











代码地址:https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.5/configs/pp_liteseg
虽然深度学习在语义分割方面取得了显著的飞跃,但很多模型的实时性并不令人满意。在这项工作中,作者提出了PP-LiteSeg,一个新的轻量级实时语义分割任务模型。
具体地说,作者提出了一个灵活和轻量级解码器(FLD)来减少以往解码器的计算开销。为了加强特征表示,作者还提出了一个统一的注意力融合模块(UAFM),它利用空间注意力和通道注意力产生一个注意力权重,然后将输入特征与权重融合。
此外,还提出了一种简单的金字塔池化模块(SPPM),在低计算成本的情况下聚合全局上下文信息。
实验表明,与其他方法相比,PP-LiteSeg在精度和速度之间取得了优越的权衡。在CityScapes测试集上,PP-LiteSeg在NVIDIA GTX1080Ti上分别达到了72.0%的mIoU/273.6FPS和77.5%的mIoU/102.6FPS。
开源地址:https://github.com/PaddlePaddle/PaddleSeg
简介
语义分割任务旨在精确预测图像中每个像素的标签。它已广泛应用于医学影像、自动驾驶、视频会议、半自动注释等应用。
随着深度学习的不断进步,许多基于卷积神经网络的语义分割方法已经被提出。FCN是第一个以端到端和像素对像素的方式训练的完全卷积网络。其提出了语义分割中的原始编解码器架构,在后续方法中得到了广泛的采用。
为了获得更高的精度,PSPNet利用一个金字塔池化模块来聚合全局上下文信息,而SFNet提出了一个flow alignment module来加强特征表示。
然而,由于这些模型的计算成本较高,因此并不适合实时落地应用。为了加快推理速度,Espnet-v2利用轻量级卷积从一个扩大的感受野中提取特征。BiSeNetV2提出了bilateral segmentation network,并分别提取了细节特征和语义特征。STDCSeg设计了一种新的backboe,名为STDC,以提高计算效率。然而,这些模型并不能在精度和速度之间取得令人满意的平衡。
在这项工作中提出了一个人为设计的实时语义分割网络PP-LiteSeg。如图2所示,PPLiteSeg采用了编解码器架构,由3个新的模块组成:
- Flexible and Lightweight Decoder (FLD)
- Unified Attention Fusion Module (UAFM)
- Simple Pyramid Pooling Module (SPPM)
语义分割模型中的编码器提取层次特征,解码器融合和上采样特征。
-
对于编码器中从low-level到high-level的特征,通道数量增加,空间尺寸减小;
-
对于解码器中从high-level到low-level的特征,空间大小增加;
而最近的模型的通道数量都相同。因此,本文提出了一个更为灵活的轻量级解码器(FLD),它逐渐减少了通道数量,增加了特征的空间大小。此外,所提出的解码器可以很容易地根据编码器进行调整。灵活的设计平衡了编码器和解码器的计算复杂度,使整个模型的计算效率得到了提升。
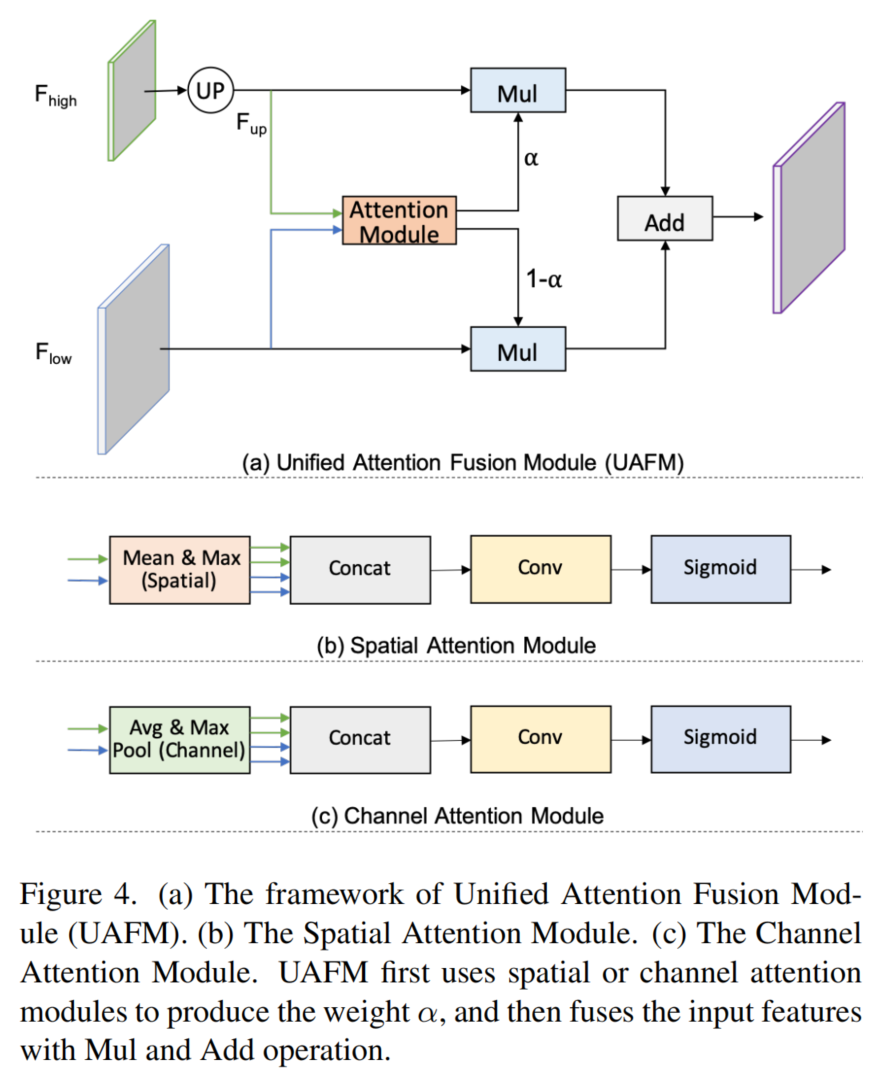
加强特征表示是提高分割精度的关键因素。它通常是通过在解码器中融合low-level到high-level特征来实现的。然而,现有方法中的融合模块通常计算成本较高。在这项工作中,作者提出了一个统一的注意力融合模块(UAFM)来有效地加强特征表示。如图4所示,UAFM首先利用注意力模块产生权重
α
\alpha
α,然后将输入特征与
α
\alpha
α融合。在UAFM中,有2种注意模块,即空间注意力模块和通道注意力模块,它们充分利用了输入特征的空间之间以及通道之间的关系。
上下文聚合是提高分割精度的另一个关键因素,但以往的聚合模块对于实时网络来说依然很耗时。基于PPM的框架,作者设计了一个简单的金字塔池化模块(SPPM),它减少了中间通道和输出通道,消除了Shortcut,并用一个add操作替换了concat操作。实验结果表明,SPPM可以在较低的计算成本下提高分割精度。
通过在Cityscapes和CamVid数据集上的大量实验评估了所提出的PP-LiteSeg。如下图所示,PP-LiteSeg在分割精度和推理速度之间实现了一个优越的权衡。
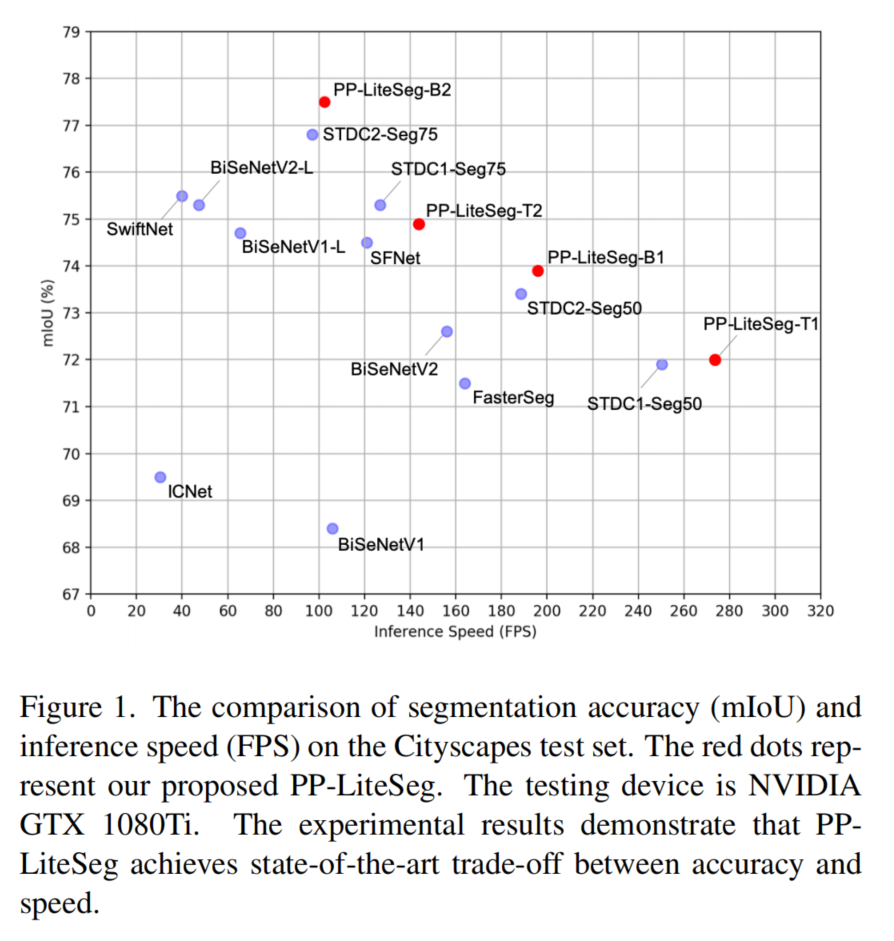
具体来说,PP-LiteSeg在Cityscapes测试集上达到了72.0%的mIoU/273.6FPS和77.5%的mIoU/102.6FPS。
主要贡献总结如下:
- 提出了一种灵活的轻量级解码器(FLD),减轻了解码器的冗余性,并平衡了编码器和解码器的计算成本。
- 提出了一个统一的注意力融合模块(UAFM),利用通道和空间注意力来加强特征表示。
- 提出了一个简单的金字塔池化模块(SPPM)来聚合全局上下文信息。在增加少量推理时间的情况下提高了分割精度。
- 在上述模块的基础上,提出了一种实时语义分割模型PP-LiteSeg。大量的实验证明了其SOTA性能。
相关工作
2.1 语义分割
FCN是第一个用于语义分割的完全卷积网络。它以端到端和像素对像素的方式进行训练。此外,任意大小的图像都可以通过FCN进行分割。根据FCN的设计,后来又提出了各种方法。
SegNet将编码器中的最大池化操作应用于解码器中的上采样操作。因此,解码器中的信息被重复利用,解码器也可以产生精细化的特征。
PSPNe提出了金字塔池化模块来聚合局部和全局信息,可以有效地提高分割精度。
此外,最近的语义分割方法利用了Transformer架构,实现了更高的精度。
2.2 实时语义分割
为了满足语义分割的实时需求,人们提出了很多方法,如轻量级模块设计、双分支架构、early-downsampling策略、多尺度图像级联网络等。
ENet采用early-downsampling策略来降低处理大图像和特征图的计算成本。为了提高效率,ICNet设计了一个多分辨率的图像级联网络。
而BiSeNet基于双边分割网络,分别提取细节特征和语义特征。双边网络是轻量级的,所以推理速度很快。
STDCSeg提出了通道减少的感受野放大的STDC模块,并设计了一个有效的backbone,可以以较低的计算成本加强特征表示。为了消除双分支网络中的冗余计算,STDCSeg以详细的GT指导特征,从而进一步提高了效率。
EspNetv2使用point-wise和depth-wise可分离卷积,以一种计算友好的方式从扩大的感受野中学习特征。
2.3 特征融合模块
特征融合模块常用于语义分割中,主要是用来加强特征表示。除了元素级的求和和串联方法外,研究人员还提出了以下几种方法。
在BiSeNet中,BGA模块采用了element-wise mul方法来融合来自空间分支和上下文分支的特征。
为了使用high-level上下文增强特性,DFANet以stage-wise和subnet-wise的方式融合特征。
为了解决错位问题,SFNet和AlignSeg首先通过CNN模块学习变换偏移,然后将变换偏移应用于网格样本操作,生成细化的特征。SFNet详细地设计了flow alignment module。AlignSeg设计了aligned feature aggregation module和aligned context modeling module。
FaPN通过将变换偏移应用于可变形卷积来解决特征错位问题。
本文方法
3.1 Flexible and Lightweight Decoder
一般来说,编码器利用一系列分成几个阶段的层来提取层次特征。对于从low-level到high-level的特征,通道的数量逐渐增加,特征的空间尺寸逐渐减小。该设计平衡了各阶段的计算成本,保证了编码器的效率。
解码器也有几个阶段,负责融合和上采样特征。虽然特征的空间大小从high-level增加到low-level,但最近的轻量级模型中的解码器在所有level上都保持相同特征通道。因此,low-level阶段的计算成本远远大于high-level的计算成本,这带来了low-level阶段的计算冗余。
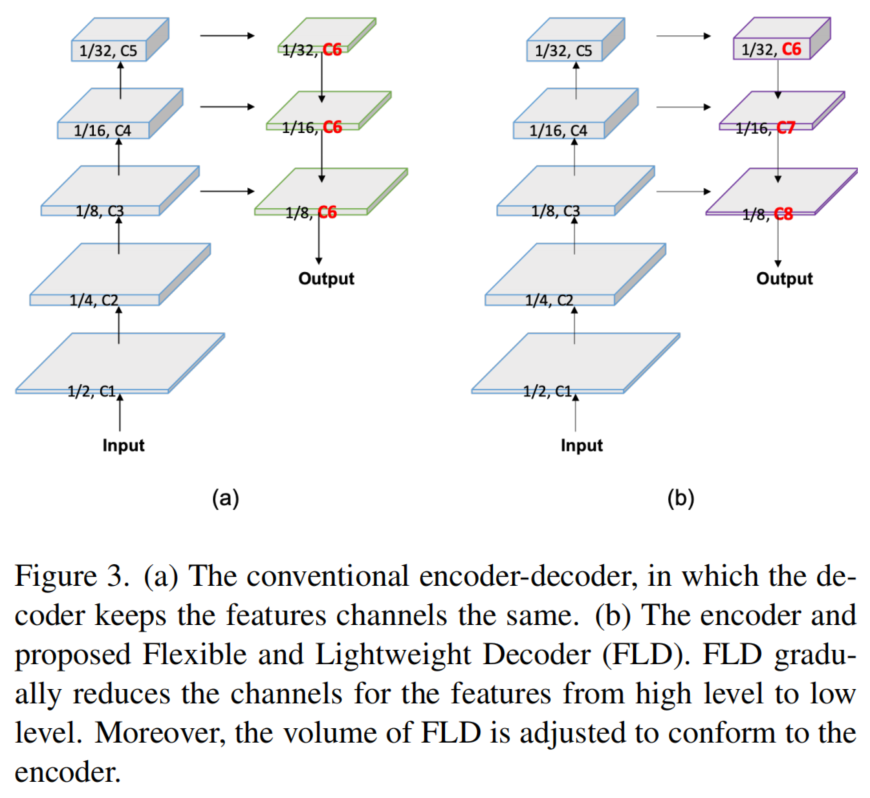
为了提高解码器的效率,本文提出了一种灵活的轻量级解码器(FLD)。如图3所示,FLD逐渐将特征的通道从high-level减少到low-level层次。FLD可以很容易地调整计算成本,以实现编码器和解码器之间更好的平衡。虽然FLD中的特征通道在减少,但实验表明,PP-LiteSeg与其他方法相比,依然具有竞争力的精度。
3.2 Unified Attention Fusion Module
如上所述,融合多层次特征是实现高分割精度的关键。除了element-wise summation和concatenation方法外,研究人员还提出了几种方法,如SFNet、FaPN和AttaNet。在这项工作中提出了一个统一的注意力融合模块(UAFM),它应用通道和空间注意力来丰富融合特征表示。
1、UAFM Framework
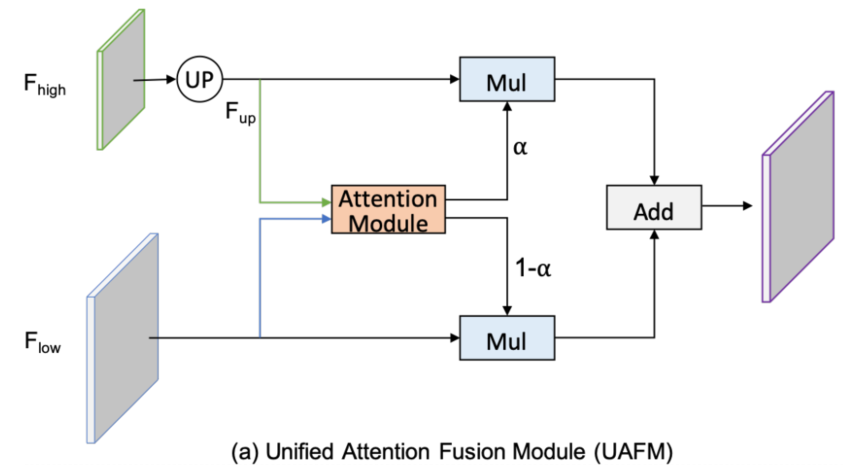
如图4(a)所示,UAFM利用一个注意力模块来产生权重 α \alpha α,并通过Mul和Add操作将输入特性与 α \alpha α相融合。
详细地说,输入特征被表示为 F h i g h F_{high} Fhigh和 F l o w F_{low} Flow。 F h i g h F_{high} Fhigh是深层模块的输出,而 F l o w F_{low} Flow是编码器的对应模块。请注意,它们有相同的通道数量。
UAFM首先利用双线性插值操作将 F h i g h F_{high} Fhigh上采样到 F l o w F_{low} Flow相同大小,而上采样特征记为 F u p F_{up} Fup。然后,注意力模块以 F u p F_{up} Fup和 F l o w F_{low} Flow作为输入,产生权重 α \alpha α。
请注意,注意力模块可以是一个插件,如空间注意力模块、通道注意力模块等。
然后,获得注意力加权后,分别对
F
u
p
F_{up}
Fup和
F
l
o
w
F_{low}
Flow进行element-wise Mul。
最后,UAFM对注意力加权后的特征进行element-wise Add,并输出融合特征。这里将把上述过程表述为公式1:
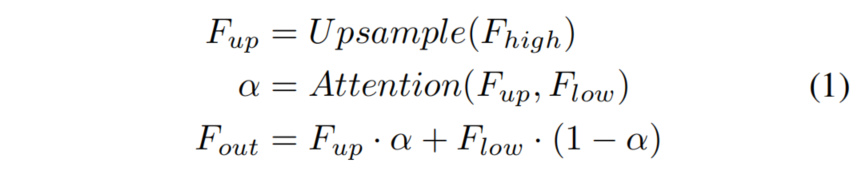
class UAFM(nn.Layer):
"""
The base of Unified Attention Fusion Module.
Args:
x_ch (int): The channel of x tensor, which is the low level feature.
y_ch (int): The channel of y tensor, which is the high level feature.
out_ch (int): The channel of output tensor.
ksize (int, optional): The kernel size of the conv for x tensor. Default: 3.
resize_mode (str, optional): The resize model in unsampling y tensor. Default: bilinear.
"""
def __init__(self, x_ch, y_ch, out_ch, ksize=3, resize_mode='bilinear'):
super().__init__()
self.conv_x = layers.ConvBNReLU(
x_ch, y_ch, kernel_size=ksize, padding=ksize // 2, bias_attr=False)
self.conv_out = layers.ConvBNReLU(
y_ch, out_ch, kernel_size=3, padding=1, bias_attr=False)
self.resize_mode = resize_mode
def check(self, x, y):
assert x.ndim == 4 and y.ndim == 4
x_h, x_w = x.shape[2:]
y_h, y_w = y.shape[2:]
assert x_h >= y_h and x_w >= y_w
def prepare(self, x, y):
x = self.prepare_x(x, y)
y = self.prepare_y(x, y)
return x, y
def prepare_x(self, x, y):
x = self.conv_x(x)
return x
def prepare_y(self, x, y):
y_up = F.interpolate(y, paddle.shape(x)[2:], mode=self.resize_mode)
return y_up
def fuse(self, x, y):
out = x + y
out = self.conv_out(out)
return out
def forward(self, x, y):
"""
Args:
x (Tensor): The low level feature.
y (Tensor): The high level feature.
"""
self.check(x, y)
x, y = self.prepare(x, y)
out = self.fuse(x, y)
return out
2、Spatial Attention Module

空间注意力模块的动机是利用空间间关系来产生一个权重,该权重表示输入特征中每个像素的重要性。如图4(b)所示,给定输入特征,即 F u p ∈ R C × H × W F_{up}∈R^{C×H×W} Fup∈RC×H×W和 F l o w ∈ R C × H × W F_{low}∈R^{C×H×W} Flow∈RC×H×W,首先沿着通道轴进行平均和最大池化操作,生成4个特征,其中维度为 R 1 × H × W R^{1×H×W} R1×H×W。然后,将这4个特征concat到一个特征 F c a t ∈ R 4 × H × W F_{cat}∈R^{4×H×W} Fcat∈R4×H×W上。对于concat的特征,将卷积和sigmoid运算应用于输出 α ∈ R 1 × H × W α∈R^{1×H×W} α∈R1×H×W。空间注意力模块的公式如式2所示:
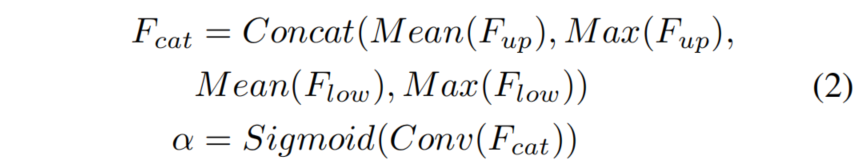
此外,空间注意力模块还可以灵活地实现,例如去除最大池化操作以降低计算成本。
Paddle实现如下:
class UAFM_SpAtten(UAFM):
"""
The UAFM with spatial attention, which uses mean and max values.
Args:
x_ch (int): The channel of x tensor, which is the low level feature.
y_ch (int): The channel of y tensor, which is the high level feature.
out_ch (int): The channel of output tensor.
ksize (int, optional): The kernel size of the conv for x tensor. Default: 3.
resize_mode (str, optional): The resize model in unsampling y tensor. Default: bilinear.
"""
def __init__(self, x_ch, y_ch, out_ch, ksize=3, resize_mode='bilinear'):
super().__init__(x_ch, y_ch, out_ch, ksize, resize_mode)
self.conv_xy_atten = nn.Sequential(
layers.ConvBNReLU(
4, 2, kernel_size=3, padding=1, bias_attr=False),
layers.ConvBN(
2, 1, kernel_size=3, padding=1, bias_attr=False))
def fuse(self, x, y):
"""
Args:
x (Tensor): The low level feature.
y (Tensor): The high level feature.
"""
atten = helper.avg_max_reduce_channel([x, y])
atten = F.sigmoid(self.conv_xy_atten(atten))
out = x * atten + y * (1 - atten)
out = self.conv_out(out)
return out
3、Channel Attention Module

通道注意力模块的关键概念是利用通道间的关系来产生一个权重,这表明了每个通道在输入特征中的重要性。如图4©所示,所提出的通道注意力模块利用平均池化和最大池化操作来压缩输入特征的空间维数。
此过程使用维度 R C × 1 × 1 R^{C×1×1} RC×1×1生成4个特性。然后,它将这4个特征沿着通道轴连接起来,并执行卷积和sigmoid运算,以产生一个权重 α ∈ R C × 1 × 1 α∈R^{C×1×1} α∈RC×1×1。简而言之,通道注意力模块的过程可以表述为公式3:

Paddle实现如下:
class UAFM_ChAtten(UAFM):
"""
The UAFM with channel attention, which uses mean and max values.
Args:
x_ch (int): The channel of x tensor, which is the low level feature.
y_ch (int): The channel of y tensor, which is the high level feature.
out_ch (int): The channel of output tensor.
ksize (int, optional): The kernel size of the conv for x tensor. Default: 3.
resize_mode (str, optional): The resize model in unsampling y tensor. Default: bilinear.
"""
def __init__(self, x_ch, y_ch, out_ch, ksize=3, resize_mode='bilinear'):
super().__init__(x_ch, y_ch, out_ch, ksize, resize_mode)
self.conv_xy_atten = nn.Sequential(
layers.ConvBNAct(
4 * y_ch,
y_ch // 2,
kernel_size=1,
bias_attr=False,
act_type="leakyrelu"),
layers.ConvBN(
y_ch // 2, y_ch, kernel_size=1, bias_attr=False))
def fuse(self, x, y):
"""
Args:
x (Tensor): The low level feature.
y (Tensor): The high level feature.
"""
atten = helper.avg_max_reduce_hw([x, y], self.training)
atten = F.sigmoid(self.conv_xy_atten(atten))
out = x * atten + y * (1 - atten)
out = self.conv_out(out)
return out
3.3 Simple Pyramid Pooling Module
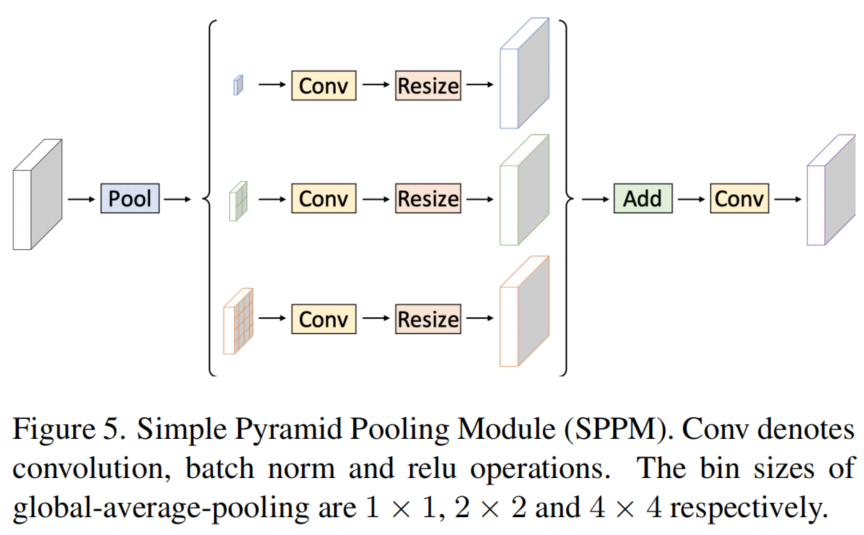
如图5所示,提出了一个简单的金字塔池化模块(SPPM)。
首先利用金字塔池化模块来融合输入特征(金字塔池化模块有3个全局平均池化操作,bin大小分别为1×1、2×2和4×4)。
然后,在输出特征之后,再进行卷积和上采样操作。对于卷积操作,kernel大小为1×1,输出通道小于输入通道。
最后,上采样的特征,并应用卷积运算来产生细化的特征。
与原始的PPM相比,SPPM减少了中间通道和输出通道,删除了shortcut,并用add操作替换了cat操作。因此,SPPM更有效,也更适合用于实时模型。
Paddle实现如下:
class PPContextModule(nn.Layer):
"""
Simple Context module.
Args:
in_channels (int): The number of input channels to pyramid pooling module.
inter_channels (int): The number of inter channels to pyramid pooling module.
out_channels (int): The number of output channels after pyramid pooling module.
bin_sizes (tuple, optional): The out size of pooled feature maps. Default: (1, 3).
align_corners (bool): An argument of F.interpolate. It should be set to False
when the output size of feature is even, e.g. 1024x512, otherwise it is True, e.g. 769x769.
"""
def __init__(self,
in_channels,
inter_channels,
out_channels,
bin_sizes,
align_corners=False):
super().__init__()
self.stages = nn.LayerList([
self._make_stage(in_channels, inter_channels, size)
for size in bin_sizes
])
self.conv_out = layers.ConvBNReLU(
in_channels=inter_channels,
out_channels=out_channels,
kernel_size=3,
padding=1)
self.align_corners = align_corners
def _make_stage(self, in_channels, out_channels, size):
prior = nn.AdaptiveAvgPool2D(output_size=size)
conv = layers.ConvBNReLU(
in_channels=in_channels, out_channels=out_channels, kernel_size=1)
return nn.Sequential(prior, conv)
def forward(self, input):
out = None
input_shape = paddle.shape(input)[2:]
for stage in self.stages:
x = stage(input)
x = F.interpolate(
x,
input_shape,
mode='bilinear',
align_corners=self.align_corners)
if out is None:
out = x
else:
out += x
out = self.conv_out(out)
return out
3.4 模型架构
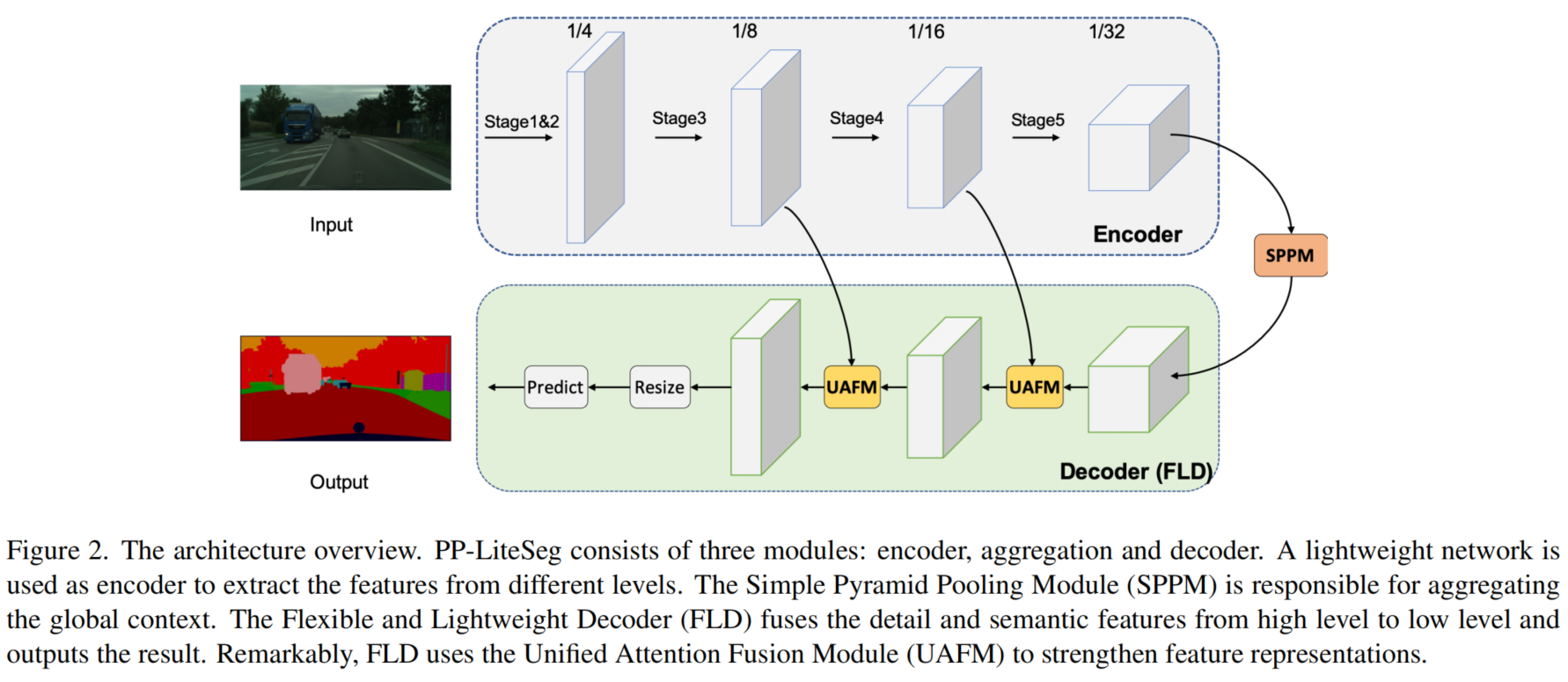
所提的PP-LiteSeg的体系结构如上图所示。
PP-LiteSeg主要由3个模块组成:encoder, aggregation和decoder。
首先,给定一个输入图像,PP-Lite利用一个通用的轻量级网络作为编码器来提取层次特征。

选择STDCNet是因为其出色的性能。STDCNet有5个阶段,每个阶段的stride=2,所以最终的特征大小是输入图像的1/32。
如表1所示,提供了2个版本的PP-LiteSeg,即PP-LiteSeg-T和PP-LiteSeg-B,其中的编码器分别为STDC1和STDC2。PPLiteSeg-B具有较高的分割精度,而PP-LiteSeg-T的推理速度更快。
值得注意的是,将SSLD方法应用于编码器的训练,得到了增强的预训练权重,有利于分割训练的收敛。
其次,PP-LiteSeg采用SPPM对随机依赖进行建模。SPPM以编码器的输出特征作为输入,生成一个包含全局上下文信息的特征。
最后,PP-LiteSeg利用提出的FLD逐步融合多层次特征并输出得到的图像。
FLD由2个UAFM和一个分割头组成。为了提高效率,在UAFM中采用了空间注意力模块。
每个UAFM以2个特征作为输入,即由编码器各阶段提取的low-level特征,由SPPM或更深的融合模块生成的high-level特征。后者的UAFM输出融合的特征,下采样比为1/8。
在分割head中执行Conv-BN-Relu操作,将1/8个下采样特征的通道减少到类的数量。采用上采样操作将特征大小扩展到输入图像大小,并采用argmax操作预测每个像素的标签。并采用Online Hard Example Mining交叉熵损失对模型进行了优化。
损失函数的Paddle实现如下:
import paddle
from paddle import nn
import paddle.nn.functional as F
from paddleseg.cvlibs import manager
@manager.LOSSES.add_component
class OhemCrossEntropyLoss(nn.Layer):
"""
Implements the ohem cross entropy loss function.
Args:
thresh (float, optional): The threshold of ohem. Default: 0.7.
min_kept (int, optional): The min number to keep in loss computation. Default: 10000.
ignore_index (int64, optional): Specifies a target value that is ignored
and does not contribute to the input gradient. Default ``255``.
"""
def __init__(self, thresh=0.7, min_kept=10000, ignore_index=255):
super(OhemCrossEntropyLoss, self).__init__()
self.thresh = thresh
self.min_kept = min_kept
self.ignore_index = ignore_index
self.EPS = 1e-5
def forward(self, logit, label):
"""
Forward computation.
Args:
logit (Tensor): Logit tensor, the data type is float32, float64. Shape is
(N, C), where C is number of classes, and if shape is more than 2D, this
is (N, C, D1, D2,..., Dk), k >= 1.
label (Tensor): Label tensor, the data type is int64. Shape is (N), where each
value is 0 <= label[i] <= C-1, and if shape is more than 2D, this is
(N, D1, D2,..., Dk), k >= 1.
"""
if len(label.shape) != len(logit.shape):
label = paddle.unsqueeze(label, 1)
# get the label after ohem
n, c, h, w = logit.shape
label = label.reshape((-1, ))
valid_mask = (label != self.ignore_index).astype('int64')
num_valid = valid_mask.sum()
label = label * valid_mask
prob = F.softmax(logit, axis=1)
prob = prob.transpose((1, 0, 2, 3)).reshape((c, -1))
if self.min_kept < num_valid and num_valid > 0:
# let the value which ignored greater than 1
prob = prob + (1 - valid_mask)
# get the prob of relevant label
label_onehot = F.one_hot(label, c)
label_onehot = label_onehot.transpose((1, 0))
prob = prob * label_onehot
prob = paddle.sum(prob, axis=0)
threshold = self.thresh
if self.min_kept > 0:
index = prob.argsort()
threshold_index = index[min(len(index), self.min_kept) - 1]
threshold_index = int(threshold_index.numpy()[0])
if prob[threshold_index] > self.thresh:
threshold = prob[threshold_index]
kept_mask = (prob < threshold).astype('int64')
label = label * kept_mask
valid_mask = valid_mask * kept_mask
# make the invalid region as ignore
label = label + (1 - valid_mask) * self.ignore_index
label = label.reshape((n, 1, h, w))
valid_mask = valid_mask.reshape((n, 1, h, w)).astype('float32')
loss = F.softmax_with_cross_entropy(
logit, label, ignore_index=self.ignore_index, axis=1)
loss = loss * valid_mask
avg_loss = paddle.mean(loss) / (paddle.mean(valid_mask) + self.EPS)
label.stop_gradient = True
valid_mask.stop_gradient = True
return avg_loss
实验
4.1 消融实验
通过消融实验,验证了所提模块的有效性。实验在比较中选择PP-LiteSeg-B2,并使用相同的训练和推理配置。Baseline模型为无该模块的PP-LiteSeg-B2,而解码器中的特征通道数为96个,融合方法为 element-wise summation。

通过表3可以发现,PP-LiteSeg-B2中的FLD使mIoU提高了0.17%。添加SPPM和UAFM也提高了分割精度,而推理速度略有降低。基于提出的3个模块,PP-LiteSeg-B2以102.6FPS速度达到78.21mIoU。mIoU与Baseline模型相比提高了0.71%。
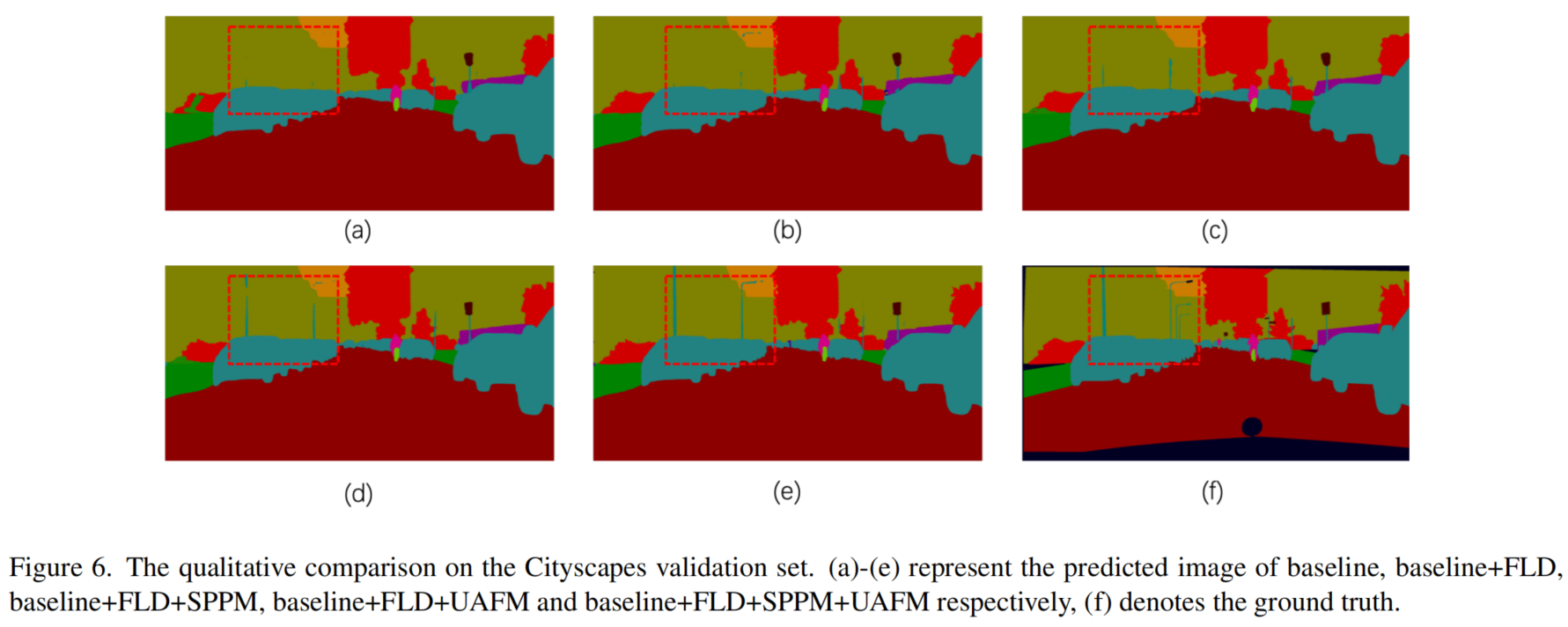
图6提供了定性的比较。可以观察到,当逐个添加FLD、SPPM和UAFM时,预测的图像更符合GT。总之,本文提出的模块对于语义分割是有效的。
4.2 Cityscapes
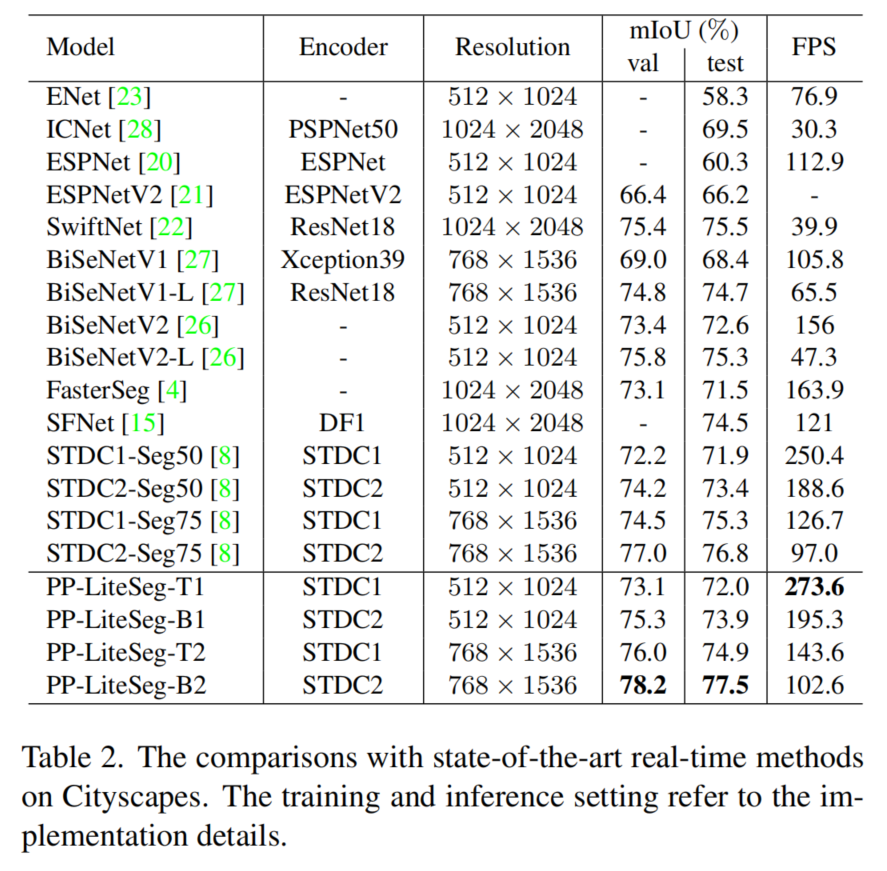
表2给出了各种方法的模型信息、输入分辨率、mIoU和FPS。图1提供了分割精度和推理速度的直观比较。
实验结果表明,所提出的PP-LiteSeg方法在精度和速度之间实现了最先进的权衡。
具体来说,PP-LiteSeg-T1以273.6FPS速度达到了72.0%的mIoU,这意味着最快的推理速度和竞争精度。
PPLiteSeg-B2的分辨率为768×1536,达到了最好的精度,即验证集的78.2%mIoU,测试集的77.5%mIoU。此外,使用与STDC-Seg相同的编码器和输入分辨率,PPLiteSeg显示出更好的性能。
4.3 CamVid
为了进一步证明PP-LiteSeg的能力,作者还在CamVid数据集上进行了实验。与其他工作类似,训练和推理的输入分辨率是960×720。
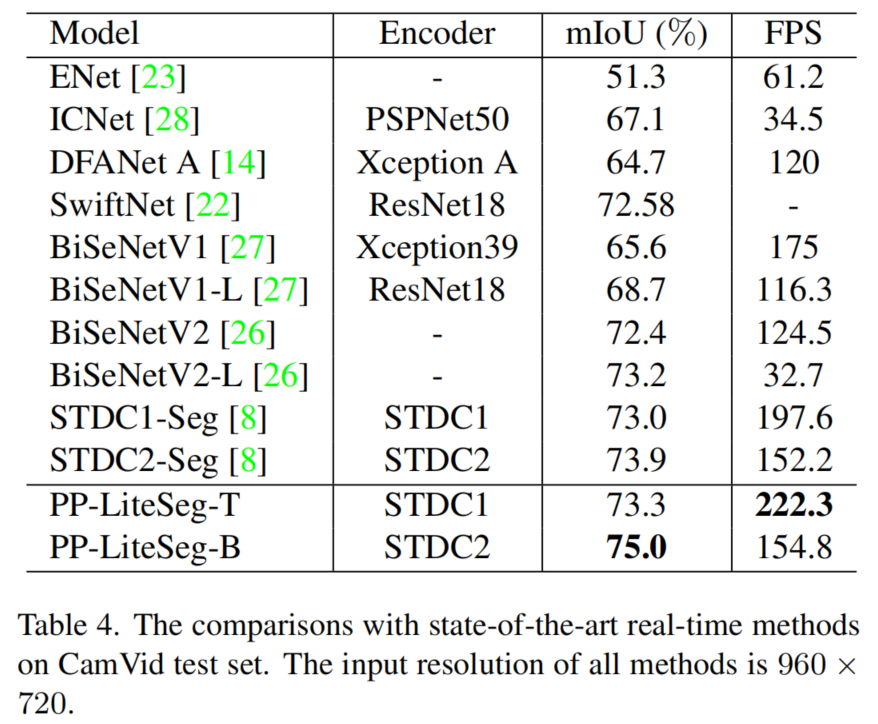
如表4所示,PP-LiteSeg-T达到222.3FPS,比其他方法快12.5%以上。PP-LiteSeg-B的精度最好(75.0%mIoU/154.8FPS)。
总的来说,比较显示PP-LiteSeg在Camvid上实现了精度和速度之间的最先进的权衡。














 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









