







转载:http://blog.csdn.net/jubincn/article/details/6623371
什么是GPU
GPU(GraphicsProcessing Unit)是图形处理器的简称,这个概念是由NVIDIA公司在发布GeForce256绘图处理芯片时首先提出。
GPU使显卡减少了对CPU的依赖,并分担了部分原本是由CPU所担当的工作,尤其是在进行3D图形处理时,功效更加明显。GPU所采用的核心技术有硬件座标转换与光源、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等。
GPU简史
图形芯片最初用作固定功能图形管线。随着时间的推移,这些图形芯片的可编程性日益增加,在此基础之上NVIDIA?(英伟达?)推出了第一款GPU(图形处理器)。1999-2000年间,计算机科学家,与诸如医疗成像和电磁等领域的研究人员,开始使用GPU(图形处理器)来运行通用计算应用程序。他们发现GPU(图形处理器)具备的卓越浮点性能可为众多科学应用程序带来显著的性能提升。这一发现掀起了被称作 GPGPU(GPU(图形处理器)通用计算)的浪潮。
此处需要解决的问题为GPGPU要求使用图形编程语言来对GPU(图形处理器)进行编程,如OpenGL和Cg等。开发人员需要使其科学应用程序看起来像图形应用程序,并将其关联到需要绘制三角形和多边形的问题。这一方法限制了GPU(图形处理器)的卓越性能在科学领域的充分发挥。
NVIDIA®(英伟达™)认识到了让更多科学群体使用这一卓越性能的强大优势,决定投资来修改GPU(图形处理器),使其能够完全可编程以支持科学应用程序,同时还添加了对于诸如C、C++和Fortran等高级语言的支持。此举最终推动诞生了面向GPU(图形处理器)的 CUDA架构。
GPU计算的特点
- GPU/CPU架构比较
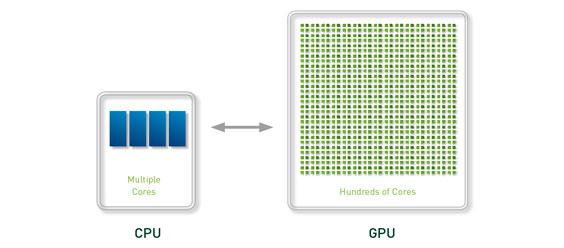
GPU在处理能力和存储器带宽上相对于CPU有明显优势,在成本和功耗上也不需要付出太大代价。由于图形渲染的高度并行性,使得GPU可以通过增加并行处理单元和存储器控制单元的方式提高处理能力和存储器带宽。GPU设计者将更多的晶体管用作执行单元,而不是像CPU那样用作复杂的控制单元和缓存并以此来提高少量执行单元的执行效率。下图对CPU与GPU中的逻辑架构进行了对比。
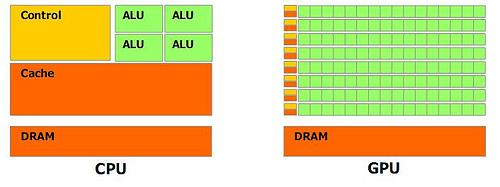
-
强大的浮点计算能力
CPU的整数计算、分支、逻辑判断和浮点运算分别由不同的运算单元执行,此外还有一个浮点加速器。因此,CPU面对不同类型的计算任务会有不同的性能表现。而GPU是由同一个运算单元执行整数和浮点计算,因此,GPU的整型计算能力与其浮点能力相似。
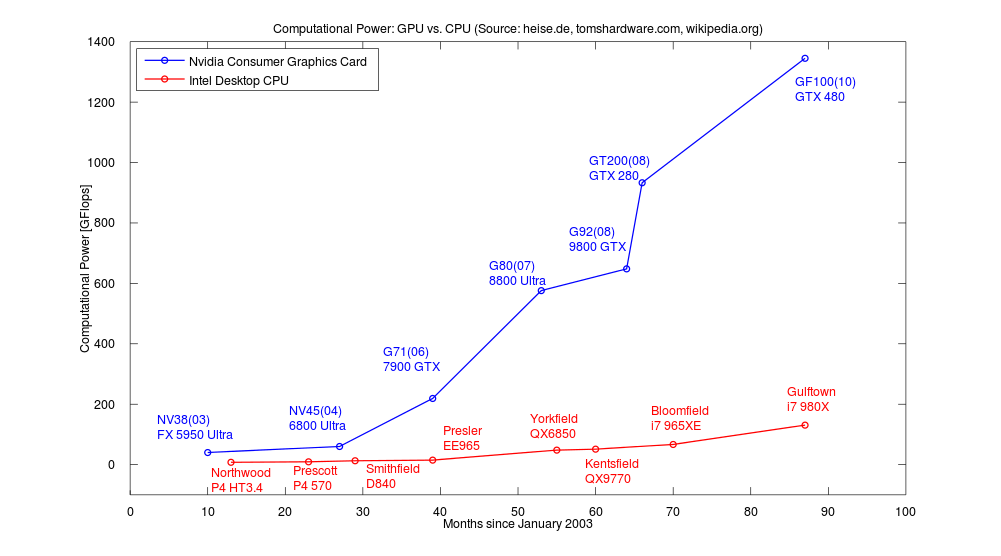
-
更高的内存带宽(MemoryBandwidth)
GPU运算相对于CPU还有一项巨大的优势,那就是其内存子系统,也就是GPU上的显存[1]。当前桌面级顶级产品3通道DDR3-1333的峰值是32GB/S,实测中由于诸多因素带宽在20GB/S上下浮动。AMDHD 4870512MB使用了带宽超高的GDDR5显存,内存总线数据传输率为3.6T/s或者说107GB/s的总线带宽。存储器的超高带宽让巨大的浮点运算能力得以稳定吞吐,也为数据密集型任务的高效运行提供了保障。
还有,从GTX200和HD4870系列GPU开始,AMD和NVIDIA两大厂商都开始提供对双精度运算的支持,这正是不少应用领域的科学计算都需要的。NVIDIA公司最新的Fermi架构更是将全局ECC(ErrorChecking and Correcting)、可读写缓存、分支预测等技术引入到GPU的设计中,明确了将GPU作为通用计算核心的方向。
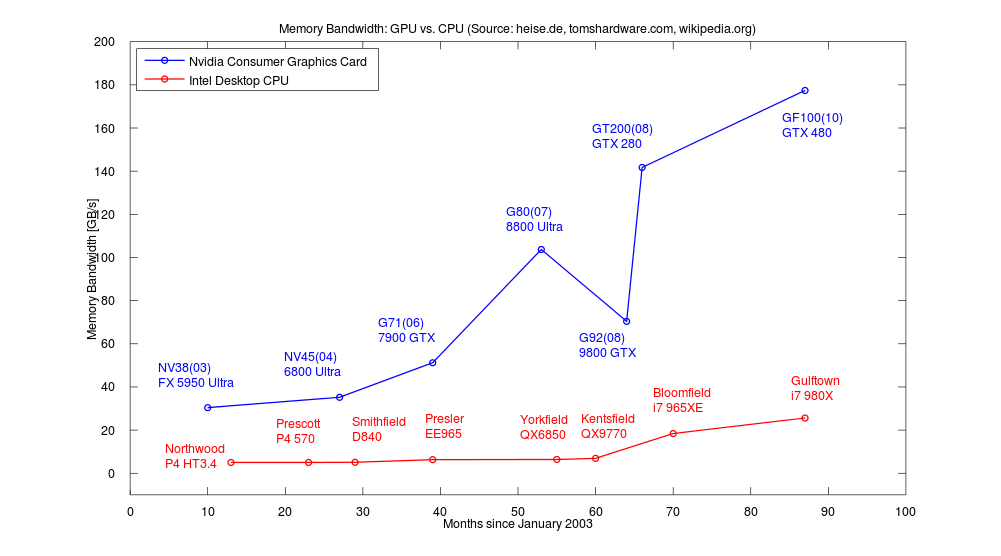
-
延迟与带宽
GPU:高显存带宽和很强的处理能力提供了很大的数据吞吐量,缓存不检查数据一致性,直接访问显存延时可达数百乃至上千时钟周期。
CPU:通过大的缓存保证线程访问内存的低延迟,但内存带宽小,执行单元太少,数据吞吐量小,需要硬件机制保证缓存命中率和数据一致性。
适于GPU计算的场景
尽管GPU计算已经开始崭露头角,但GPU并不能完全替代X86解决方案。很多操作系统、软件以及部分代码现在还不能运行在GPU上,所谓的GPU+CPU异构超级计算机也并不是完全基于GPU进行计算。一般而言适合GPU运算的应用有如下特征:
-
运算密集。
-
高度并行。
-
控制简单。
-
分多个阶段执行。
GPU计算的优势是大量内核的并行计算,瓶颈往往是I/O带宽,因此适用于计算密集型的计算任务。
可编程的图形处理器
传统GPU有一个特征就是只实现固定功能的渲染流水线,
而不具备可编程能力。那些3DAPI(例如Direct3D 和OpenGL)与图形硬件交互时都是作为一个状态机来实现的。用户通过3DAPI 提供的函数设置好相应的状态,比如变换矩阵、
材质参数、光源参数、纹理混合模式等,然后传入顶点流。图形硬件则利用内置的固定渲染流水线和渲染算法对这些顶点进行几何变换、光照计算、光栅化、纹
理混合、雾化操作、最终将处理结果写入帧缓冲区。这种渲染体系限制用户只能使用图形硬件中固化的各种渲染算法。
这虽然可以满足那些对渲染质量要求不高
的应用,但难以实现那些需要更高的灵活性和客户定义的实时图形应用。用户已经无法满足于基于顶点的近似和简单的多纹理混合,
它们需要硬件加速的角色动画支持,需要使用定制的光照模型,需要非真实渲染(卡通渲染、素描渲染)。对于这些灵活需求,如果在GPU硬件中为其设计单独的专用电路显然是不现实的。
因此,硬件可编程性成了唯一可行之路。
为了解决这一难题,现代GPU的3D渲染流程中加入了两个可编程处理器,
顶点处理器(VertexEngine,VE)和像素处理器(PixelEngine,PE)。它们都由算术逻辑单元和相应的寄存器组成。
这两个可编程引擎分别可以取代相应的固定流水线。顶点处理器和像素处理器都没有内存的概念,所有的运算都在寄存器之上进行。
除了顶点处理器和像素处理器之外,
还有两个着色器的概念被引入可编程图
形处理器之中。顶点着色器(VertexShader,VS)就是运行于VE之上的程序,它的工作是进行几何变换和光照计算等操作。而运行于PE之上的像素着色器(PixelShader,PS)则主要进行纹理混合等操作。
可编程处理器和着色器为GPU提供了更加强大和灵活的3D渲染能力,也给
GPGPU的诞生提供了条件,在3D引擎发的展史上具有十分重要的意义。图形处理器的基本体系结构如图2-4所示。
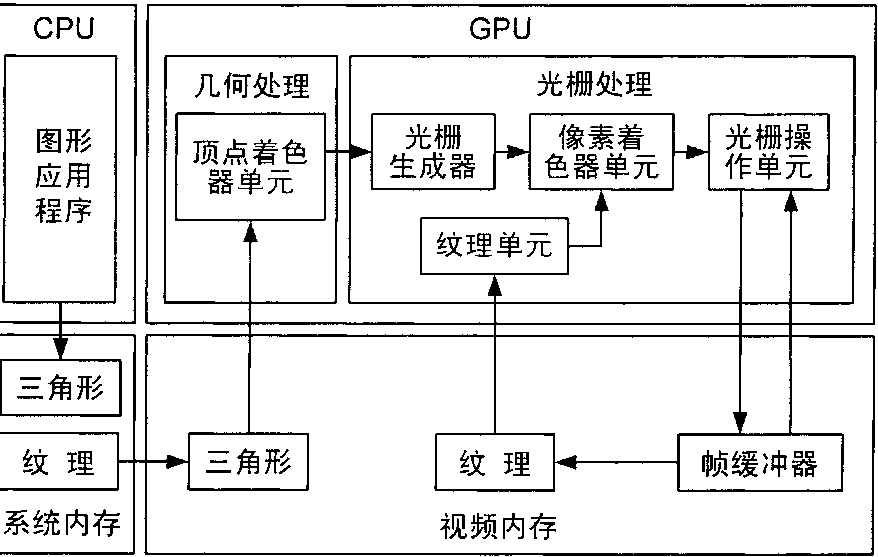
图形处理器体系结构流程图
GPU
GPGPU(GeneralPurpose computing onGPU)是通用图形处理器计算的简称,是指使用GPU来进行3D图形以外的计算,常用于数据密集的科学与工程计算中。
GPU计算的模式是GPU+CPU,即在异构协同处理计算模型中将CPU与GPU结合起来加以利用。应用程序的串行部分在CPU上运行,而计算任务繁重的部分则由GPU来加速。这些通用计算常常与图形处理没有任何关系。由于现代图形处理器强大的并行处理能力和可编程流水线,令流处理器可以处理非图形数据。特别在面对单指令流多数据流(SIMD),且数据处理的运算量远大于数据调度和传输的需要时,通用图形处理器在性能上大大超越了传统的中央处理器应用程序。
传统GPU通用计算的使用
最早的GPGPU开发直接使用图形学API编程。这种开发方式要求程序员将数据打包成纹理,将计算任务映射为对纹理的渲染过程,用汇编或者高级着色语言(如GLSL,Cg,HLSL)编写shader程序,然后通过图形学API(Direct3D、OpenGL)执行。2003年斯坦福大学的IanBuck等人对ANSIC进行扩展,开发了基于NVIDIACg的Brook源到源编译器。Brook可以将类似C的brookC语言通过brcc编译器编译为Cg代码,隐藏了利用图形学API实现的细节,大大简化了开发过程。但早期的Brook编译效率很低,并且只能使用像素着色器(PixelShader)进行运算。受GPU架构限制,Brook也缺乏有效的数据通信机制。AMD在其GPGPU通用计算产品Stream中采用Brook的改进版本Brook+作为高级开发语言。Brook+的编译器工作方式与Brook不同,提高了效率。
目前的GPU开发环境
CG(C for Graphics)是为GPU编程设计的高级绘制语言,由NVIDIA和微软联合开发,微软版本叫HLSL,CG是NVIDIA版本。Cg极力保留C语言的大部分语义,并让开发者从硬件细节中解脱出来,Cg同时也有一个高级语言的其他好处,如代码的易重用性,可读性得到提高,编译器代码优
CUDA(ComputeUnified DeviceArchitecture,统一计算架构)是由NVIDIA所推出的一种集成技术,是该公司对于GPGPU的正式名称。通过这个技术,用户可利用NVIDIA的GeForce8以后的GPU和较新的QuadroGPU进行计算。亦是首次可以利用GPU作为C-编译器的开发环境。NVIDIA营销的时候,往往将编译器与架构混合推广,造成混乱。实际上,CUDA架构可以兼容OpenCL或者自家的C-编译器。无论是CUDAC-语言或是OpenCL,指令最终都会被驱动程序转换成PTX代码,交由显示核心计算。
ATIStream是AMD针对旗下图形处理器(GPU)所推出的通用并行计算技术。利用这种技术可以充分发挥AMDGPU的并行运算能力,用于对软件进行加速或进行大型的科学运算,同时用以对抗竞争对手的nVIDIACUDA技术。与CUDA技术是基于自身的私有标准不同,ATIStream技术基于开放性的OpenCL标准。
OpenCL(Open Computing Language,开放计算语言)是一个为异构平台编写程序的框架,此异构平台可)由CPU,GPU或其他类型的处理器组成。OpenCL由一门用于编写kernels(在OpenCL设备上运行的函数)的语言(基于C99)和一组用于定义并控制平台的API组成。OpenCL提供了基于任务分区和数据分区的并行计算机制。
OpenCL类似于另外两个开放的工业标准OpenGL和OpenAL,这两个标准分别用于三维图形和计算机音频方面。OpenCL扩展了GPU用于图形生成之外的能力。OpenCL由非盈利性技术组织KhronosGroup掌管。
下面是对几种GPU开发环境的简单评价:
CG:优秀的图形学开发环境,但不适于GPU通用计算开发
ATIStream:硬件上已经有了基础,但只有低层次汇编才能使用所有的硬件资源。高层次的brook是基于上一代GPU的,缺乏良好的编程模型。
OpenCL:开放标准,抽象层次较低,较多对硬件的直接操作,代码需要根据不同硬件优化。
CUDA:仅能用于NVIDIA的产品,发展相对成熟,效率高,拥有丰富的文档资源。















 2611
2611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









