









1. 卷积神经网络(CNN)中卷积层与池化层如何进行BP残差传递与参数更新?
答:(1) Average Pooling的BP好算,直接求导可得,就是1/n.
(2) Max Pooling比较有意思,forward的时候需要记录每个窗口内部最大元素的位置,然后BP的时候,对于窗口内最大元素的gradient是1,否则是0。原理和ReLu是一样的。
2. SVM为什么要用核函数?
答:(1)kernel 和 SVM 完全是两个正交的概念。早在SVM提出以前,reproducing kernel Hilbert space(RKHS)的应用就比较广泛了。
(2)kernel有什么作用?kernel不仅可以建立点对点的映射(如SVM那样),还可以建立原空间上一个分布对点的映射,有兴趣的读者请谷歌 kernel embedding of distributions。 在这一个映射下,人们会关心这么一个问题,给两组数据,我如何知道他们是不是从同一个分布中来的呢?在kernel map下,两组数据被map成了kernel space的两个点,我们可以看看在那个空间里他们距离是远还是近,如果很近就很可能是同一个点加上一点sample variance,以此来判断两组数据是不是同一个分布(two sample test)。
(3)简单的讲,核函数的作用就是隐含着一个从低维空间到高维空间(甚至是无穷维的)的映射,而这个映射可以把低维空间中线性不可分的两类点变成线性可分的。但是,本质上,核函数和映射没有关系。核函数只是用来计算映射到高维空间之后的内积的一种简便方法。
3. 机器学习中常用的核函数有哪些?
答:在机器学习中常用的核函数,一般有这么几类,也就是LibSVM中自带的这几类:
1) 线性:
2) 多项式:
3) Radial basis function:
4) Sigmoid:
4. 介绍一下LR。
答:(1)首先,需要明确一点:虽然 逻辑回归 姓 回归,不过其实它的真实身份是 二分类器。介绍完了姓,我们来介绍一下它的名字,逻辑斯蒂。这个名字来源于逻辑斯蒂分布。
(2)logistic function or sigmoid function:
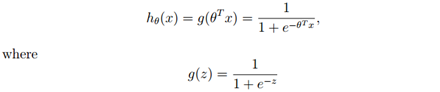

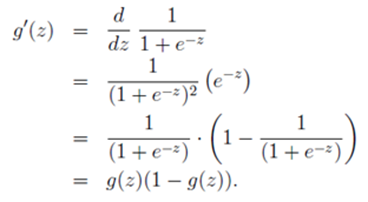
(3)LR如何求解θ?
构建似然函数:
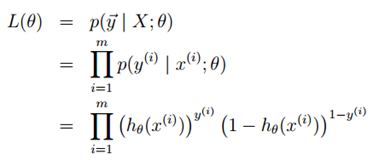
对似然函数取对数:
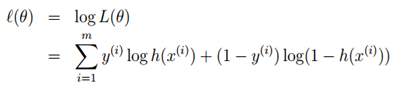
用梯度上升法求最大似然估计:
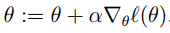
以一个样本为例,使用梯度上升法:

θ的更新公式:

5. LR中存在很多稀疏的系数,你怎么去控制?
答:当模型的参数过多时,很容易遇到过拟合的问题。而正则化是结构风险最小化的一种实现方式,通过在经验风险上加一个正则化项,来惩罚过大的参数来防止过拟合。
正则化是符合奥卡姆剃刀(Occam’s razor)原理的:在所有可能选择的模型中,能够很好地解释已知数据并且十分简单的才是最好的模型。
我们来看一下underfitting,fitting跟overfitting的情况:

显然,最右这张图overfitting了,原因可能是能影响结果的参数太多了。典型的做法在优化目标中加入正则项,通过惩罚过大的参数来防止过拟合。
L1范数:是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。那么,参数稀疏 有什么好处呢?
一个关键原因在于它能实现 特征的自动选择。一般来说,大部分特征 xi和输出 yi 之间并没有多大关系。在最小化目标函数的时候考虑到这些额外的特征 xi,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的信息反而会干扰了对正确 yi 的预测。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些没有信息的特征,也就是把这些特征对应的权重置为0。
L2范数:它有两个美称,在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减”(weight decay)。
它的强大之处就是它能 解决过拟合 问题。我们让 L2 范数的规则项 ||w||2 最小,可以使得 w 的每个元素都很小,都接近于0,但与 L1 范数不同,它不会让它等于0,而是接近于0,这里还是有很大区别的。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。咦,你为啥说越小的参数表示的模型越简单呢? 其实我也不知道,我也是猜,可能是因为参数小,对结果的影响就小了吧。
为了更直观看出两者的区别,我再放一张图:

L1norm本质上是假设参数先验是服从Laplace分布的,而L2-norm是假设参数先验为Gaussian分布,我们在网上看到的通常用图像来解答这个问题的原理就在这。
一句话总结就是:L1 会趋向于产生少量的特征,而其他的特征都是0,而 L2 会选择更多的特征,这些特征都会接近于0。
6. 说说梯度下降法。
答:梯度下降算法(Gradient Descent Optimization)是神经网络模型训练最常用的优化算法。对于深度学习模型,基本都是采用梯度下降算法来进行优化训练的。梯度下降算法背后的原理:目标函数关于参数的梯度将是损失函数(loss function)上升最快的方向。而我们要最小化loss,只需要将参数沿着梯度相反的方向前进一个步长,就可以实现目标函数(loss function)的下降。
批量梯度下降算法:其损失函数是在整个训练集上计算的,如果数据集比较大,可能会面临内存不足问题,而且其收敛速度一般比较慢。
随机梯度下降算法:是另外一个极端, 损失函数是针对训练集中的一个训练样本计算的,又称为在线学习,即得到了一个样本,就可以执行一次参数更新。所以其收敛速度会快一些,但是有可能出现目标函数值震荡现象,因为高频率的参数更新导致了高方差。
小批量梯度下降算法:是折中方案,选取训练集中一个小批量样本(一般是2的倍数,如32,64,128等)计算,这样可以保证训练过程更稳定,而且采用批量训练方法也可以利用矩阵计算的优势。这是目前最常用的梯度下降算法。
















 2516
2516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











