







1、大模型
随着ChatGPT流行,大模型技术正逐渐成为AI领域的热点。许多行业大佬纷纷投身于这一赛道,展示了大模型的独特魅力和广阔前景。
王慧文,前美团联合创始人,发起“AI英雄帖”。
李志飞,出门问问创始人,打造中国版OpenA。
李沐 和 Alex Smola,前亚马逊员工,师徒俩携手大模型创业。
周伯文,前京东AI部门负责人,强调大模型并非大公司专属。
王小川,前搜狗CEO,认为OpenAI的成功是技术理想主义的胜利。
李岩,快手前AI核心成员,投身于大模型赛道。
贾扬清,阿里巴巴VP,专注构建大模型基础设施,已完成首轮融资。
1.1、不是“大”的模型就叫大模型
关于大模型,部分学者描述它为“大规模预训练模型”(large pretrained language model),同时还有学者提出了“基础模型”(Foundation Models)的新概念。为AI技术的发展和应用提供了新的视角和可能性。
在2021年8月,李飞飞、Percy Liang以及其他一百多位学者共同发布了一篇名为《On the Opportunities and Risks of Foundation Models》的文章,其中引入了“基础模型”(Foundation Models)这一术语。文章中指出,这类基于自监督学习的模型在训练过程中展现出多方面的能力,这些能力不仅为各种下游应用提供了动力,也奠定了理论基础,因此将这类大模型称为“基础模型”。
小模型: 主要是为特定的应用场景设计并训练的,能够完成特定的任务。然而,当应用到其他场景时,这些模型可能无法直接适用,需要进行重新训练。目前大多数模型都属于这一类,其训练方式类似于“手工作坊式”,依赖大量的标注数据。如果应用场景的数据量不足,这些模型的精度往往不会达到理想状态。
大模型: 则在大规模的无标注数据上进行训练,从而学习到广泛的特征和规则。在使用大模型开发应用时,可以通过对大模型进行微调(在具体的下游应用中使用小规模的标注数据进行二次训练)或者不进行任何微调,使其能够适应并完成多种应用场景下的任务,展现出其通用的智能能力。
1.2、大模型赛道早已启动
多语言预训练大模型
- Facebook推出了M2M-100模型,支持100种语言的直接互译,无需依赖英语作为中介语言,这在机器翻译领域是一个重大突破。
- 谷歌公开了多语言模型MT5,该模型基于101种语言训练,使用了750GB的文本数据,拥有高达130亿个参数。在多种多语言自然语言处理任务的基准测试中,MT5表现出色,涵盖了机器翻译、阅读理解等领域。
多模态预训练大模型
- OpenAI开发了包括DALL·E和CLIP在内的多模态模型,这些模型具有120亿参数,特别在图像生成等任务上展现出优异的性能。
多任务预训练大模型
- 在2022年的IO大会上,谷歌介绍了多任务统一模型(MUM)的进展。MUM模型基于大量网页数据进行预训练,能够理解75种语言,并擅长处理复杂的决策问题,通过分析跨语言多模态网页数据来寻找信息。
视觉预训练大模型
- 如ViTransformer等模型展现了视觉通用能力,这在视觉任务中非常关键,尤其是在自动驾驶等视觉处理密集的应用领域,视觉大模型的应用潜力巨大。
1.3、深度学习范式正在发生变革
AI的研发和应用范式可能将经历巨大变革。许多行业领袖投身于大模型赛道,可能是因为他们预见到了深度学习2.0时代的到来。 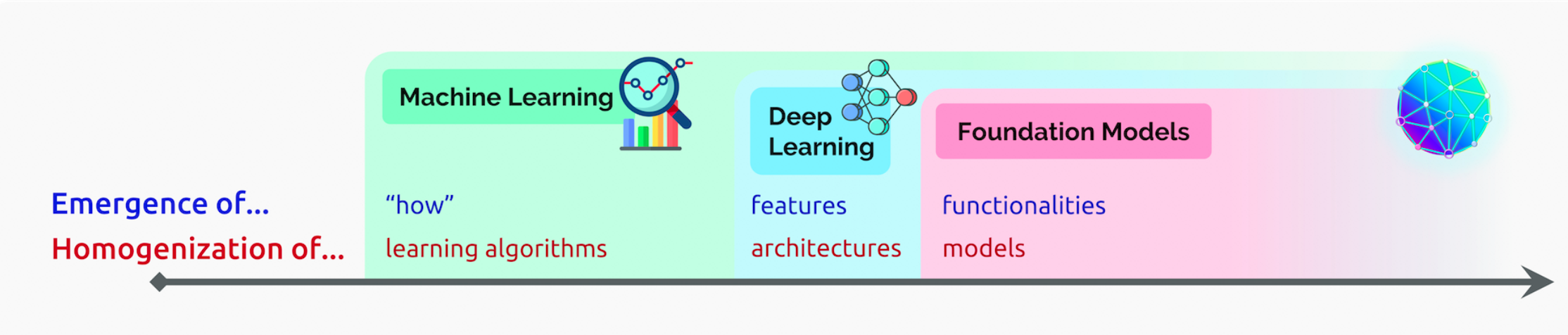
machine learning homogenizes learning algorithms (e.g., logistic regression), deep learning homogenizes model architectures (e.g., Convolutional Neural Networks), and foundation models homogenizes the model itself (e.g., GPT-3)
正如文章中提到的,机器学习中的同质化学习算法(如逻辑回归)、深度学习中的同质化模型结构(如CNN),基础模型则是对模型本身的同质化(例如GPT-3)。
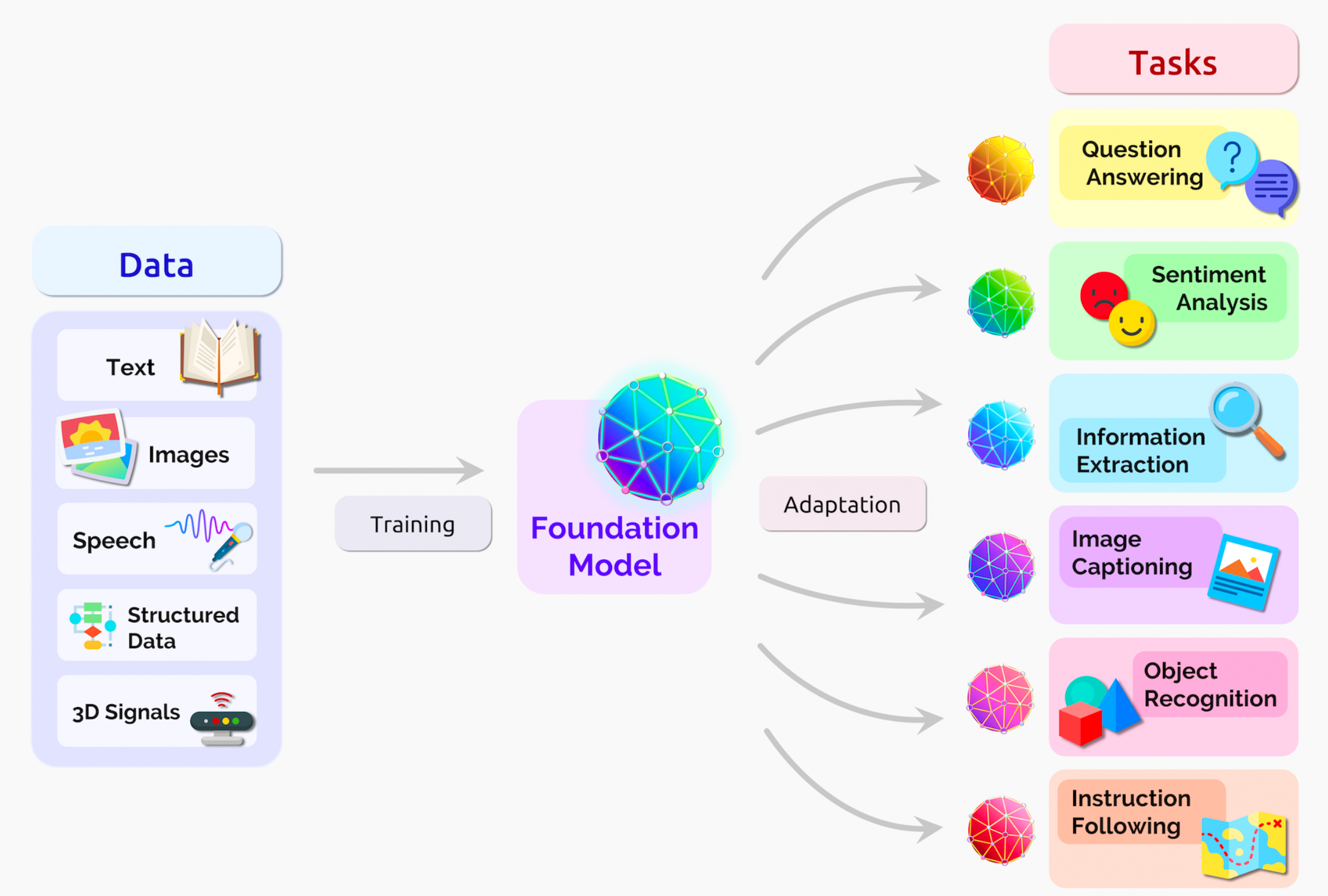
人工智能的发展已经从“大炼模型”逐步迈向了“炼大模型”的阶段。ChatGPT仅是一个开始,其背后的基础模型(Foundation Module)的长远价值更加值得期待。
1.4、大模型是厚积薄发的
大模型不是一蹴而就的,发展的早期阶段被称为预训练模型阶段,其核心技术是迁移学习。当目标应用场景的数据不足时,模型首先在大规模的公开数据集上进行训练,然后迁移到特定场景中,并通过少量的目标场景数据进行微调,以达到所需的性能。这种在公开数据集上训练的深度网络模型,被称为“预训练模型”。使用预训练模型可以显著减少下游任务对标注数据的依赖,有效处理数据标注困难的新场景。
2018年,大规模自监督神经网络的出现标志着一次真正的革命。这类模型的核心在于通过自然语言句子创造预测任务,例如预测下一个词或预测被掩码的词或短语。这使得大量高质量的文本语料成为自动获取的海量标注数据源。通过从自身预测错误中学习超过10亿次,模型逐渐积累了丰富的语言和世界知识,从而在问答、文本分类等更有意义的任务中展现出优异的性能。这正是BERT和GPT-3等大规模预训练语言模型的精髓,也是所谓的“大模型”。
1.5、大模型的革命性意义
突破现有模型结构的精度局限
在2020年1月,OpenAI发布了一篇论文,研究了模型性能与模型规模之间的关系。结论表明,模型的表现与其规模之间遵循幂律关系,即模型规模的指数级增长会带来模型性能的线性提升。
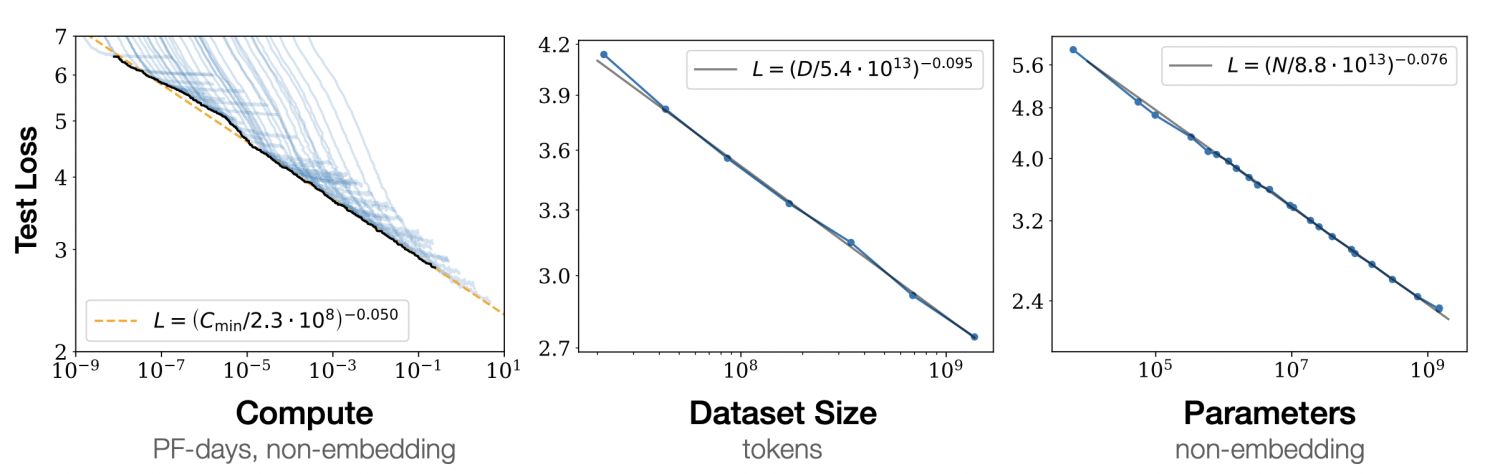
在2022年8月,Google发布了一篇论文,重新审视了模型性能与模型规模之间的关系。研究发现,当模型规模达到一定的阈值后,模型在处理某些问题上的性能会出现快速增长。研究者们将这种现象称为“涌现能力”(Emergent Abilities)。
预训练大模型与场景微调:长尾应用优化
根据斯坦福大学著名NLP学者Chris Manning教授的观点,通过在未标注的海量语料上训练大模型可以:
Produce one large pretrained model that can be very easily adapted, via fine-tuning or prompting, to give strong results on all sorts of natural language understanding and generation tasks.
通过微调或使用提示,大规模预训练模型能够轻松适应各种自然语言理解和生成任务,并能产生出色的结果。
大模型的“大道至简”
基于简单的Transformer结构之所以展现出强大的能力,关键在于其通用性。预测下一个单词这样的任务既简单又通用,几乎所有类型的语言学和世界知识,包括句子结构、词义引申、基本事实等,都能助力这一任务的成功执行。在训练过程中,大模型也学习到了这些信息,使得单一模型在接受少量指令后便能解决多种不同的NLP问题。这或许是“大道至简”理念的最佳体现。
在2018年之前,基于大模型完成多种NLP任务主要依靠微调(fine-tuning),即在少量专门为任务构建的有监督数据上继续训练模型。而后来出现了提示学习(prompting)的方法,这种方式仅需用语言描述任务或给出几个示例,模型便能有效执行之前未经训练的任务。
1.6、大模型真的理解了人类语言吗?
要深入讨论这个问题,我们需要探讨“语义”的定义以及语言理解的本质。在语言学和计算机科学领域,主流的理论认为一个单词、短语或句子的语义(denotational semantics),是指它所代表的客观世界中的对象。与此形成对比的是深度学习NLP所遵循的分布式语义(distributional semantics):单词的语义由其出现的上下文环境决定。
更通俗的说,以“你吃饭了吗”?“我吃过了”为例,“吃饭”的语义是什么呢?
主流理论:“吃饭”(短语)表示的是“端着一碗饭,用筷子扒拉到嘴里吃掉”或者“手里拿着面包总到嘴里吃掉”这些行为过程(客观世界中的对象)。
分布式语义:“吃饭”这个词,从概率统计的角度,它有很大的可能出现在“你____了吗?我吃过了。”这个句子里面,是语言在形式上的一种连接,仅此而已。模型并不知道“往嘴里塞东西吃”这个客观世界里可以听见或看见的过程叫“吃饭”。
Meaning arises from understanding the network of connections between a linguistic form and other things, whether they be objects in the world or other linguistic forms.
意义来源于理解语言形式与其他事物之间的连接&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









