









本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
目录
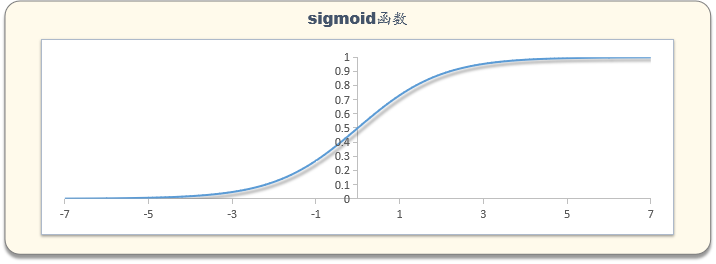
在学习逻辑回归模型时总是疑问sigmoid函数怎么来的,怎么一下子就把WX转换成了概率。在学习评分卡时,又很奇怪,怎么把逻辑回归和WOE,IV(证据权重、信息量)联系在一起,总感觉和教材中的不一样,但查找资料,却没有找到一个很合理的说法。
随着知识的沉淀,后来慢慢地就明白理解其中SIGMOID函数的意思了,本文讲解,逻辑回归模型sigmoid函数由来的思路与推导。
声明:由于没有找到具体的可靠文献,本文是笔者个人的理解,仅供参考,转载或参考本文,请说明来源于《老饼讲解-机器学习》。
由于推导是基于香农信息量,香农信息量的简单介绍请参见《信息量与信息熵》
一、信息获得量
从信息的角度来看待类别预测问题,我们先考察"知道样本属于类别1"这件事获得的信息量.
记样本属于类别1的概率为p,则"知道样本属于类别1"获得的信息量为:
二、信息获得量的初始值
在我们不知道任何变量的信息,唯一知道的信息只有历史样本中类别1出现次数的占比时,
那么类别1出现的占比就是"样本属于类别1的概率",记为p0,此时则有
也即是说,在不知道任何变量信息时,我们从"知道样本属于类别1"这件事获得的信息量为
三、条件下的信息获得量
如果知道了x1的值,那么,我们已知的信息就多了一点,从"知道样本属于类别1"这件事获得的信息量就少了一点。
假设知道获得的信息为
,那么就有
同理的,每知道多一个xi,都会减少从“知道样本属于类别1"这件事中获得的信息量
如果知道,则有
类似地,"知道样本属于类别0"的信息获得量为:
😯 说明:
和
中的
不是同一个东西哦,这里为方便,用了同一个符号
需要注意,信息量能直接相加减的前提是各变量独立哦。
四、信息量差模型
由于信息量只能是正数,每项
都必须是正数,如此一来,就需要对
详细如下:
为方便区分,我们先把
计算“知道样本属于类别1”和“知道样本属于类别0”获得的信息量之差,由
得:
即可得到模型,
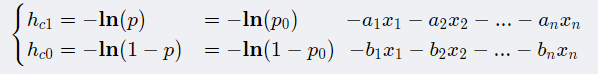
✍️这里,我们分析下模型中各项的意义:
1. -b代表什么变量都不知道的情况下,“知道样本属1类”和“知道样本属0类”所获得的信息量之差。
2. 就是 "知道x_i的值"这件事发生后 , 带给 “知道样本属1类”信息下降量 比 带给 “知道样本属0类”的信息下降量 会多多少。
3. ,则说明
带给 “知道样本属1类”的信息下降量 更多些,也就是 "样本属1类”这件事会更趋明确化,越明确的事件,概率就越小,也就p会更加大。
五、最终的Sigmoid格式模型
将上述得到的模型进行化简,就有:
也就得到模型
其中,
这就是逻辑回归中sigmoid函数的来源。
写后语
整个文章写完花了一天,
中间被BUG卡住,还骑电车逛了几个村
写完情不自禁算一下这文章的直接成本是多少:
1.奶茶2杯 :15+10 = 25元
2.奥尔良大鸡腿一个 :10元
3.1906硬1.5包 :18*1.5 = 27元
4.麻辣烫+可乐 :18+2 =20元
5.电车充电 :2元
6.房租: : 70元
-----------------------------------------------
共计:154元
相关文章















 2355
2355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









