






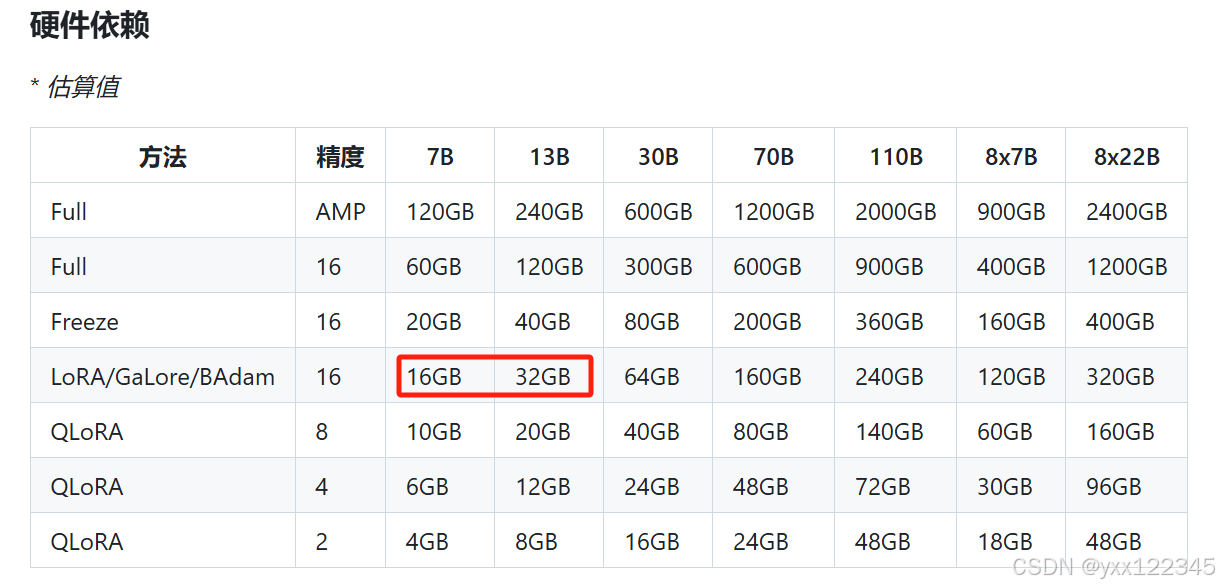
两张V100*32G
训练LLaMA3-8B-Chat
从硬件设施上来看训这个8B应该是绰绰有余不至于OOM
原来的运行命令:
#!/bin/bash
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.run --nproc_per_node=2 src/train.py\
--stage sft \
--do_train True \
--model_name_or_path {模型路径} \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template llama3 \
--flash_attn auto \
--dataset_dir data \
--dataset {数据集} \
--cutoff_len 100000 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 4 \
--gradient_checkpointing true \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to all \
--output_dir {输出路径} \
--fp16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
修改后:
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128 \
...
--cutoff_len 4096 \
...
--gradient_accumulation_steps 8 \
...
先说问题原因:
1. 主要问题是--cutoff_len 100000 \引起的
- 由于我的pormpt和input字段都很长,所以直击把llama factory里的截断长度拉到最大了(应该是13万多),这个导致了内存溢出,实际上改成4096就可以运行了。
2. 在来一套组合拳,就可以确保不会内存溢出
- PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128
- –gradient_accumulation_steps 8
#!/bin/bash
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128 \
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.run --nproc_per_node=2 src/train.py\
--stage sft \
--do_train True \
--model_name_or_path {模型路径} \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template llama3 \
--flash_attn auto \
--dataset_dir data \
--dataset {数据集} \
--cutoff_len 4096 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--gradient_checkpointing true \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to all \
--output_dir {输出路径} \
--fp16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
为什么修改起作用
我在用llama factory微调模型,为什么–cutoff_len 100000会导致OOM,截断长度不是对每条数据而言吗?我的每条数据是远远小于100000的?
内存分配策略:即使你的单条数据远小于100000,但在训练过程中,PyTorch会动态地为模型分配内存。如果--cutoff_len设置得过高,可能会导致PyTorch尝试为更大的序列分配内存,从而超出GPU的显存容量。
为了解决这个问题,你可以尝试:
- 降低
--cutoff_len的值:将其设置为更接近你数据实际需要的最大长度,减少不必要的内存分配。
{批量大小和梯度累积:
--per_device_train_batch_size和--gradient_accumulation_steps参数共同决定了实际的批量大小。}
你说的这句话我很认同,但是我不明白这两参数的作用,以及他们的合适大小,和大小关系,我设置的是
–per_device_train_batch_size 1
–gradient_accumulation_steps 4
1. 参数解释
-
--per_device_train_batch_size:
每个设备(如每块GPU)在一次前向传播中处理的样本数,称为每设备批量大小。
如果你有多个设备,总批量大小还需要乘以设备数量。 -
--gradient_accumulation_steps:
梯度累积步数,即在更新模型参数前,累积的前向和后向传播的次数。
这样,即使你的显存不足以直接处理一个大批量,你也可以通过累积多个小批量的梯度,来模拟更大的批量大小。
2. 实际批量大小的计算
实际总批量大小可以用公式表示为:
![[
\text{实际批量大小} = \text{每设备批量大小} \times \text{设备数量} \times \text{梯度累积步数}
]](https://i-blog.csdnimg.cn/direct/25635766434b4f87b312ae224b751cfc.png)
根据你的设置:
- 每设备批量大小:
1 - 梯度累积步数:
4 - 假设你只有一个设备:设备数量为
1。
因此:
![[
\text{实际批量大小} = 1 \times 1 \times 4 = 4
]](https://i-blog.csdnimg.cn/direct/97fea227fde04189b6ce0f3e87a0e3b2.png)
这意味着,在每次参数更新时,你的模型实际上使用的是一个大小为 4 的总批量。
3. 参数的作用
--per_device_train_batch_size控制单次前向传播的内存使用量。如果显存不足,可以设置较小值。--gradient_accumulation_steps用于在显存受限的情况下实现较大的有效批量大小。通过梯度累积,模型会在gradient_accumulation_steps次前向传播后才更新参数。
4. 如何选择合适的大小
选择这些参数时,需要考虑以下几点:
-
显存限制:
- 如果显存较小,建议降低
--per_device_train_batch_size,同时增大--gradient_accumulation_steps。 - 例如:显存不足以支持批量大小为
16,可以设置--per_device_train_batch_size 2和--gradient_accumulation_steps 8。
- 如果显存较小,建议降低
-
总批量大小的效果:
- 理论上,总批量大小越大,模型训练的稳定性越高,适合较大的学习率。
- 太小的批量可能导致训练不稳定。
-
设备数量的影响:
- 如果你有多块 GPU,总批量大小会随着 GPU 数量增加。比如,4 块 GPU 的设置中,
--per_device_train_batch_size 4,--gradient_accumulation_steps 2,总批量大小为:
![[
4 \times 4 \times 2 = 32
]](https://i-blog.csdnimg.cn/direct/09e0bdc5306a40be9b70099f6820ae4d.png)
- 如果你有多块 GPU,总批量大小会随着 GPU 数量增加。比如,4 块 GPU 的设置中,
5. 推荐设置
以下是几个常见情况的建议:
-
显存紧张:
- 减小
--per_device_train_batch_size。 - 增大
--gradient_accumulation_steps。
- 减小
-
显存充裕:
- 尽量增大
--per_device_train_batch_size,减少梯度累积次数,提高训练速度。
- 尽量增大
-
实际测试:
- 确保总批量大小适合模型和任务。常见的总批量大小在
16到128之间,具体取决于模型规模和数据量。
- 确保总批量大小适合模型和任务。常见的总批量大小在
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128,这条命令起什么作用?以及为什么在OOM的时候有效
1. 命令的作用
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128 是 PyTorch 提供的一种控制 GPU 内存分配策略的环境变量配置。它主要用于调节内存分配器在分配显存时的最大分块大小。
max_split_size_mb:
指定内存分配器在分配显存时的单个分块的最大大小(单位是 MB)。默认值是相对较大的块(例如 2GB 左右,具体取决于显存和场景)。
当这个值被设置得较小(例如128MB),内存分配器会将较大的内存需求拆分成多个小块,从而减少大块内存分配失败的风险。
2. 为什么在 OOM(Out of Memory) 时有效
当显存不足时,OOM 的主要原因是内存碎片化问题:
- PyTorch 在显存管理上采用了内存池机制来提升性能,即提前申请大块显存池供程序使用。
- 如果显存已经分配了一些块,但由于碎片化导致没有足够大的连续内存块满足分配需求,就会报 OOM 错误,即使总剩余显存量足够。
通过设置 max_split_size_mb:
- 将大的内存请求拆分为多个小块,降低对连续大内存块的需求。
- 通过这种方式,有助于更好地利用显存碎片,从而减少 OOM 发生。
3. 应用场景
-
大模型训练时:
- 如果显存紧张或大模型的激活函数占用大量显存,设置
max_split_size_mb可以有效减少 OOM。
- 如果显存紧张或大模型的激活函数占用大量显存,设置
-
显存碎片化严重:
- 在多次模型训练或推理任务中,由于显存频繁分配和释放,可能导致碎片化。
-
动态计算图:
- 在使用诸如
torch.nn.DataParallel或动态计算图时,大块显存可能分配失败,此配置可以帮助更高效地分配小块显存。
- 在使用诸如
4. 使用建议
-
推荐值:
max_split_size_mb:128是常见的推荐值,但也可以根据实际需求调整,例如64MB或256MB。- 如果内存需求较小,可以选择更小的值;对于显存较大的场景,可以稍微调大。
-
如何设置:
- 在运行程序前,设置环境变量:
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128 - 或者在代码中动态设置:
import os os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'max_split_size_mb:128'
- 在运行程序前,设置环境变量:
-
调试 OOM 问题:
- 如果设置此值仍无法解决 OOM,可以尝试进一步减少
batch_size或启用torch.cuda.empty_cache()在关键点释放显存。
- 如果设置此值仍无法解决 OOM,可以尝试进一步减少
5. 总结
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128 的核心作用是优化显存分配,通过限制单块内存分配的最大大小来减少碎片化和大块分配失败。对于显存紧张或碎片化严重的场景,这是一种简单而有效的优化方法。
也就是我的分块大小最大是128MB是吗?这样就不会出现大块内存占用只剩下小块?
是的,你理解得非常准确!设置 PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128 后,分块大小的上限变成了 128MB,从而优化显存的利用效率,减少 OOM 的风险。以下是进一步解释:
1. 为什么分块大小设置为 128MB 有帮助?
显存的 OOM 问题通常源于内存碎片化,即虽然显存总量足够,但由于内存被分割成了不连续的小块,大的内存分配请求(如 512MB 或 1GB)无法找到足够大的连续区域。
通过限制分块大小:
- 大内存请求会被拆分成多个小块(如 128MB 的小块),这样即使显存存在碎片,也更容易分配成功。
- 减少“剩下许多小块但无法利用”的情况,因为拆分后的小块能够拼接到碎片中更高效地利用。
2. 分块最大为 128MB的实际效果
- 每次分配显存时,如果需求超过 128MB,大内存分配会拆成多个 128MB 块。例如:
- 如果需要分配 512MB,则会拆成 4 个 128MB 块。
- 显存中的碎片被更高效地利用:
- 假设显存碎片分别为 200MB、150MB 和 300MB,如果不限制分块大小,分配一个 512MB 内存可能失败(OOM)。
- 但如果拆分成 128MB 小块,则内存分配可以成功(150 + 150 + 150 + 62 = 512MB)。
3. 有了限制后还会 OOM 吗?
限制分块大小后,仍可能出现以下情况导致 OOM:
- 显存总量确实不足:即使通过拆分,也没有足够的小块总量。
- 梯度累积或激活占用过多:显存中需要同时保存前向、后向计算的中间结果(尤其是多层 Transformer 模型),如果这些结果太多或太大,显存仍然会耗尽。
解决方法:
- 进一步减少
--per_device_train_batch_size。 - 启用显存优化选项,例如 PyTorch 的
torch.utils.checkpoint或模型并行。 - 考虑混合精度训练(使用
torch.cuda.amp或transformers提供的fp16支持)。
4. 设置分块大小的注意事项
-
分块大小不能太小:
太小的分块会导致分配和释放显存的频率增加,从而降低性能。128MB 是一个合理的折中值。 -
显存足够时可以调大:
如果显存充裕,例如使用 32GB 显存的 GPU,可以尝试将max_split_size_mb设置为更大的值(如 256MB 或 512MB),以减少分块分配的开销。
5. 总结
通过设置 max_split_size_mb:128,PyTorch 内存分配器可以避免因为找不到大块连续内存而导致的 OOM,大大提高了显存碎片化情况下的利用率。这种方法对于显存紧张或碎片化严重的场景非常有效。

















 1873
1873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









