







一、自动下载
1.1 通过HuggingFace模型ID自动下载
比如我们比如下载一个bert-base-uncased,需要用到AutoTokenizer 和 AutoModel 来下载模型和对应的分词器,它们能够识别并加载几乎任何在Hugging Face 上发布的预训练模型。
从transformers导入AutoModel和AutoTokenizer
from transformers import AutoModel, AutoTokenizer
指定模型的名ID
model_name = "google-bert/bert-base-uncased"
下载并加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
下载并加载模型
model = AutoModel.from_pretrained(model_name)
对于上面两个方法中都用到了from_pretrained这个函数方法,他还有其他常用的可选的参数,如下:
pretrained_model_name_or_path(str或os.PathLike,可选) :是在 Huggingface.co 上的模型存储库中托管的预训练模型的模型 ID。local_files_only(bool,可选,默认为False):是否只加载本地模型文件(即,不尝试下载模型)。force_download(bool, 可选,默认为 False):是否强制重新下载模型权重和配置文件,覆盖缓存版本。cache_dir(Union[str, os.PathLike],可选):用于缓存下载的预训练模型配置的目录路径。mirror(str, 可选):加速中国地区下载的镜像源,可填入镜像源地址。在国内,可以通过配置HuggingFace的镜像,参考这篇博客:HuggingFace镜像源设置_huggingface 修改镜像-CSDN博客,直接在脚本中配置即可,然后运行脚本下载模型。
1.2 模型保存
对于自动下载的模型,所有的相关文件都会以哈希值命名(这篇博客会告诉你为什么文件名是哈希值:不会修改HuggingFace模型下载默认缓存路径?一篇教会你! ),这样是为了为transforms库提供方便,我们人其实看不懂哈希值的,其包括了tokenizer和model文件等等,如下:

所以,如果有需要,我们可以用下面的方法,自动将哈希值的模型文件转化为人看得懂的文件:
tokenizer.save_pretrained("你想要保存的路径")
modell.save_pretrained("你想要保存的路径")
运行之后,新的文件路径下就有人看得懂的文件了!如下:
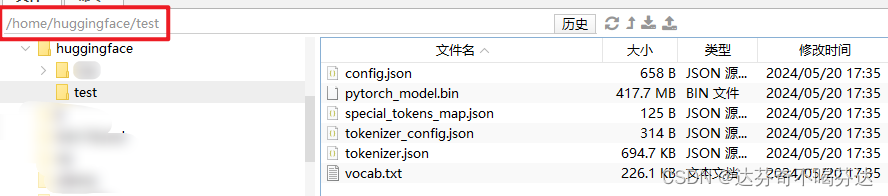
二、手动下载
2.1 Files
在HuggingFace中找到你需要的模型,进入Files and versions目录,这里使用google-bert/bert-base-uncased的例子
如果常用的是pytorch框架,我们需要下载这些文件:
pytorch_model.binconfig.jsonvocab.txttokenizer.jsontokenizer_config.json
也就是图上框选的文件,单击 ↓ 图标:

下载好打包放一个文件夹下:
bert-base-uncased
|-config.json
|-pytorch_model.bin
|-tokenizer.json
|-tokenizer_config.json
|-vocab.txt
如下图

然后就可以直接输入本地的模型路径,进行使用了。
2.2 模型加载
# 从本地加载模型
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("J:\\权重\\bert-base-uncased")
model = AutoModelForMaskedLM.from_pretrained("J:\\权重\\bert-base-uncased")
使用 AutoTokenizer编码语句
# 输入句子
seq = "I want eat apple."
# 将句子编码为模型输入格式
output_token = tokenizer(seq, return_tensors='pt') print(output_token)
# 输出如下
"""
{
'input_ids': [101, 1045, 2215, 4521, 6207, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1]
}
"""
通过tokenizer之后,我们将人类语言转化为了机器语言,接下来就可以输入模型了。
前向传播:
# 模型前向传播
output_text = model(**output_token)
print(output_text)
# 输出如下
"""
MaskedLMOutput(loss=None,
logits=tensor([[
[ -7.2956, -7.2397, -7.2123, ..., -6.6302, -6.5285, -4.5029],
[-12.3488, -11.8462, -12.1994, ..., -11.4275, -10.0496, -10.4256], [-12.4339, -12.0643, -12.2072, ..., -9.8157, -10.9645, -12.5600], ...,
[ -7.5780, -7.5130, -7.3408, ..., -7.6641, -6.0655, -7.4937],
[-11.6407, -11.3535, -11.7890, ..., -10.2565, -10.7414, -4.9831], [-11.4632, -11.5140, -11.4960, ..., -9.2537, -8.9689, -8.3067]]],
grad_fn=<ViewBackward0>), hidden_states=None, attentions=None)
"""
通过AutoModelForMaskedLM,我们将输入转化为了一系列的预测分数(logits),之后在对它们进行归一化就可以得到概率啦。
这就是通过huggingface的transforms库调用模型的基本流程,是不是很简单呢!

















 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









