






串行数据流分成四个相位时钟恢复
1. 为何这么快
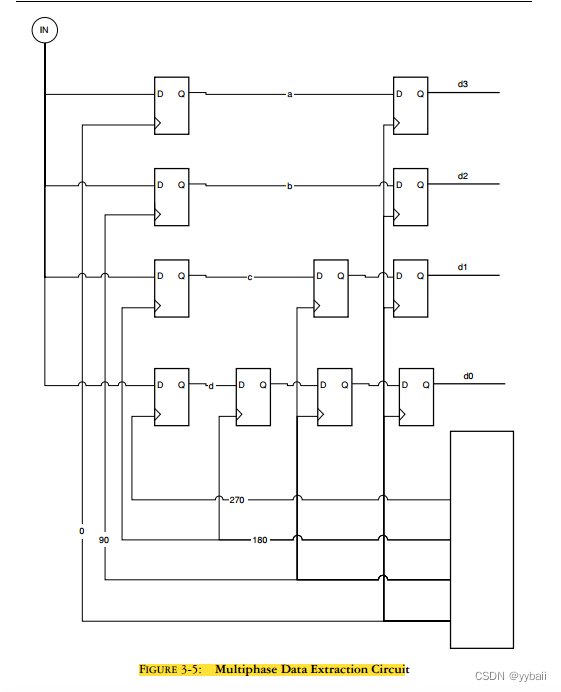
每个触发器送入由下一个最低相位时钟的触发器, 直到以零相时钟开始计时。这就将输入的数据流反串成一个4位字,以输入数据流的1/4时钟速率运行。
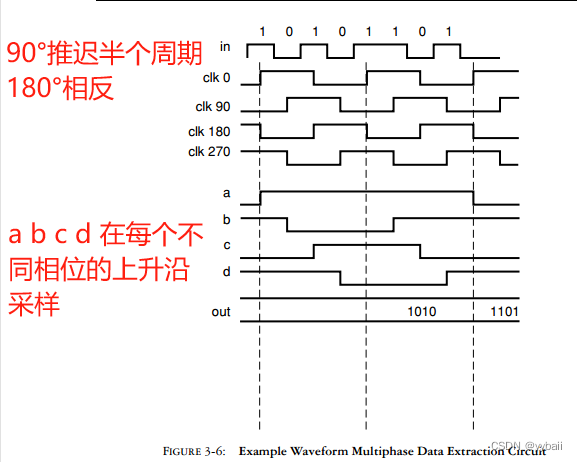
2. 线路编码方案
将原始数据改成接收方可以接收的数据形式
2.1 8B/10B 编码解码
① IBM开发并推广,高速串行通信常用
② 将8bit数据改为10bit数据,使得编码后的0和1的数量相等,在宏观数据上直流被平衡掉了(也叫直流平衡)
③直流平衡的方法:running disparity–运行差分
④ 8b / 10b允许将12个特殊字符解码为12个通常称为K字符的控制字符。
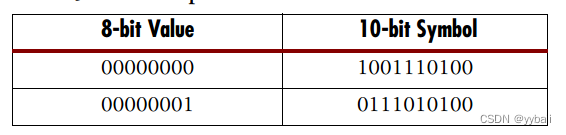
2.2 运行差异–running disparity
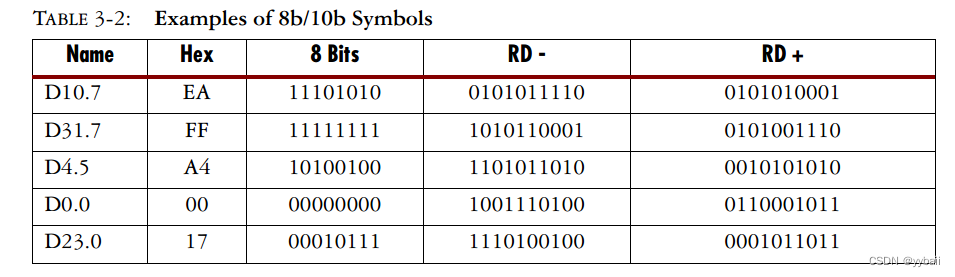
8b/10b使用两个不同的符号来分配每个数据值。在大多数情况下,其中一个符号有6个零和4个1,另一个符号有4个零和6个1(3b/4b,5b/6b)。监控1和0的总数,并根据使直流平衡恢复正常所需的内容选择下一个符号。这两个符号通常被称为+和-符号。符号示例如表3-2所示。
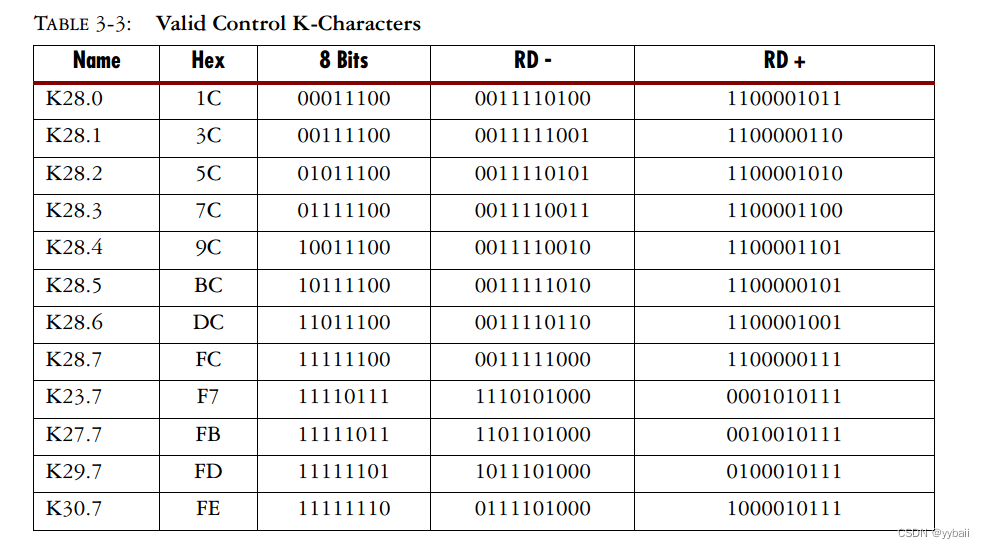
2.2 控制字符
刚才的表格中的以D开头的字符成为数据字符,它代表的是数据信息;其实不只有数据信息,高速串行总线传输的还有控制字符,如下:
控制字符用于对齐、控制和将带宽划分为子通道。
2.3 逗号检测
它是指定为对齐序列的一两个符号,可以看作是一个标志。
数据对齐是解串器的一项重要功能。图3-7表示串行流中有效的8b/10b数据。
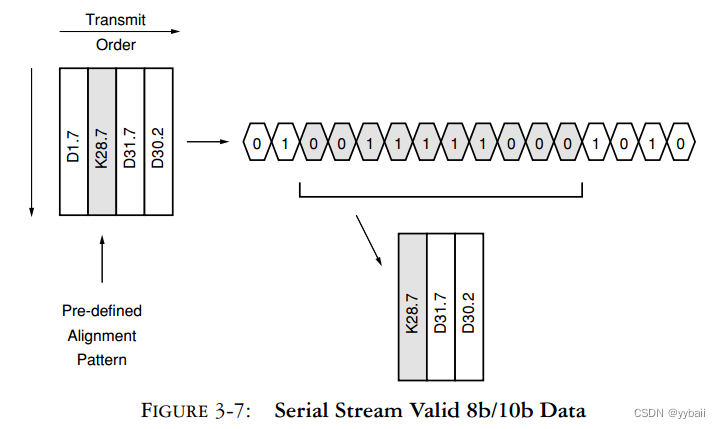
我们怎么知道符号的边界在哪里?符号由逗号分隔。在这里,逗号是指定为逗号或对齐序列的一个或两个符号。这个序列通常可以在收发器中设置,但在某些情况下,它可能是预定义的。
接收端扫描传入的数据流以查找指定的位序列。如果找到该序列,反序列化器将重置单词边界以匹配检测到的逗号序列。这是连续扫描。一旦对齐完成,检测到的所有后续逗号都应该发现已经设置了对齐。当然,逗号序列在任何序列组合中必须是唯一的。
例如,如果我们使用信号符号c作为逗号,那么我们必须确定没有有序的符号集xy包含位序列c。使用预定义的协议不是问题,因为逗号字符已经定义好了。
通常使用k字符的一个或多个特殊子集。该子集由K28.1、K28.5和K28.7组成,它们的前7位都是1100000。这种模式只存在于这些字符中;任何有序的数据集和其他k字符都不会包含这个序列。因此,它非常适合用于对齐。在构建自定义协议的情况下,最安全、最常用的解决方案是从知名协议中“借用”序列。千兆以太网使用K28.5作为逗号。
所使用的名称——比如D0.3和k28.5——来自于编码器和解码器的构建方式。
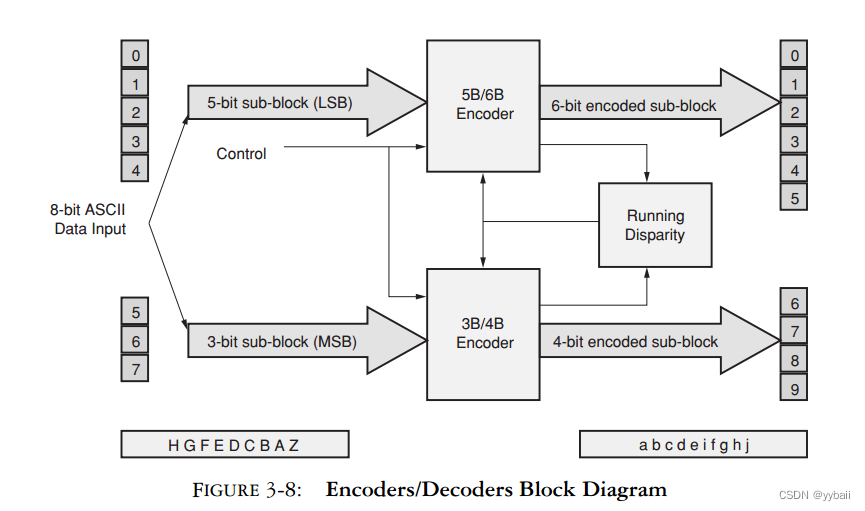
下图是8b/10b的整体流程示意图
2.4 Scrambling
加扰:对数据重新排序或编码的一种方法,使其看起来是随机的,但可以解扰。
过度使用带宽是8b/10b方案的缺点之一。要获得2.5 Gb的带宽,需要3.125 Gb/s的线速。加扰技术可以很容易地处理时钟跃迁和直流偏置问题,而不需要增加带宽。
加扰一种重新排序或编码数据的方法,使其看起来是随机的,但它仍然可以被解扰。我们希望随机化器能够分解长时间的0和1。显然,我们希望解密器在不需要任何特殊对齐信息的情况下解密比特。这种特性称为自同步代码。
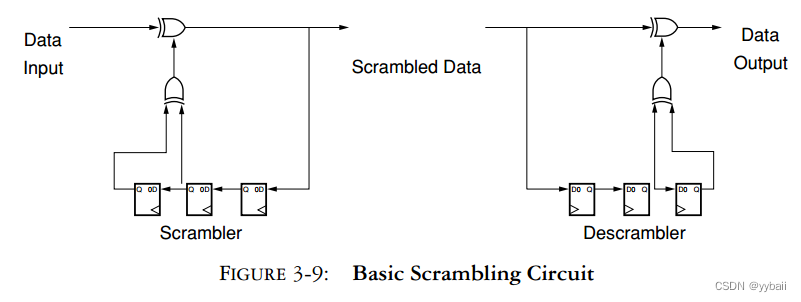
一个简单的扰频器由一系列的触发器组成,用来移动数据流。大多数触发器只是提供下一个比特,但偶尔一个触发器会与流中的旧比特独占地进行或与。该概念如图3-9所示。















 5864
5864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









