







 本文详细介绍了回归模型在无法建立明确因果关系时的应用,包括一元和多元线性回归、多项式回归、非线性回归以及逐步回归。通过案例分析了如何使用MATLAB进行模型建立、参数估计、残差分析和预测。强调了模型的适用条件、假设检验以及在实际问题中的应用,如建材销售、酶促反应和软件开发人员薪资等。
本文详细介绍了回归模型在无法建立明确因果关系时的应用,包括一元和多元线性回归、多项式回归、非线性回归以及逐步回归。通过案例分析了如何使用MATLAB进行模型建立、参数估计、残差分析和预测。强调了模型的适用条件、假设检验以及在实际问题中的应用,如建材销售、酶促反应和软件开发人员薪资等。
码字总结不易,老铁们来个三连:点赞、关注、评论
作者:[左手の明天]
原创不易,转载请联系作者并注明出处
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
由于客观事物内部规律的复杂及人们认识程度的限制,无法分析实际对象内在的因果关系,建立合乎机理规律的数学模型。通过对数据的统计分析,找出与数据拟合最好的模型。
回归模型是用统计分析方法建立的最常用的一类模型
1、适用的范围:无法分析实际对象的因果关系,建立合乎确定的机理的数学模型,只可能根据数据去建立模型,再根据数据去检验模型。
2、具体的适用对象:在数学建模中必须用到的统计回归模型的知识
3、解决步骤:根据已知数据,从常识和经验来判断和分析,辅以作图,决定取那几个回归变量,以及他们的形式。
目录
一元线性回归模型
一元线性回归模型的形式

1、估计参数a,b,σ^2;
2、检验模型正确与否;(即b→0)
3、预测或控制;
matlab实现
使用命令regress实现一元线性回归模型的计算
b = regress (Y, X)
或
[b, bint, r, rint, stats] = regress(Y, X, alpha) 残差及其置信区间可以用rcoplot(r,rint)画图
例如:为了研究钢材消费量与国民收入之间的关系,在统计年鉴上查得一组历史数据。
| 年 份 | 1964 | 1965 | 1966 | …… | 1978 | 1979 | 1980 |
| 消费(吨) | 698 | 872 | 988 | …… | 1446 | 2736 | 2825 |
| 收入(亿) | 1097 | 1284 | 1502 | …… | 2948 | 3155 | 3372 |
试分析预测若1981年到1985年我国国民收入以4.5%的速度递增,钢材消费量将达到什么样的水平?
x=[1097 1284 1502 1394 1303 1555 1917 2051 2111 2286 2311 2003 2435 2625 2948 3155 3372];
y=[698 872 988 807 738 1025 1316 1539 1561 1765 1762 1960 1902 2013 2446 2736 2825];
plot(x,y,'*')
x=[1097 1284 1502 1394 1303 1555 1917 2051 2111
2286 2311 2003 2435 2625 2948 3155 3372];
y=[698 872 988 807 738 1025 1316 1539 1561
1765 1762 1960 1902 2013 2446 2736 2825];
X=[ones(size(x')),x'],pause
[c,cint,r,rint,stats]=regress(y',X,0.05),pause
c = -460.5282 (参数a) 0.9840 (参数b)
cint = -691.8478 -229.2085 ( a的置信区间 )
0.8779 1.0900 ( b的置信区间 )
r = [ 79.1248 69.1244 -29.3788 -104.1112 -83.5709 -44.5286
-109.7219 -18.5724 -55.6100 -23.8029 -51.4019 449.6576
-33.4128 -109.3651 5.8160 92.1364 -32.3827]’(残差向量)
rint=(略)(参见残差分析图)
stats = 0.9631 391.2713 0.0000rcoplot(r,rint)
预测:
x1(1)=3372;
for i=1:5
x1(i+1)=1.045*x1(i);
y1(i+1)=-460.5282+0.9840*x1(i+1);
end
x1 = 3372.0 3523.7 3682.3 3848.0 4021.2 4202.1
y1 = 3006.8 3162.9 3325.9 3496.3 3674.4多元线性回归模型
多元线性回归模型形式
一般形式

解析形式

矩阵形式

多元线性回归模型的假设
- 解释变量 Xi 是确定性变量,不是随机变量;解释变量之间互不相关,即无多重共线性。
- 随机误差项具有0均值和同方差
- 随机误差项不存在序列相关关系
- 随机误差项与解释变量之间不相关
- 随机误差项服从0均值、同方差的正态分布
matlab实现
1、确定回归系数的点估计值

2、求回归系数的点估计和区间估计、并检验回归模型

3、画出残差及其置信区间
rcoplot(r, rint)例如:某建材公司对某年20个地区的建材销售量Y(千方)、推销开支、实际帐目数、同类商品竞争数和地区销售潜力分别进行了统计。试分析推销开支、实际帐目数、同类商品竞争数和地区销售潜力对建材销售量的影响作用。试建立回归模型,且分析哪些是主要的影响因素。
设:推销开支——x1 实际帐目数——x2同类商品竞争数——x3地区销售潜力——x4

x1=[5.5 2.5 8 3 3 2.9 8 9 4 6.5 5.5 5 6 5 3.5 8 6 4 7.5 7]';
x2=[31 55 67 50 38 71 30 56 42 73 60 44 50 39 55 70 40 50 62 59]';
x3=[10 8 12 7 8 12 12 5 8 5 11 12 6 10 10 6 11 11 9 9]';
x4=[8 6 9 16 15 17 8 10 4 16 7 12 6 4 4 14 6 8 13 11]';
y=[79.3 200.1 163.1 200.1 146.0 177.7 30.9 291.9 160 339.4 159.6 86.3 237.5 107.2 155 201.4 100.2 135.8 223.3 195]';
X=[ones(size(x1)),x1,x2,x3,x4];
[b,bint,r,rint,stats]=regress(y,X)
Q=r'*r
sigma=Q/18输出结果是:
b = 191.9158 -0.7719 3.1725 -19.6811 -0.4501
β0 β1 β2 β3 β4
bint = 103.1071 280.7245……(系数的置信区间)
r =[ -6.3045 -4.2215 ……8.4422 23.4625 3.3938]
rint=(略)
stats = 0.9034(R2) 35.0509(F) 0.0000(p)
Q = r’*r
σ^2= Q/(n-2) = 537.2092 (近似)
多项式回归模型
一元多项式回归

1、回归
(1)确定多项式系数的命令:[p,S]=polyfit(x,y,m)

(2)一元多项式回归命令:polytool(x,y,m)
2、预测和预测误差估计
(1)Y=polyval(p,x)求polyfit所得的回归多项式在x处 的预测值Y;
(2)[Y,DELTA]=polyconf(p,x,S,alpha)求polyfit所得的回归多项式在x处的预测值Y及预测值的显著性为DELTA
alpha缺省时为0.5

方法一
直接作二次多项式回归:
t=1/30:1/30:14/30;
s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90
85.44 99.08 113.77 129.54 146.48];
[p,S]=polyfit(t,s,2)
得回归模型为 :
![]()
方法二
化为多元线性回归:
t=1/30:1/30:14/30;
s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90
85.44 99.08 113.77 129.54 146.48];
T=[ones(14,1) t' (t.^2)'];
[b,bint,r,rint,stats]=regress(s',T);
b,stats
得回归模型为 :
![]()
预测及作图
Y=polyconf(p,t,S)
plot(t,s,'k+',t,Y,'r')多元二项式回归


例:设某商品的需求量与消费者的平均收入、商品价格的统计数 据如下,建立回归模型,预测平均收入为1000、价格为6时的商品需求量.

方法一
![]()
直接用多元二项式回归:
x1=[1000 600 1200 500 300 400 1300 1100 1300 300];
x2=[5 7 6 6 8 7 5 4 3 9];
y=[100 75 80 70 50 65 90 100 110 60]';
x=[x1' x2'];
rstool(x,y,'purequadratic')
在左边图形下方的方框中输入1000,右边图形下方的方框中输入6。
则画面左边的“Predicted Y”下方的数据变为88.47981,即预测出平均收入为1000、价格为6时的商品需求量为88.4791.
在画面左下方的下拉式菜单中选”all”, 则beta、rmse和residuals都传送到Matlab工作区中.
在Matlab工作区中输入命令: beta, rmse


方法二


结果为:
b =
110.5313
0.1464
-26.5709
-0.0001
1.8475
stats =
0.9702 40.6656 0.0005非线性回归模型

(2)非线性回归命令:nlintool(x,y,’model’, beta0,alpha)
[Y,DELTA]=nlpredci(’model’, x,beta,r,J) 求nlinfit 或nlintool所得的回归函数在x处的预测值Y及预测值的显著性为1-alpha的置信区间Y±DELTA.
逐步回归
逐步回归的命令是:

运行stepwise命令时产生三个图形窗口:Stepwise Plot,Stepwise Table,Stepwise History.
在Stepwise Plot窗口,显示出各项的回归系数及其置信区间.
Stepwise Table 窗口中列出了一个统计表,包括回归系数及其置信区间,以及模型的统计量剩余标准差(RMSE)、相关系数(R-square)、F值、与F对应的概率P.
例:水泥凝固时放出的热量y与水泥中4种化学成分x1、x2、x3、 x4 有关,今测得一组数据如下,试用逐步回归法确定一线性模型.

1、数据输入:
x1=[7 1 11 11 7 11 3 1 2 21 1 11 10]';
x2=[26 29 56 31 52 55 71 31 54 47 40 66 68]';
x3=[6 15 8 8 6 9 17 22 18 4 23 9 8]';
x4=[60 52 20 47 33 22 6 44 22 26 34 12 12]';
y=[78.5 74.3 104.3 87.6 95.9 109.2 102.7 72.5 93.1 115.9 83.8
113.3 109.4]';
x=[x1 x2 x3 x4];
2、逐步回归:
(1)先在初始模型中取全部自变量:
stepwise(x,y) 得图Stepwise Plot 和表Stepwise Table
图Stepwise Plot中四条直线都是虚线,说明模型的显著性不好
从表Stepwise Table中看出变量x3和x4的显著性最差.
(2)在图Stepwise Plot中点击直线3和直线4,移去变量x3和x4
移去变量x3和x4后模型具有显著性.
虽然剩余标准差(RMSE)没有太大的变化,但是统计量F的 值明显增大,因此新的回归模型更好.
常见模型实例
线性回归实例——牙膏的销售量
问题提出
建立牙膏销售量与价格、广告投入之间的模型;预测在不同价格和广告费用下的牙膏销售量。
收集了30个销售周期本公司牙膏销售量、价格、广告费用,及同期其他厂家同类牙膏的平均售价。

基本模型

模型求解

结果分析

销售量预测

模型改进

两模型销售量预测比较

两模型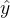 与x1,x2关系的比较
与x1,x2关系的比较

交互作用影响的讨论

完全二次多项式模型

MATLAB中有命令rstool直接求解


从输出 Export 可得

鼠标移动十字线(或下方窗口输入)可改变x1, x2, 左边窗口显示预测值 及预测区间
x1=[-0.0500 0.2500 0.6000 0 0.2500 0.2000 0.1500 0.0500 -0.1500 0.1500 0.0200 0.0100 0.4000 0.4500 0.3500 0.3000 0.5000 0.5000 0.4000 -0.0500 -0.0500 -0.1000 0.2000 0.1000 0.5000 0.6000 -0.0500 0 0.0500 0.5500];
x2=[5.5000 6.7500 7.2500 5.5000 7.0000 6.5000 6.7500 5.2500 5.2500 6.0000 6.5000 6.2500 7.0000 6.9000 6.8000 6.8000 7.1000 7.0000 6.8000 6.5000 6.2500 6.0000 6.5000 7.0000 6.8000 6.8000 6.5000 5.7500 5.8000 6.8000];
y=[7.3800 8.5100 9.5200 7.5000 9.3300 8.2800 8.7500 7.8700 7.1000 8.0000 7.8900 8.1500 9.1000 8.8600 8.9000 8.8700 9.2600 9.0000 8.7500 7.9500 7.6500 7.2700 8.0000 8.5000 8.7500 9.2100 8.2700 7.6700 7.9300 9.2600];
x=[x1',x2'];
rstool(x,y,'quadratic')

在Matlab工作区中输入命令: beta 得
beta =
31.1478
16.7348
-8.3212
-2.4124
1.5219
0.7338
非线性回归实例——酶促反应
问题提出
研究酶促反应(酶催化反应)中嘌呤霉素对反应速度与底物(反应物)浓度之间关系的影响
建立数学模型,反映该酶促反应的速度与底物浓度以及经嘌呤霉素处理与否之间的关系
方案
设计了两个实验 :酶经过嘌呤霉素处理;酶未经嘌呤霉素处理。实验数据见下表:

分析:酶促反应的基本性质
底物浓度较小时,反应速度大致与浓度成正比;
底物浓度很大、渐进饱和时,反应速度趋于固定值。
基本模型:Michaelis-Menten模型

解决方案一:线性化模型

线性化模型结果分析

解决方案二:非线性化模型


x=[0.02 0.02 0.06 0.06 0.11 0.11 0.22 0.22 0.56 0.56 1.10 1.10];
y=[76 47 97 107 123 139 159 152 191 201 207 200];
beta0=[195.8027 0.04841];
[beta,R,J]=nlinfit(x,y,'hx',beta0);
betaci=nlparci(beta,R,J);
beta,betaci
yy=beta(1)*x./(beta(2)+x);
plot(x,y,'o',x,yy,'+'),pause
nlintool(x,y,'hx',beta)
非线性模型结果分析

混合反应模型
在同一模型中考虑嘌呤霉素处理的影响,用未经嘌呤霉素处理的模型附加增量的方法。

混合模型求解


简化的混合模型

一般混合模型与简化混合模型预测比较

模型评注

软件开发人员的薪金
问题提出
建立模型研究薪金与资历、管理责任、教育程度的关系
分析人事策略的合理性,作为新聘用人员薪金的参考
46名软件开发人员的档案资料

资历~ 从事专业工作的年数;
管理~ 1=管理人员,0=非管理人员;
教育~ 1=中学,2=大学,3=更高程度
模型假设
假设: y~ 薪金,x1 ~资历(年) x2 = 1~ 管理人员,0~ 非管理人员

假设: 资历每加一年薪金的增长是常数; 管理、教育、资历之间无交互作用
模型:线性回归

 模型求解
模型求解

Matlab程序: xinjindata.m xinjin.m
xinjindata.m:
序号、工资y、资历x1、管理x2、学历、x3、x4、xxxinjin.m :
M=dlmread('xinjindata.m');
x1=M(:,3);x2=M(:,4);x3=M(:,6);x4=M(:,7);y=M(:,2);
x=[ones(size(x1)) x1 x2 x3 x4 ]
[b,bi,r,ri,s]=regress(y,x)
结果

结果分析:残差分析方法

![]()

残差大概分成3个水平,6种管理—教育组合混在一起,未正确反映



残差全为正,或全为负,管理—教育组合处理不当

模型改进


模型应用


模型评注
- 对定性因素(如管理、教育),可以引入0-1变量处理,0-1变量的个数应比定性因素的水平少1
- 残差分析方法可以发现模型的缺陷,引入交互作用项常常能够改善模型
- 剔除异常数据,有助于得到更好的结果
- 可以直接对6种管理—教育组合引入5个0-1变量
投资额与国民生产总值和物价指数
问题提出
建立投资额模型,研究某地区实际投资额与国民生产总值 ( GNP ) 及物价指数 ( PI ) 的关系
根据对未来GNP及PI的估计,预测未来投资额

模型分析
许多经济数据在时间上有一定的滞后性
以时间为序的数据,称为时间序列
时间序列中同一变量的顺序观测值之间存在自相关
若采用普通回归模型直接处理,将会出现不良后果
需要诊断并消除数据的自相关性,建立新的模型

基本回归模型


结果与分析

自相关性的定性诊断:残差诊断法

自回归性的定量诊断:D-W检验

D-W统计量与D-W检验
 广义差分变换
广义差分变换

投资额新模型的建立


新模型的自相关性检验

模型结果比较

投资额预测
对未来投资额yt 作预测,需先估计出未来的国民生产总值x1t 和物价指数 x2t


文章到这里就介绍了,有没有收获满满,那就快巩固吧,当然看到这里说明你是好学的,毕竟文章这么长,觉得不错的话来个三连~~~~

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











