迹库,并计算它们的配对相似性。以计算出的种子相似度为指导,我们设计了一种两两损失来优化网络以拟合种子相似度。NEUTRAJ的特点是两个新颖的模块,鼓励网络准确地逼近相似函数
(1)空间注意记忆。普通rnn及其现有变体(GRU、LSTM)只能对一个序列进行建模,而不考虑序列间的相关性。我们设计的SAM单元利用注意力机制记忆先前处理过的轨迹信息,并捕捉训练轨迹之间的相关性,以产生更好的轨迹嵌入。(2)距离加权排序损失。利用种子轨迹的一个困难是效率和有效性之间的两难。一方面,充分训练网络会更好地遍历所有的轨迹对。另一方面,所有轨迹对的完整枚举会导致昂贵的计算时间。为了解决这一难题,我们提出了一种距离加权抽样策略,以聚焦于更有区别的训练对。与加权采样策略一样,距离加权排序损失是一种从种子中学习网络参数以适应引导的排序损失。利用这两个模块,NEUTRAJ可以在训练数据较小的情况下获得较高的精度和较快的收敛速度。
贡献:
1)提出了一种基于神经度量学习的轨迹相似度加速计算方法。据我们所知,NEUTRAJ是第一种支持加速一般轨迹相似度量的方法,这使得它广泛适用于许多应用。2)提出了一种空间注意记忆单元,用于基于注意网络和外部记忆张量来模拟空间闭合轨迹之间的相关性。3)我们设计了一个加权采样和学习模块,充分释放种子轨迹的力量。与现有架构相比,我们的学习模块具有更快的收敛速度和更高的精度。4)我们在两个真实的轨迹数据集和四个流行的轨迹相似度测度上进行了广泛的实验。结果表明,所提出的模型在准确性和效率方面始终优于最先进的基线。
问题定义:
我们考虑一个轨迹数据库T和一个轨迹相似函数f(·,·)。每个轨迹T∈T是记录运动物体轨迹的点序列。函数f(Ti,Tj)度量Ti和Tj之间的相似度。这里,f(·,·)可以是DTW相似度、Hausdorff距离、Fr´echet距离或任何其他轨迹相似度度量。我们的问题是在相似函数f(·,·)下计算从T开始的一对特殊轨迹的相似度。然而,对于大多数流行的相似度量,计算一对轨迹之间的相似度会产生二次时间复杂度。研究的问题是:如何学习一个近似相似函数g(·,·),使计算g(Ti,Tj)花费O(n)时间,同时最小化差值|f(Ti, Tj) g(Ti,Tj) |。
架构
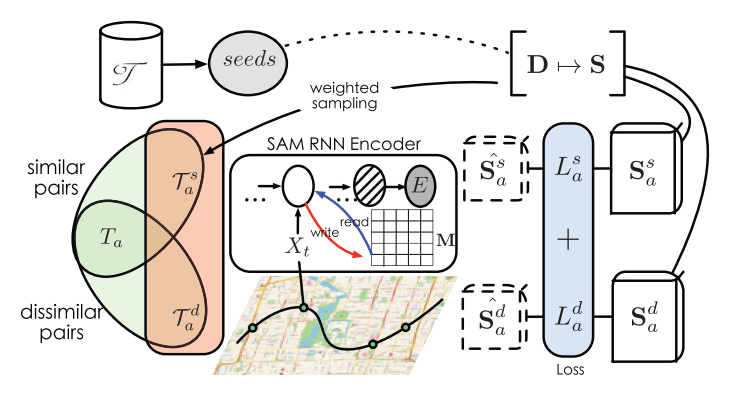
它随机地从T处采样N条轨迹作为种子库。为种子库,计算对称的N ×N距离矩阵D,然后将原始的距离矩阵转换为归一化的相似度矩阵S。利用矩阵S作为指导,NEUTRAJ进一步学习神经网络,该神经网络将任意长度的轨迹映射到低维空间,捕捉它们的相似度。更正式地说,对于任意两个输入轨迹Ti和Tj (i, j[1,…,N]), NEUTRAJ将它们分别投影到二维向量Ei和Ej。学习到的映射应该是保持相似的,即f(Ti,Tj) g(Ti,Tj)其中g(·,·)是Ei和Ej在嵌入空间中的相似度。它由空间注意记忆(SAM)增强RNN编码器和种子引导度量学习方法两大部分组成。
1.SAM Augmented RNN Encoder. NEUTRAJ利用循环神经网络(RNN)对轨迹进行建模,并以RNN的最后一个隐藏状态作为嵌入向量。然而,如前所述,普通rnn及其变体(GRU, LSTM)分别获取每个序列的信息。在轨迹相似度计算中,轨迹之间的相关性至关重要。重要的是利用之前看到的空间闭合轨迹的信息来指导度量学习过程。因此,我们在NEUTRAJ中设计了一个空间注意记忆模块。它使用空间记忆张量来存储先前处理过的轨迹的空间信息。记忆张量基于软注意机制支撑整个空间的读写操作,这样之前看到的轨迹信息就可以按需进行编码和检索。
2. Seed-Guided Neural Metric Learning
NEUTRAJ构建了一个种子引导的度量学习体系结构来消耗一对轨迹,并学习网络来逼近相似矩阵s。现有的度量学习方法采用随机抽样的方法来产生训练对,这意味着所有轨迹的权重都是均等的。但是这个假设并不适用于轨迹度量学习,因为它忽略了轨迹之间的空间接近性。特别地,我们提出了距离加权抽样方法和排序损失目标来解决这一问题。















 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









