







目录
参考文章:https://aistudio.baidu.com/aistudio/modelsdetail?modelId=22
参考文章:https://paddlenlp.readthedocs.io/zh/latest/FAQ.html
参考文章:https://developer.aliyun.com/article/1066857
参考文章:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie#%E8%AE%AD%E7%BB%83%E5%AE%9A%E5%88%B6
参考文章: https://github.com/PaddlePaddle/PaddleNLP/discussions/3316
官方网址:https://www.paddlepaddle.org.cn/
python版本:3.8.10
相关包的版本
scipy==1.7.3
numpy==1.21.6
pandas==1.2.4
SQLAlchemy==1.4.18
cuda-python==11.7.1
系统:win10
显卡:GTX1060
nvidia-smi
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 531.68 Driver Version: 531.68 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce GTX 1060 6GB WDDM | 00000000:01:00.0 On | N/A |
| 47% 63C P2 122W / 120W| 4767MiB / 6144MiB | 96% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_May__3_19:00:59_Pacific_Daylight_Time_2022
Cuda compilation tools, release 11.7, V11.7.64
Build cuda_11.7.r11.7/compiler.31294372_0
CUDA:11.7
安装
首先,先安装paddlepaddle-gpu版,具体安装逻辑可以在官网查找到
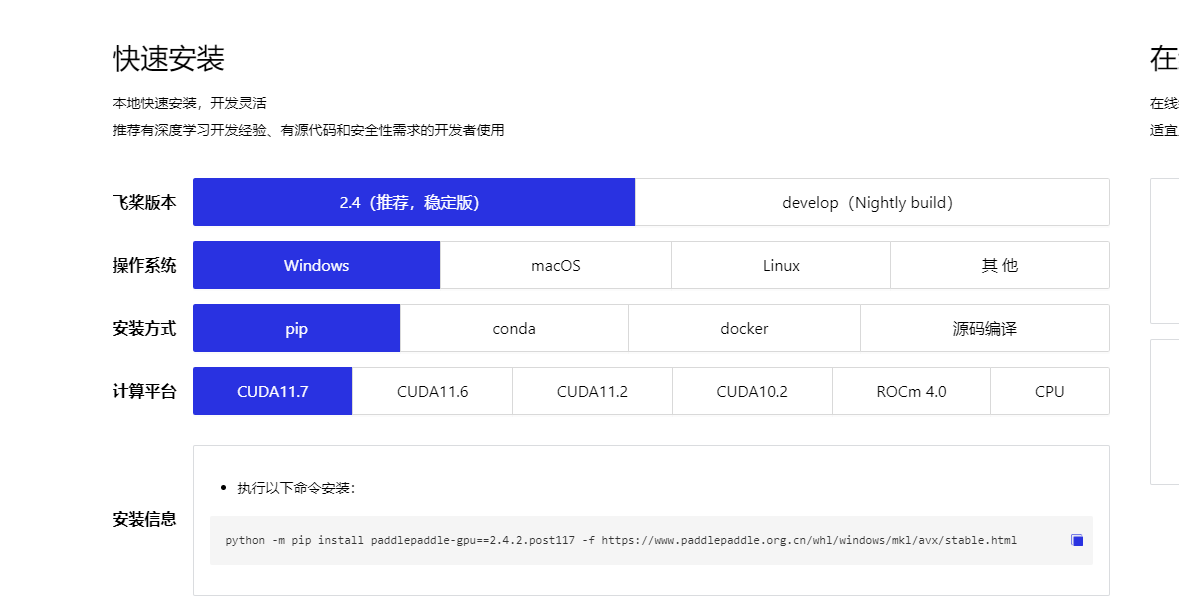
这里,我使用的gpu安装版本,下面是复制语句
python -m pip install paddlepaddle-gpu==2.4.2.post117 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple
安装好后用下面语句测试一下是否安装成功
import paddle
paddle.utils.run_check()
正常反馈信息
Running verify PaddlePaddle program ...
W0424 12:49:36.235811 1876 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 12.1, Runtime API Version: 11.7
W0424 12:49:36.240806 1876 gpu_resources.cc:91] device: 0, cuDNN Version: 8.8.
PaddlePaddle works well on 1 GPU.
PaddlePaddle works well on 1 GPUs.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
然后安装paddlenlp
pip install paddlenlp -i https://pypi.tuna.tsinghua.edu.cn/simple
使用
参考文章:https://paddlenlp.readthedocs.io/zh/latest/FAQ.html
参考文章:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie#%E8%AE%AD%E7%BB%83%E5%AE%9A%E5%88%B6
直接使用预训练模型
from pprint import pprint
from paddlenlp import Taskflow
# os.environ['PPNLP_HOME'] = 'test_path'# 修改环境变量中的默认路径-不需要手动创建根目录-不知道是不是中文路径问题,导致无效
# os.environ['HUB_HOME'] = 'test_path'
ie = Taskflow('information_extraction', model='uie-base') # 下载到默认路径
# 设置
schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
ie.set_schema(schema)
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
打印结果
[{'时间': [{'end': 6,
'probability': 0.9857378532924486,
'start': 0,
'text': '2月8日上午'}],
'赛事名称': [{'end': 23,
'probability': 0.8503087726820695,
'start': 6,
'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'选手': [{'end': 31,
'probability': 0.8981548639781138,
'start': 28,
'text': '谷爱凌'}]}]
自行构造数据进行微调
构造数据
首先,使用doccano进行数据标注,具体可以参考这篇文章或者PaddleNLP中doccano文章的来进行数据标注。
其次,准备utils.py,finetune.py,doccano.py这三份代码。在命令行模式下,先将刚刚导出的doccano数据转化成需要的数据格式。
python doccano.py --doccano_file ./data/doccano_ext.json --task_type "ext" --save_dir ./data --negative_ratio 5
这里使用的是【抽取式任务数据转换】,其他模式请自行参考文章。
配置参数说明
- doccano_file: 从doccano导出的数据标注文件。
- save_dir: 训练数据的保存目录,默认存储在data目录下。
- negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。
- splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。
- task_type: 选择任务类型,可选有抽取和分类两种类型的任务。
- options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为[“正向”, “负向”]。
- prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。
- is_shuffle: 是否对数据集进行随机打散,默认为True。
- seed: 随机种子,默认为1000.
- separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为"##"。
备注: - 默认情况下 doccano.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 doccano.py 脚本,将会覆盖已有的同名数据文件
- 在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过negative_ratio控制自动构造的负样本比例;负样本数量 = negative_ratio * 正样本数量。
- 对于从doccano导出的文件,默认文件中的每条数据都是经过人工正确标注的。
进行微调训练
参考文章:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie#%E8%AE%AD%E7%BB%83%E5%AE%9A%E5%88%B6
使用下面的代码进行训练
python finetune.py --device "gpu" --logging_steps 100 --save_steps 100 --eval_steps 100 --seed 42 --model_name_or_path uie-base --output_dir model/paddlepaddle/model_best --train_path data/train.txt --dev_path data/dev.txt --max_seq_length 256 --per_device_eval_batch_size 8 --per_device_train_batch_size 8 --num_train_epochs 20 --learning_rate 1e-5 --label_names "start_positions" "end_positions" --do_train --do_eval --do_export --export_model_dir model/paddlepaddle/model_best --overwrite_output_dir --metric_for_best_model eval_f1 --load_best_model_at_end True --save_total_limit 1
参数说明
- model_name_or_path:必须,进行 few shot 训练使用的预训练模型。可选择的有 “uie-base”、 “uie-medium”, “uie-mini”, “uie-micro”, “uie-nano”, “uie-m-base”, “uie-m-large”。
- multilingual:是否是跨语言模型,用 “uie-m-base”, “uie-m-large” 等模型进微调得到的模型也是多语言模型,需要设置为 True;默认为 False。
- output_dir:必须,模型训练或压缩后保存的模型目录;默认为 None 。
- device: 训练设备,可选择 ‘cpu’、‘gpu’ 、'npu’其中的一种;默认为 GPU 训练。
- per_device_train_batch_size:训练集训练过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。
- per_device_eval_batch_size:开发集评测过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。
- learning_rate:训练最大学习率,UIE 推荐设置为 1e-5;默认值为3e-5。
- num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。
- logging_steps: 训练过程中日志打印的间隔 steps 数,默认100。
- save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。
- seed:全局随机种子,默认为 42。
- weight_decay:除了所有 bias 和 LayerNorm 权重之外,应用于所有层的权重衰减数值。可选;默认为 0.0;
- do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。
- do_eval:是否进行评估,设置该参数表示进行评估。
正常训练开始
[2023-04-24 14:37:21,978] [ INFO] - ***** Running training *****
[2023-04-24 14:37:21,978] [ INFO] - Num examples = 282
[2023-04-24 14:37:21,978] [ INFO] - Num Epochs = 20
[2023-04-24 14:37:21,978] [ INFO] - Instantaneous batch size per device = 8
[2023-04-24 14:37:21,978] [ INFO] - Total train batch size (w. parallel, distributed & accumulation) = 8
[2023-04-24 14:37:21,978] [ INFO] - Gradient Accumulation steps = 1
[2023-04-24 14:37:21,978] [ INFO] - Total optimization steps = 720.0
[2023-04-24 14:37:21,979] [ INFO] - Total num train samples = 5640.0
[2023-04-24 14:37:21,990] [ INFO] - Number of trainable parameters = 117946370
1%|█▏ | 10/720 [00:04<05:05, 2.33it/s
2%|█▏ | 11/720 [00:05<05:04, 2.33it/s
2%|█▎ | 12/720 [00:05<05:04, 2.33it/s
2%|█▍ | 13/720 [00:05<05:03, 2.33it/s
2%|█▌ | 14/720 [00:06<05:03, 2.33it/s
正常训练结束
100%|█████████████████████████████████████████████████████████
100%|█████████████████████████████████████████████████████████ ███████████████████████| 720/720 [05:55<00:00, 2.03it/s]
[2023-04-24 14:32:25,955] [ INFO] - Saving model checkpoint to model/paddlepaddle/model_best
[2023-04-24 14:32:25,958] [ INFO] - Configuration saved in model/paddlepaddle/model_best\config.json
[2023-04-24 14:32:28,291] [ INFO] - tokenizer config file saved in model/paddlepaddle/model_best\tokenizer_config.json
[2023-04-24 14:32:28,292] [ INFO] - Special tokens file saved in model/paddlepaddle/model_best\special_tokens_map.json
[2023-04-24 14:32:28,294] [ INFO] - ***** train metrics *****
[2023-04-24 14:32:28,294] [ INFO] - epoch = 20.0
[2023-04-24 14:32:28,295] [ INFO] - train_loss = 0.0004
[2023-04-24 14:32:28,295] [ INFO] - train_runtime = 0:05:55.21
[2023-04-24 14:32:28,295] [ INFO] - train_samples_per_second = 15.878
[2023-04-24 14:32:28,295] [ INFO] - train_steps_per_second = 2.027
[2023-04-24 14:32:28,297] [ INFO] - ***** Running Evaluation *****
[2023-04-24 14:32:28,297] [ INFO] - Num examples = 28
[2023-04-24 14:32:28,298] [ INFO] - Total prediction steps = 4
[2023-04-24 14:32:28,298] [ INFO] - Pre device batch size = 8
[2023-04-24 14:32:28,298] [ INFO] - Total Batch size = 8
50%|██████████████████████████████████████████
100%|█████████████████████████████████████████████████████████
100%|█████████████████████████████████████████████████████████ ███████████████████████████| 4/4 [00:00<00:00, 9.79it/s]
[2023-04-24 14:32:28,997] [ INFO] - ***** eval metrics *****
[2023-04-24 14:32:28,997] [ INFO] - epoch = 20.0
[2023-04-24 14:32:28,997] [ INFO] - eval_f1 = 1.0
[2023-04-24 14:32:28,997] [ INFO] - eval_loss = 0.0003
[2023-04-24 14:32:28,997] [ INFO] - eval_precision = 1.0
[2023-04-24 14:32:28,998] [ INFO] - eval_recall = 1.0
[2023-04-24 14:32:28,998] [ INFO] - eval_runtime = 0:00:00.69
[2023-04-24 14:32:28,998] [ INFO] - eval_samples_per_second = 40.097
[2023-04-24 14:32:28,998] [ INFO] - eval_steps_per_second = 5.728
[2023-04-24 14:32:29,041] [ INFO] - Exporting inference model to model/paddlepaddle/model_best\model
[2023-04-24 14:32:44,238] [ INFO] - Inference model exported.
[2023-04-24 14:32:44,239] [ INFO] - tokenizer config file saved in model/paddlepaddle/model_best\tokenizer_config.json
[2023-04-24 14:32:44,240] [ INFO] - Special tokens file saved in model/paddlepaddle/model_best\special_tokens_map.json
错误记录
参考文章:https://github.com/PaddlePaddle/PaddleNLP/issues/2608
只有运行日志vdlrecords.1677479107.log,没有模型信息
这里会存在一种情况,程序运行到Number of trainable parameters = 117946370处稍微等待了一下就自动跳出,没有训练的信息反馈。同时在输出目录中,只有运行日志vdlrecords.1677479107.log,没有模型信息。
这种是由于GPU的现存不足导致程序出错的,只要调低per_device_train_batch_size ,per_device_eval_batch_size ,max_seq_length 三者的数值即可。
ps:在pytorch中跟tf中都是会弹出错误信息的。这样很好找问题。而paddle中根本不提示信息,像我这种刚开始使用的新人来说,根本不知道哪里出了问题,排查问题排查了3天。
使用微调后的模型
from pprint import pprint
from paddlenlp import Taskflow
local_path = os.path.dirname(os.path.abspath(__file__))
model_path = os.path.abspath(os.path.join(local_path, 'model/paddlepaddle/gup_success_20230424'))
# 加载模型
ie = Taskflow('information_extraction', task_path=model_path)
# 设置
schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
ie.set_schema(schema)
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
离线蒸馏
参考文章:https://aistudio.baidu.com/aistudio/projectdetail/4516470?login_type=qzone
前提设置-修改utils.py
在上文中的utils.py后面添加如下的函数。
data_distill.py中使用到的部分
# data_distill.py
from paddlenlp.taskflow.utils import SchemaTree
def build_tree(schema, name='root'):
"""
Build the schema tree.
"""
schema_tree = SchemaTree(name)
for s in schema:
if isinstance(s, str):
schema_tree.add_child(SchemaTree(s))
elif isinstance(s, dict):
for k, v in s.items():
if isinstance(v, str):
child = [v]
elif isinstance(v, list):
child = v
else:
raise TypeError(
"Invalid schema, value for each key:value pairs should be list or string"
"but {} received".format(type(v)))
schema_tree.add_child(build_tree(child, name=k))
else:
raise TypeError("Invalid schema, element should be string or dict, "
"but {} received".format(type(s)))
return schema_tree
def schema2label_maps(task_type, schema=None):
if schema and isinstance(schema, dict):
schema = [schema]
label_maps = {}
if task_type == "entity_extraction":
entity2id = {}
for s in schema:
entity2id[s] = len(entity2id)
label_maps["entity2id"] = entity2id
elif task_type == "opinion_extraction":
schema = ["观点词", {"评价维度": ["观点词", "情感倾向[正向,负向]"]}]
logger.info(
"Opinion extracion does not support custom schema, the schema is default to %s."
% schema)
label_maps["entity2id"] = {"评价维度": 0, "观点词": 1}
label_maps["sentiment2id"] = {"正向": 0, "负向": 1}
else:
entity2id = {}
relation2id = {}
schema_tree = build_tree(schema)
schema_list = schema_tree.children[:]
while len(schema_list) > 0:
node = schema_list.pop(0)
if node.name not in entity2id.keys() and len(node.children) != 0:
entity2id[node.name] = len(entity2id)
for child in node.children:
if child.name not in relation2id.keys():
relation2id[child.name] = len(relation2id)
schema_list.append(child)
entity2id['object'] = len(entity2id)
label_maps["entity2id"] = entity2id
label_maps["relation2id"] = relation2id
label_maps["schema"] = schema
return label_maps
def doccano2distill(json_lines, task_type, label_maps=None):
"""Convert doccano to distill format"""
if task_type == "opinion_extraction":
outputs = []
for json_line in json_lines:
id2ent = {}
text = json_line['text']
output = {"text": text}
entity_list = []
entities = json_line['entities']
for entity in entities:
ent_text = text[entity['start_offset']:entity['end_offset']]
ent_type_gather = entity['label'].split("##")
if len(ent_type_gather) == 2:
ent_type, ent_senti = ent_type_gather
else:
ent_type = ent_type_gather[0]
ent_senti = None
ent_start_idx = entity['start_offset']
id2ent[entity['id']] = {
"text": ent_text,
"type": ent_type,
"start_index": ent_start_idx,
"sentiment": ent_senti
}
ent = {
"text": ent_text,
"type": ent_type,
"start_index": ent_start_idx
}
entity_list.append(ent)
output["entity_list"] = entity_list
aso_list = []
relations = json_line['relations']
for relation in relations:
_aspect = id2ent[relation["from_id"]]
if _aspect['sentiment']:
_opinion = id2ent[relation["to_id"]]
rel = {
"aspect": _aspect['text'],
"sentiment": _aspect['sentiment'],
"opinion": _opinion['text'],
"aspect_start_index": _aspect["start_index"],
"opinion_start_index": _opinion["start_index"]
}
aso_list.append(rel)
output["aso_list"] = aso_list
outputs.append(output)
else:
outputs = []
for json_line in json_lines:
id2ent = {}
text = json_line['text']
output = {"text": text}
entity_list = []
entities = json_line['entities']
for entity in entities:
ent_text = text[entity['start_offset']:entity['end_offset']]
ent_type = "object" if entity['label'] not in label_maps[
'entity2id'].keys() else entity['label']
ent_start_idx = entity['start_offset']
id2ent[entity['id']] = {
"text": ent_text,
"type": ent_type,
"start_index": ent_start_idx
}
ent = {
"text": ent_text,
"type": ent_type,
"start_index": ent_start_idx
}
entity_list.append(ent)
output["entity_list"] = entity_list
spo_list = []
relations = json_line['relations']
for relation in relations:
_subject = id2ent[relation["from_id"]]
_object = id2ent[relation["to_id"]]
rel = {
"subject": _subject['text'],
"predicate": relation['type'],
"object": _object['text'],
"subject_start_index": _subject["start_index"],
"object_start_index": _object["start_index"]
}
spo_list.append(rel)
output["spo_list"] = spo_list
outputs.append(output)
return outputs
def synthetic2distill(texts, infer_results, task_type, label_maps=None):
"""Convert synthetic data to distill format"""
if task_type == "opinion_extraction":
outputs = []
for i, line in enumerate(infer_results):
pred = line
# pred = line[0]
output = {"text": texts[i]}
entity_list = []
aso_list = []
for key1 in pred.keys():
for s in pred[key1]:
ent = {
"text": s["text"],
"type": key1,
"start_index": s["start"]
}
entity_list.append(ent)
if "relations" in s.keys() and "观点词" in s["relations"].keys(
) and "情感倾向[正向,负向]" in s["relations"].keys():
for o in s["relations"]["观点词"]:
rel = {
"aspect":
s["text"],
"sentiment":
s["relations"]["情感倾向[正向,负向]"][0]["text"],
"opinion":
o["text"],
"aspect_start_index":
s["start"],
"opinion_start_index":
o["start"]
}
aso_list.append(rel)
ent = {
"text": o["text"],
"type": "观点词",
"start_index": o["start"]
}
entity_list.append(ent)
output["entity_list"] = entity_list
output["aso_list"] = aso_list
outputs.append(output)
else:
outputs = []
for i, line in enumerate(infer_results):
pred = line
# pred = line[0]
output = {"text": texts[i]}
entity_list = []
spo_list = []
for key1 in pred.keys():
for s in pred[key1]:
ent = {
"text": s['text'],
"type": key1,
"start_index": s['start']
}
entity_list.append(ent)
if "relations" in s.keys():
for key2 in s['relations'].keys():
for o1 in s['relations'][key2]:
if 'start' in o1.keys():
rel = {
"subject": s['text'],
"predicate": key2,
"object": o1['text'],
"subject_start_index": s['start'],
"object_start_index": o1['start']
}
spo_list.append(rel)
if 'relations' not in o1.keys():
ent = {
"text": o1['text'],
"type": "object",
"start_index": o1['start']
}
entity_list.append(ent)
else:
ent = {
"text": o1['text'],
"type": key2,
"start_index": o1['start']
}
entity_list.append(ent)
for key3 in o1['relations'].keys():
for o2 in o1['relations'][key3]:
ent = {
"text": o2['text'],
"type": "object",
"start_index": o2['start']
}
entity_list.append(ent)
rel = {
"subject":
o1['text'],
"predicate":
key3,
"object":
o2['text'],
"subject_start_index":
o1['start'],
"object_start_index":
o2['start']
}
spo_list.append(rel)
output["entity_list"] = entity_list
output["spo_list"] = spo_list
outputs.append(output)
return outputs
evaluate_teacher.py中使用到的部分
# evaluate_teacher.py
def postprocess(batch_outputs,
offset_mappings,
texts,
label_maps,
task_type="relation_extraction"):
if task_type == "entity_extraction":
batch_ent_results = []
for entity_output, offset_mapping, text in zip(batch_outputs[0].numpy(),
offset_mappings, texts):
entity_output[:, [0, -1]] -= np.inf
entity_output[:, :, [0, -1]] -= np.inf
ent_list = []
for l, start, end in zip(*np.where(entity_output > 0.)):
start, end = (offset_mapping[start][0], offset_mapping[end][-1])
ent = {
"text": text[start:end],
"type": label_maps['id2entity'][l],
"start_index": start
}
ent_list.append(ent)
batch_ent_results.append(ent_list)
return batch_ent_results
else:
batch_ent_results = []
batch_rel_results = []
for entity_output, head_output, tail_output, offset_mapping, text in zip(
batch_outputs[0].numpy(),
batch_outputs[1].numpy(),
batch_outputs[2].numpy(),
offset_mappings,
texts,
):
entity_output[:, [0, -1]] -= np.inf
entity_output[:, :, [0, -1]] -= np.inf
ents = set()
ent_list = []
for l, start, end in zip(*np.where(entity_output > 0.)):
ents.add((start, end))
start, end = (offset_mapping[start][0], offset_mapping[end][-1])
ent = {
"text": text[start:end],
"type": label_maps['id2entity'][l],
"start_index": start
}
ent_list.append(ent)
batch_ent_results.append(ent_list)
rel_list = []
for sh, st in ents:
for oh, ot in ents:
p1s = np.where(head_output[:, sh, oh] > 0.)[0]
p2s = np.where(tail_output[:, st, ot] > 0.)[0]
ps = set(p1s) & set(p2s)
for p in ps:
if task_type in [
"relation_extraction", "event_extraction"
]:
rel = {
"subject":
text[offset_mapping[sh][0]:offset_mapping[st]
[1]],
"predicate":
label_maps['id2relation'][p],
"object":
text[offset_mapping[oh][0]:offset_mapping[ot]
[1]],
"subject_start_index":
offset_mapping[sh][0],
"object_start_index":
offset_mapping[oh][0]
}
else:
rel = {
"aspect":
text[offset_mapping[sh][0]:offset_mapping[st]
[1]],
"sentiment":
label_maps['id2relation'][p],
"opinion":
text[offset_mapping[oh][0]:offset_mapping[ot]
[1]],
"aspect_start_index":
offset_mapping[sh][0],
"opinion_start_index":
offset_mapping[oh][0]
}
rel_list.append(rel)
batch_rel_results.append(rel_list)
return (batch_ent_results, batch_rel_results)
import copy
from data_collator import DataCollator
def create_dataloader(dataset,
tokenizer,
max_seq_len=128,
batch_size=1,
label_maps=None,
mode="train",
task_type="relation_extraction"):
def tokenize_and_align_train_labels(example):
tokenized_inputs = tokenizer(
example['text'],
max_length=max_seq_len,
padding=False,
truncation=True,
return_attention_mask=True,
return_token_type_ids=False,
return_offsets_mapping=True,
)
offset_mapping = tokenized_inputs["offset_mapping"]
ent_labels = []
for e in example["entity_list"]:
_start, _end = e['start_index'], e['start_index'] + len(
e['text']) - 1
start = map_offset(_start, offset_mapping)
end = map_offset(_end, offset_mapping)
if start == -1 or end == -1:
continue
label = label_maps['entity2id'][e['type']]
ent_labels.append([label, start, end])
outputs = {
"input_ids": tokenized_inputs["input_ids"],
"attention_mask": tokenized_inputs["attention_mask"],
"labels": {
"ent_labels": ent_labels,
"rel_labels": []
}
}
if task_type in ["relation_extraction", "event_extraction"]:
rel_labels = []
for r in example["spo_list"]:
_sh, _oh = r["subject_start_index"], r["object_start_index"]
_st, _ot = _sh + len(r["subject"]) - 1, _oh + len(
r["object"]) - 1
sh = map_offset(_sh, offset_mapping)
st = map_offset(_st, offset_mapping)
oh = map_offset(_oh, offset_mapping)
ot = map_offset(_ot, offset_mapping)
if sh == -1 or st == -1 or oh == -1 or ot == -1:
continue
p = label_maps["relation2id"][r["predicate"]]
rel_labels.append([sh, st, p, oh, ot])
outputs['labels']['rel_labels'] = rel_labels
elif task_type == "opinion_extraction":
rel_labels = []
for r in example["aso_list"]:
_ah, _oh = r["aspect_start_index"], r["opinion_start_index"]
_at, _ot = _ah + len(r["aspect"]) - 1, _oh + len(
r["opinion"]) - 1
ah = map_offset(_ah, offset_mapping)
at = map_offset(_at, offset_mapping)
oh = map_offset(_oh, offset_mapping)
ot = map_offset(_ot, offset_mapping)
if ah == -1 or at == -1 or oh == -1 or ot == -1:
continue
s = label_maps["sentiment2id"][r["sentiment"]]
rel_labels.append([ah, at, s, oh, ot])
outputs['labels']['rel_labels'] = rel_labels
return outputs
def tokenize(example):
tokenized_inputs = tokenizer(
example['text'],
max_length=max_seq_len,
padding=False,
truncation=True,
return_attention_mask=True,
return_offsets_mapping=True,
return_token_type_ids=False,
)
tokenized_inputs['text'] = example['text']
return tokenized_inputs
if mode == "train":
dataset = dataset.map(tokenize_and_align_train_labels)
else:
dataset_copy = copy.deepcopy(dataset)
dataset = dataset.map(tokenize)
data_collator = DataCollator(tokenizer,
label_maps=label_maps,
task_type=task_type)
shuffle = True if mode == "train" else False
batch_sampler = paddle.io.BatchSampler(dataset=dataset,
batch_size=batch_size,
shuffle=shuffle)
dataloader = paddle.io.DataLoader(dataset=dataset,
batch_sampler=batch_sampler,
collate_fn=data_collator,
num_workers=0,
return_list=True)
if mode != "train":
dataloader.dataset.raw_data = dataset_copy
return dataloader
def get_label_maps(task_type="relation_extraction", label_maps_path=None):
with open(label_maps_path, 'r', encoding='utf-8') as fp:
label_maps = json.load(fp)
if task_type == "entity_extraction":
entity2id = label_maps['entity2id']
id2entity = {idx: t for t, idx in entity2id.items()}
label_maps['id2entity'] = id2entity
else:
entity2id = label_maps['entity2id']
relation2id = label_maps['relation2id'] if task_type in [
"relation_extraction", "event_extraction"
] else label_maps['sentiment2id']
id2entity = {idx: t for t, idx in entity2id.items()}
id2relation = {idx: t for t, idx in relation2id.items()}
label_maps['id2entity'] = id2entity
label_maps['id2relation'] = id2relation
return label_maps
evaluate_teacher.py中使用到的部分
# train.py
criteria_map = {
"entity_extraction": "entity_f1",
"opinion_extraction": "relation_f1", # (Aspect, Sentiment, Opinion)
"relation_extraction": "relation_f1", # (Subject, Predicate, Object)
"event_extraction": "relation_f1" # (Trigger, Role, Argument)
}
def save_model_config(save_dir, model_config):
model_config_file = os.path.join(save_dir, "model_config.json")
with open(model_config_file, "w", encoding="utf-8") as fp:
fp.write(json.dumps(model_config, ensure_ascii=False, indent=2))
通过训练好的UIE定制模型预测无监督数据的标签
data_distill.py \
--data_path /home/aistudio/data \
--save_dir student_data \
--task_type relation_extraction \
--synthetic_ratio 10 \
--model_path /home/aistudio/checkpoint/model_best
输出信息
[2023-05-06 11:11:08,044] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './model/paddlepaddle/model_best'.
[2023-05-06 11:11:19,840] [ INFO] - Save 167 examples to ./model/paddlepaddle/distill_task\train_data.json.
[2023-05-06 11:11:19,842] [ INFO] - Save 17 examples to ./model/paddlepaddle/distill_task\dev_data.json.
[2023-05-06 11:11:19,844] [ INFO] - Save 18 examples to ./model/paddlepaddle/distill_task\test_data.json.
Process finished with exit code 0
默认参数
parser.add_argument("--data_path", default="../data", type=str, help="The directory for labeled data with doccano format and the large scale unlabeled data.")
parser.add_argument("--model_path", type=str, default="../checkpoint/model_best", help="The path of saved model that you want to load.")
parser.add_argument("--save_dir", default="./distill_task", type=str, help="The path of data that you wanna save.")
parser.add_argument("--synthetic_ratio", default=10, type=int, help="The ratio of labeled and synthetic samples.")
parser.add_argument("--task_type", choices=['relation_extraction', 'event_extraction', 'entity_extraction', 'opinion_extraction'], default="entity_extraction", type=str, help="Select the training task type.")
parser.add_argument("--seed", type=int, default=1000, help="Random seed for initialization")
可配置参数说明:
- data_path: 标注数据(doccano_ext.json)及无监督文本(unlabeled_data.txt)路径。
- model_path: 训练好的UIE定制模型路径。
- save_dir: 学生模型训练数据保存路径。
- synthetic_ratio: 控制合成数据的比例。最大合成数据数量=synthetic_ratio*标注数据数量。
- task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取,需指定任务类型。
- seed: 随机种子,默认为1000。
data_distill.py源码
这里的代码与原文章中的代码有稍微的出入,主要是我的训练数据是默认utf-8格式,但是我在win上执行,导致了所有读取数据部分都是默认gb18030,所以改成使用utf-8模式。
# -*- coding:utf-8 -*-
# author: cyz
# time: 2023/5/5 16:30
import os, sys
# sys.path.append(os.path.join(os.path.dirname(os.path.abspath(__file__)), '..'))
# os.chdir(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# coding=utf-8
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import json
import math
import random
import argparse
from tqdm import tqdm
import numpy as np
import paddle
from paddlenlp import Taskflow
from paddlenlp.taskflow.utils import SchemaTree
from paddlenlp.utils.log import logger
from utils import set_seed, build_tree, schema2label_maps, doccano2distill, synthetic2distill
def do_data_distill():
set_seed(args.seed)
# Generate closed-domain label maps
if not os.path.exists(args.save_dir):
os.mkdir(args.save_dir)
label_maps = schema2label_maps(args.task_type, schema=args.schema)
label_maps_path = os.path.join(args.save_dir, "label_maps.json")
# Save closed-domain label maps file
with open(label_maps_path, "w", encoding='utf-8') as fp: # 编码
fp.write(json.dumps(label_maps, ensure_ascii=False))
# Load doccano file and convert to distill format
sample_index = json.loads(
open(os.path.join(args.data_path, "sample_index.json")).readline())
train_ids = sample_index["train_ids"]
dev_ids = sample_index["dev_ids"]
test_ids = sample_index["test_ids"]
json_lines = [] # 读取文件位置,编码
with open(os.path.join(args.data_path, "doccano_ext.json"), "r", encoding="utf-8") as fp:
for line in fp:
json_lines.append(json.loads(line))
train_lines = [json_lines[i] for i in train_ids]
train_lines = doccano2distill(train_lines, args.task_type, label_maps)
dev_lines = [json_lines[i] for i in dev_ids]
dev_lines = doccano2distill(dev_lines, args.task_type, label_maps)
test_lines = [json_lines[i] for i in test_ids]
test_lines = doccano2distill(test_lines, args.task_type, label_maps)
# Load trained UIE model
uie = Taskflow("information_extraction",
schema=args.schema,
task_path=args.model_path)
if args.synthetic_ratio > 0:
# Generate synthetic data
texts = open(os.path.join(args.data_path, # 读取文件位置,编码
"unlabeled_data.txt"), "r", encoding="utf-8").readlines()
actual_ratio = math.ceil(len(texts) / len(train_lines))
if actual_ratio <= args.synthetic_ratio or args.synthetic_ratio == -1:
infer_texts = texts
else:
idxs = random.sample(range(0, len(texts)),
args.synthetic_ratio * len(train_lines))
infer_texts = [texts[i] for i in idxs]
infer_results = []
for text in tqdm(infer_texts, desc="Predicting: ", leave=False):
# infer_results.append(uie(text))
infer_results.extend(uie(text))
train_synthetic_lines = synthetic2distill(texts, infer_results,
args.task_type)
# Concat origin and synthetic data
train_lines.extend(train_synthetic_lines)
def _save_examples(save_dir, file_name, examples):
count = 0
save_path = os.path.join(save_dir, file_name)
with open(save_path, "w", encoding="utf-8") as f:
for example in examples:
f.write(json.dumps(example, ensure_ascii=False) + "\n")
count += 1
logger.info("Save %d examples to %s." % (count, save_path))
_save_examples(args.save_dir, "train_data.json", train_lines)
_save_examples(args.save_dir, "dev_data.json", dev_lines)
_save_examples(args.save_dir, "test_data.json", test_lines)
if __name__ == "__main__":
# yapf: disable
parser = argparse.ArgumentParser()
parser.add_argument("--data_path", default="./data", type=str, help="The directory for labeled data with doccano format and the large scale unlabeled data.")
parser.add_argument("--model_path", type=str, default="./model/paddlepaddle/model_best", help="The path of saved model that you want to load.")
parser.add_argument("--save_dir", default="./model/paddlepaddle/distill_task", type=str, help="The path of data that you wanna save.")
parser.add_argument("--synthetic_ratio", default=10, type=int, help="The ratio of labeled and synthetic samples.")
parser.add_argument("--task_type", choices=['relation_extraction', 'event_extraction', 'entity_extraction', 'opinion_extraction'], default="entity_extraction", type=str, help="Select the training task type.")
parser.add_argument("--seed", type=int, default=42, help="Random seed for initialization")
args = parser.parse_args()
# yapf: enable
# Define your schema here
schema = ['标题', '标段', '分包', '项目编号', '项目名称', '投标供应商', '中标机构', '中标机构地址', '中标金额']
args.schema = schema
do_data_distill()
ps:args.schema需要填老师模型的所有schema信息。
老师模型评估
UIE微调阶段针对UIE训练格式数据评估模型效果(该评估方式非端到端评估,不适合关系、事件等任务),可通过以下评估脚本针对原始标注格式数据评估模型效果。
!python evaluate_teacher.py \
--task_type relation_extraction \
--test_path ./student_data/dev_data.json \
--label_maps_path ./student_data/label_maps.json \
--model_path /home/aistudio/checkpoint/model_best
输出信息
[2023-05-08 10:03:05,227] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './model/paddlepaddle/gpu_text_flie_num_train_epochs_5_success_20230501'.
[2023-05-08 10:03:05,252] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'ernie-3.0-base-zh'.
[2023-05-08 10:03:05,253] [ INFO] - Already cached C:\Users\Administrator\.paddlenlp\models\ernie-3.0-base-zh\ernie_3.0_base_zh_vocab.txt
[2023-05-08 10:03:05,275] [ INFO] - tokenizer config file saved in C:\Users\Administrator\.paddlenlp\models\ernie-3.0-base-zh\tokenizer_config.json
[2023-05-08 10:03:05,276] [ INFO] - Special tokens file saved in C:\Users\Administrator\.paddlenlp\models\ernie-3.0-base-zh\special_tokens_map.json
[2023-05-08 10:05:49,782] [ INFO] - Evaluation precision: {'entity_f1': 0.95035, 'entity_precision': 0.93925, 'entity_recall': 0.96172}
Process finished with exit code 0
默认参数
parser.add_argument("--model_path", type=str, default=None, help="The path of saved model that you want to load.")
parser.add_argument("--test_path", type=str, default=None, help="The path of test set.")
parser.add_argument("--encoder", default="ernie-3.0-base-zh", type=str, help="Select the pretrained encoder model for GP.")
parser.add_argument("--label_maps_path", default="./ner_data/label_maps.json", type=str, help="The file path of the labels dictionary.")
parser.add_argument("--batch_size", type=int, default=16, help="Batch size per GPU/CPU for training.")
parser.add_argument("--max_seq_len", type=int, default=128, help="The maximum total input sequence length after tokenization.")
parser.add_argument("--task_type", choices=['relation_extraction', 'event_extraction', 'entity_extraction', 'opinion_extraction'], default="entity_extraction",
可配置参数说明:
- model_path: 训练好的UIE定制模型路径。
- test_path: 测试数据集路径。
- label_maps_path: 学生模型标签字典。
- batch_size: 批处理大小,默认为8。
- max_seq_len: 最大文本长度,默认为256。
- task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取的评估,需指定任务类型。
evaluate_teacher.py源码
这里的代码与原文章中的代码有稍微的出入,主要是该文章中使用的reader函数跟官方使用的reader函数不一样,所以这里改成将reader直接写在了evaluate_teacher上。
# -*- coding:utf-8 -*-
# author: cyz
# time: 2023/5/6 10:11
import os, sys
# sys.path.append(os.path.join(os.path.dirname(os.path.abspath(__file__)), '..'))
# os.chdir(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
import argparse
import json
import os
from tqdm import tqdm
import paddle
from paddlenlp.datasets import load_dataset
from paddlenlp.transformers import AutoTokenizer, AutoModel
from paddlenlp.utils.log import logger
from paddlenlp.layers import GlobalPointerForEntityExtraction, GPLinkerForRelationExtraction
from paddlenlp import Taskflow
from utils import postprocess, create_dataloader, get_label_maps
from utils import get_label_maps, synthetic2distill
from metric import get_eval
# 跟官方的reader不一样,这里改成单独使用
def reader(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
json_line = json.loads(line)
yield json_line
@paddle.no_grad()
def evaluate(uie, dataloader, task_type="relation_extraction"):
all_preds = ([], []) if task_type in [
"opinion_extraction", "relation_extraction", "event_extraction"
] else []
infer_results = []
all_texts = []
for batch in tqdm(dataloader, desc="Evaluating: ", leave=False):
_, _, _, texts = batch
all_texts.extend(texts)
infer_results.extend(uie(texts))
infer_results = synthetic2distill(all_texts, infer_results, task_type)
for res in infer_results:
if task_type == "entity_extraction":
all_preds.append(res['entity_list'])
else:
all_preds[0].append(res['entity_list'])
all_preds[1].append(res['spo_list'])
eval_results = get_eval(all_preds, dataloader.dataset.raw_data, task_type)
return eval_results
def do_eval():
# Load trained UIE model
uie = Taskflow("information_extraction",
schema=args.schema,
batch_size=args.batch_size,
task_path=args.model_path)
label_maps = get_label_maps(args.task_type, args.label_maps_path)
tokenizer = AutoTokenizer.from_pretrained("ernie-3.0-base-zh")
test_ds = load_dataset(reader, data_path=args.test_path, lazy=False)
test_dataloader = create_dataloader(test_ds,
tokenizer,
max_seq_len=args.max_seq_len,
batch_size=args.batch_size,
label_maps=label_maps,
mode="test",
task_type=args.task_type)
eval_result = evaluate(uie, test_dataloader, task_type=args.task_type)
logger.info("Evaluation precision: " + str(eval_result))
if __name__ == "__main__":
# yapf: disable
parser = argparse.ArgumentParser()
parser.add_argument("--model_path", type=str, default="./model/paddlepaddle/model_best", help="The path of saved model that you want to load.")
parser.add_argument("--test_path", type=str, default="./model/paddlepaddle/distill_task/dev_data.json", help="The path of test set.")
parser.add_argument("--label_maps_path", default="./model/paddlepaddle/distill_task/label_maps.json", type=str, help="The file path of the labels dictionary.")
parser.add_argument("--batch_size", type=int, default=8, help="Batch size per GPU/CPU for training.")
parser.add_argument("--max_seq_len", type=int, default=256, help="The maximum total input sequence length after tokenization.")
parser.add_argument("--task_type", choices=['relation_extraction', 'event_extraction', 'entity_extraction', 'opinion_extraction'],
default="entity_extraction", type=str, help="Select the training task type.")
args = parser.parse_args()
# yapf: enable
schema = ['标题', '标段', '分包', '项目编号', '项目名称', '投标供应商', '中标机构', '中标机构地址', '中标金额']
args.schema = schema
do_eval()
学生模型训练
底座模型可以参考下面进行替换!
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-3.0
https://paddlenlp.readthedocs.io/zh/latest/model_zoo/transformers/ERNIE/contents.html
!python train.py \
--task_type relation_extraction \
--train_path student_data/train_data.json \
--dev_path student_data/dev_data.json \
--label_maps_path student_data/label_maps.json \
--num_epochs 100 \
--encoder ernie-3.0-mini-zh\
--device "gpu"\
--valid_steps 100\
--logging_steps 10\
--save_dir './checkpoint2'\
--batch_size 16
可配置参数说明:
- train_path: 训练集文件路径。
- dev_path: 验证集文件路径。
- batch_size: 批处理大小,默认为16。
- learning_rate: 学习率,默认为3e-5。
- save_dir: 模型存储路径,默认为./checkpoint。
- max_seq_len: 最大文本长度,默认为256。
- weight_decay: 表示AdamW优化器中使用的 weight_decay 的系数。
- warmup_proportion: 学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.0。
- num_epochs: 训练轮数,默认为100。
- seed: 随机种子,默认为1000。
encoder: 选择学生模型的模型底座,默认为ernie-3.0-mini-zh。 - task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取,需指定任务类型。
- logging_steps: 日志打印的间隔steps数,默认10。
- valid_steps: evaluate的间隔steps数,默认200。
- device: 选用什么设备进行训练,可选cpu或gpu。
- init_from_ckpt: 可选,模型参数路径,热启动模型训练;默认为None。
默认参数
parser.add_argument("--train_path", default=None, type=str, help="The path of train set.")
parser.add_argument("--dev_path", default=None, type=str, help="The path of dev set.")
parser.add_argument("--batch_size", default=16, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument("--learning_rate", default=3e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument("--save_dir", default='./checkpoint', type=str, help="The output directory where the model checkpoints will be written.")
parser.add_argument("--max_seq_len", default=256, type=int, help="The maximum input sequence length.")
parser.add_argument("--label_maps_path", default="./ner_data/label_maps.json", type=str, help="The file path of the labels dictionary.")
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", default=0.0, type=float, help="Linear warmup proption over the training process.")
parser.add_argument("--num_epochs", default=100, type=int, help="Number of epoches for training.")
parser.add_argument("--seed", default=1000, type=int, help="Random seed for initialization")
parser.add_argument("--encoder", default="ernie-3.0-mini-zh", type=str, help="Select the pretrained encoder model for GP.")
parser.add_argument("--task_type", choices=['relation_extraction', 'event_extraction', 'entity_extraction', 'opinion_extraction'], default="entity_extraction", type=str, help="Select the training task type.")
parser.add_argument("--logging_steps", default=10, type=int, help="The interval steps to logging.")
parser.add_argument("--valid_steps", default=200, type=int, help="The interval steps to evaluate model performance.")
parser.add_argument('--device', choices=['cpu', 'gpu'], default="gpu", help="Select which device to train model, defaults to gpu.")
parser.add_argument("--init_from_ckpt", default=None, type=str, help="The path of model parameters for initialization.")
train.py源码
# -*- coding:utf-8 -*-
# author: cyz
# time: 2023/5/6 14:38
import os, sys
# sys.path.append(os.path.join(os.path.dirname(os.path.abspath(__file__)), '..'))
# os.chdir(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
import argparse
import json
import time
import os
from functools import partial
import paddle
import paddle.nn as nn
from paddlenlp.datasets import load_dataset
from paddlenlp.transformers import AutoTokenizer, AutoModel
from paddlenlp.transformers import LinearDecayWithWarmup
from paddlenlp.utils.log import logger
from paddlenlp.layers import GlobalPointerForEntityExtraction, GPLinkerForRelationExtraction
from evaluate import evaluate
from criterion import Criterion
from utils import set_seed, get_label_maps, create_dataloader, criteria_map, save_model_config
# 跟官方的reader不一样,这里改成单独使用
def reader(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
json_line = json.loads(line)
yield json_line
def do_train():
paddle.set_device(args.device)
rank = paddle.distributed.get_rank()
if paddle.distributed.get_world_size() > 1:
paddle.distributed.init_parallel_env()
set_seed(args.seed)
label_maps = get_label_maps(args.task_type, args.label_maps_path)
train_ds = load_dataset(reader, data_path=args.train_path, lazy=False)
dev_ds = load_dataset(reader, data_path=args.dev_path, lazy=False)
tokenizer = AutoTokenizer.from_pretrained(args.encoder)
train_dataloader = create_dataloader(train_ds,
tokenizer,
max_seq_len=args.max_seq_len,
batch_size=args.batch_size,
label_maps=label_maps,
mode="train",
task_type=args.task_type)
dev_dataloader = create_dataloader(dev_ds,
tokenizer,
max_seq_len=args.max_seq_len,
batch_size=args.batch_size,
label_maps=label_maps,
mode="dev",
task_type=args.task_type)
encoder = AutoModel.from_pretrained(args.encoder)
if args.task_type == "entity_extraction":
model = GlobalPointerForEntityExtraction(encoder, label_maps)
else:
model = GPLinkerForRelationExtraction(encoder, label_maps)
model_config = {
"task_type": args.task_type,
"label_maps": label_maps,
"encoder": args.encoder
}
num_training_steps = len(train_dataloader) * args.num_epochs
lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps,
args.warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=args.weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
if args.init_from_ckpt and os.path.isfile(args.init_from_ckpt):
state_dict = paddle.load(args.init_from_ckpt)
model.set_dict(state_dict)
if paddle.distributed.get_world_size() > 1:
model = paddle.DataParallel(model)
criterion = Criterion()
global_step, best_f1 = 1, 0.
tr_loss, logging_loss = 0.0, 0.0
tic_train = time.time()
for epoch in range(1, args.num_epochs + 1):
for batch in train_dataloader:
input_ids, attention_masks, labels = batch
logits = model(input_ids, attention_masks)
loss = sum([criterion(o, l) for o, l in zip(logits, labels)]) / 3
loss.backward()
tr_loss += loss.item()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
if global_step % args.logging_steps == 0 and rank == 0:
time_diff = time.time() - tic_train
loss_avg = (tr_loss - logging_loss) / args.logging_steps
logger.info(
"global step %d, epoch: %d, loss: %.5f, speed: %.2f step/s"
% (global_step, epoch, loss_avg,
args.logging_steps / time_diff))
logging_loss = tr_loss
tic_train = time.time()
if global_step % args.valid_steps == 0 and rank == 0:
# save_dir = os.path.join(args.save_dir, "model_%d" % global_step)
# if not os.path.exists(save_dir):
# os.makedirs(save_dir)
# save_param_path = os.path.join(save_dir, "model_state.pdparams")
# paddle.save(model.state_dict(), save_param_path)
# save_model_config(save_dir, model_config)
# logger.disable()
# tokenizer.save_pretrained(save_dir)
# logger.enable()
eval_result = evaluate(model,
dev_dataloader,
label_maps,
task_type=args.task_type)
logger.info("Evaluation precision: " + str(eval_result))
f1 = eval_result[criteria_map[args.task_type]]
if f1 > best_f1:
logger.info(
f"best F1 performence has been updated: {best_f1:.5f} --> {f1:.5f}"
)
best_f1 = f1
save_dir = os.path.join(args.save_dir, "model_best")
if not os.path.exists(save_dir):
os.makedirs(save_dir)
save_param_path = os.path.join(save_dir,
"model_state.pdparams")
paddle.save(model.state_dict(), save_param_path)
save_model_config(save_dir, model_config)
logger.disable()
tokenizer.save_pretrained(save_dir)
logger.enable()
print("best_model已保存")
tic_train = time.time()
global_step += 1
if __name__ == "__main__":
# yapf: disable
parser = argparse.ArgumentParser()
parser.add_argument("--train_path", default="./model/paddlepaddle/distill_task/train_data.json", type=str, help="The path of train set.")
parser.add_argument("--dev_path", default="./model/paddlepaddle/distill_task/dev_data.json", type=str, help="The path of dev set.")
parser.add_argument("--batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument("--learning_rate", default=1e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument("--save_dir", default="./model/paddlepaddle/model_studen", type=str, help="The output directory where the model checkpoints will be written.")
parser.add_argument("--max_seq_len", default=256, type=int, help="The maximum input sequence length.")
parser.add_argument("--label_maps_path", default="./model/paddlepaddle/distill_task/label_maps.json", type=str, help="The file path of the labels dictionary.")
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", default=0.0, type=float, help="Linear warmup proption over the training process.")
parser.add_argument("--num_epochs", default=100, type=int, help="Number of epoches for training.")
parser.add_argument("--seed", default=1000, type=int, help="Random seed for initialization")
parser.add_argument("--encoder", default="ernie-3.0-mini-zh", type=str, help="Select the pretrained encoder model for GP.")
parser.add_argument("--task_type", choices=['relation_extraction', 'event_extraction', 'entity_extraction', 'opinion_extraction'], default="entity_extraction", type=str, help="Select the training task type.")
parser.add_argument("--logging_steps", default=10, type=int, help="The interval steps to logging.")
parser.add_argument("--valid_steps", default=200, type=int, help="The interval steps to evaluate model performance.")
parser.add_argument('--device', choices=['cpu', 'gpu'], default="gpu", help="Select which device to train model, defaults to gpu.")
parser.add_argument("--init_from_ckpt", default=None, type=str, help="The path of model parameters for initialization.")
args = parser.parse_args()
# yapf: enable
do_train()
输出结果
[2023-05-09 15:03:31,370] [ INFO] - global step 4590, epoch: 200, loss: 0.24162, speed: 1.44 step/s
[2023-05-09 15:03:36,442] [ INFO] - global step 4600, epoch: 200, loss: 0.22335, speed: 1.97 step/s
[2023-05-09 15:03:38,092] [ INFO] - Evaluation precision: {'entity_f1': 0.47482, 'entity_precision': 0.95652, 'entity_recall': 0.31579}
Process finished with exit code 0
模型损失太多了,后续研究如何增加训练数据。

















 6868
6868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









