






训练出来的模型最终都需要进行工业部署,现今部署方案有很多,tensorflow和pytorch官方也都有发布,比如现在pytorch有自己的Libtorch进行部署【可以看我另一篇文章有讲利用Libtorch部署分类网络】。同时英伟达也推出了tensorrt进行模型部署,同时可以进行模型加速,这篇文章就是在学习利用tensorrt进行YOLOv5部署记录【需要有C/C++的基础,我也在学这一部分】
【权重在文末百度云自取】
目录
环境说明
系统:windows 10
VS2017
TensorRT-8.2.4.2
CUDA 10.2
显卡1650
看自己cuda的版本可以打开cmd,输入nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Wed_Oct_23_19:32:27_Pacific_Daylight_Time_2019
Cuda compilation tools, release 10.2, V10.2.89关于cuda的安装网上有很多,这里不再说明【但要注意版本的对应,还有装CUDA10.2一定要装上官网提供的两个补丁!】
可以一个电脑上装多个版本的cuda,比如我的电脑就是装了cuda10.0和cuda10.2,只需要切换环境变量即可。
TensorRT下载与配置
TensorRT链接:https://developer.nvidia.com/nvidia-tensorrt-8x-download
进入官网应该如果没有账号就注册一个,登录以后才可以下载,会有如下界面
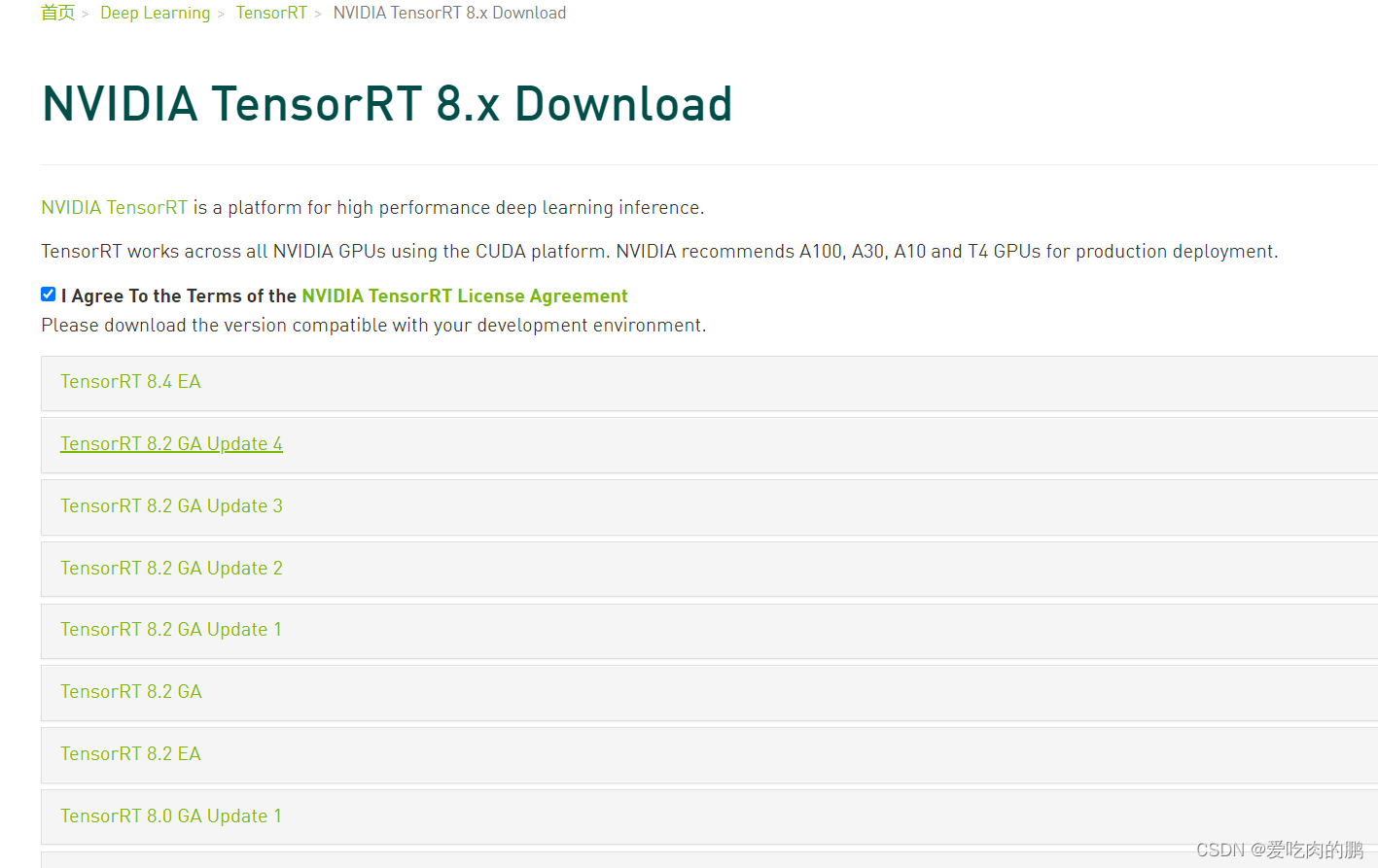
选择你想要的下载的版本【注意和自己的cuda对应】
比如我下载的版本为8.2.4.2,cuda版本10.2,cudnn8.2
![]()
下载好以后解压
1. 将 TensorRT-8.2.4.2\include中头文件 copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\include
2. 将TensorRT-8.2.4.2\lib 中所有lib文件 copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64
3. 将TensorRT-8.2.4.2\lib 中所有dll文件copy 到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin
VS2017配置
用VS2017测试一下Tensorrt是否安装成功
打开【TensorRT-8.2.4.2\samples\sampleMNIST\sample_mnist.sln】
打开项目后,右键项目》属性》配置属性》常规,检查下我画红框的地方【VS2015不一样】
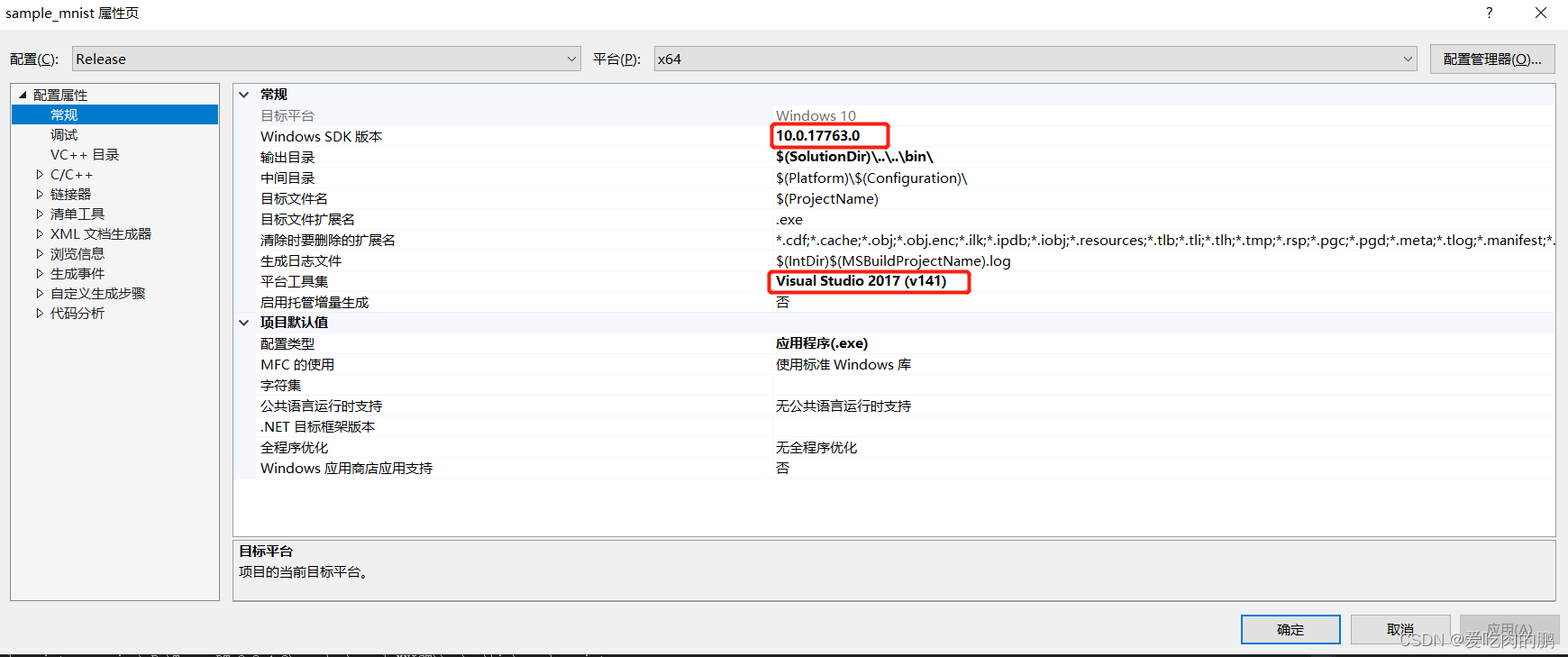
然后点VC++目录,在右侧常规中的可执行文件目录中,将TensorRT中的lib库文件路径填写进去。填写进去以后要点击右下角的应用。
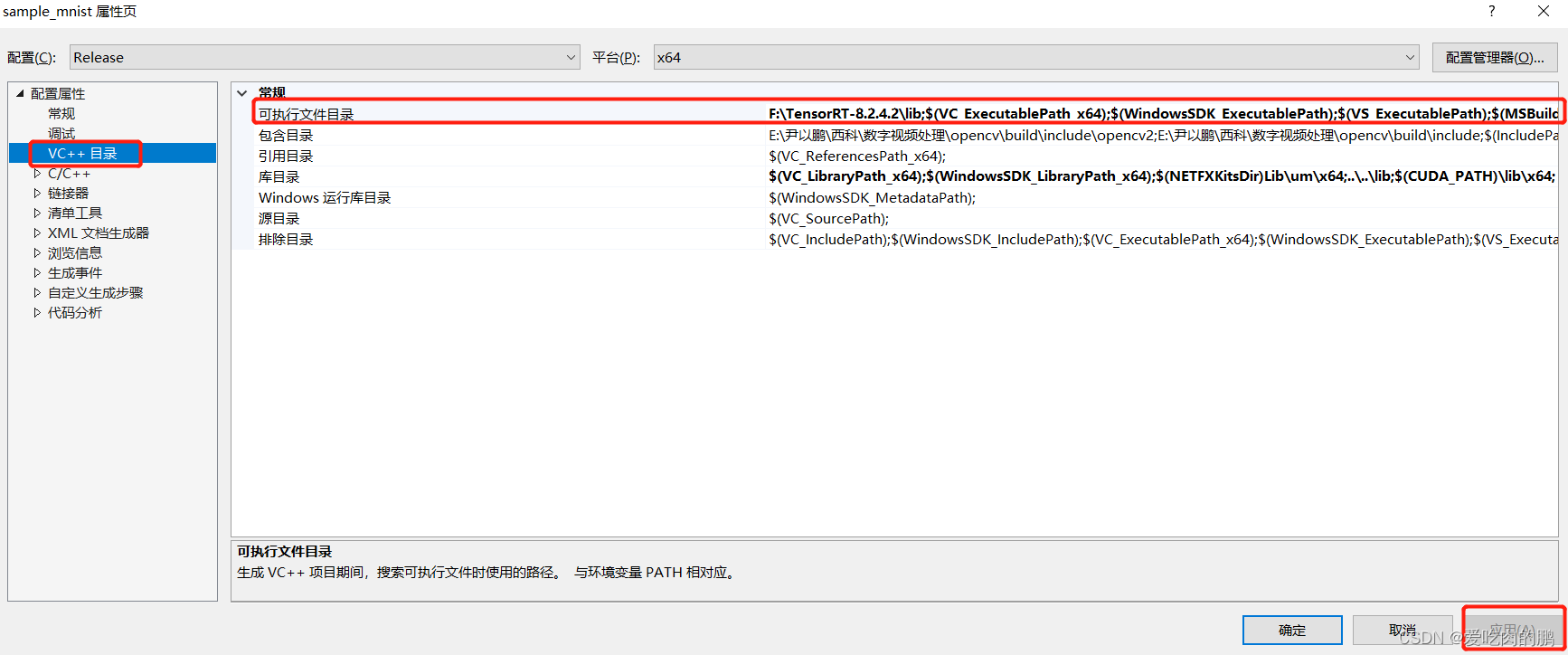
再点C/C++,右侧的附加包含目录,将tensorrt的bin目录路径填写上去,然后点右下角应用
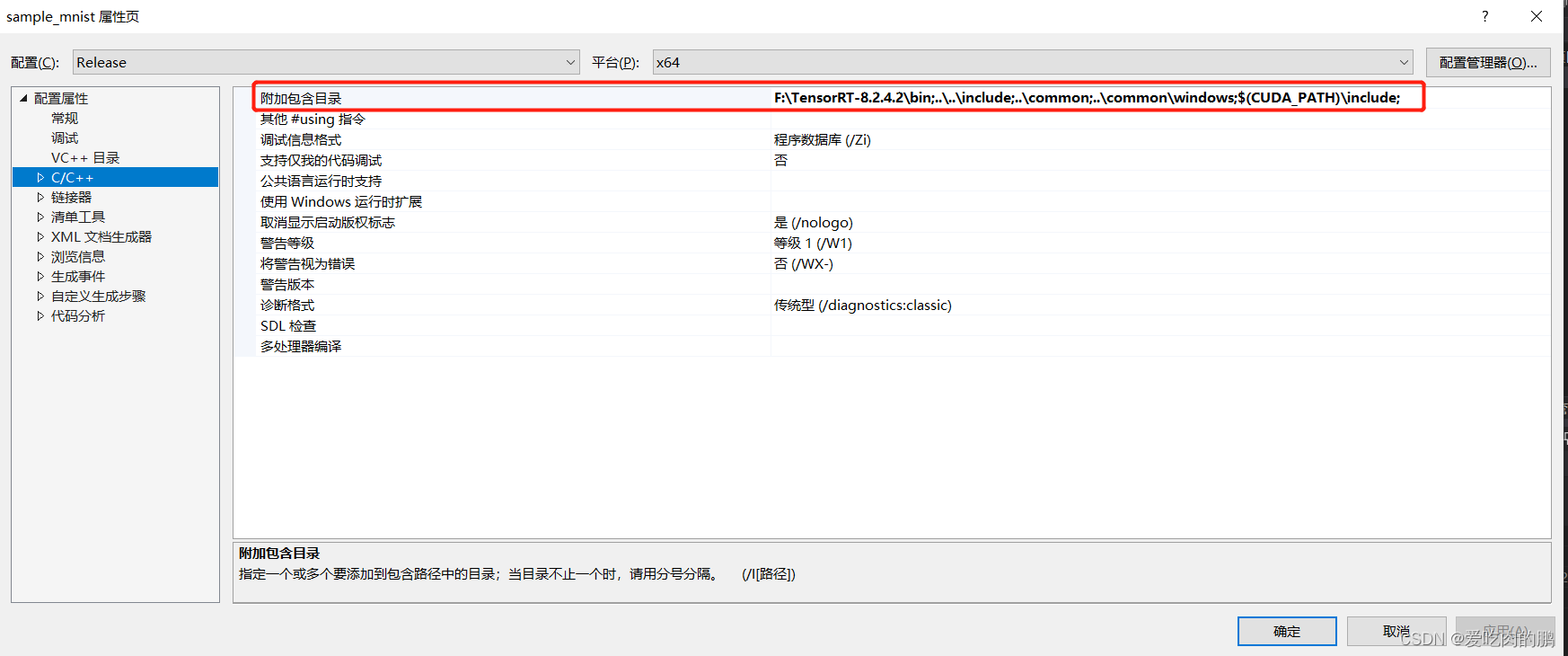
再点击链接器》输入,在右侧的附加依赖项中将TensorRT下lib库中的.lib放进去 然后点击应用。
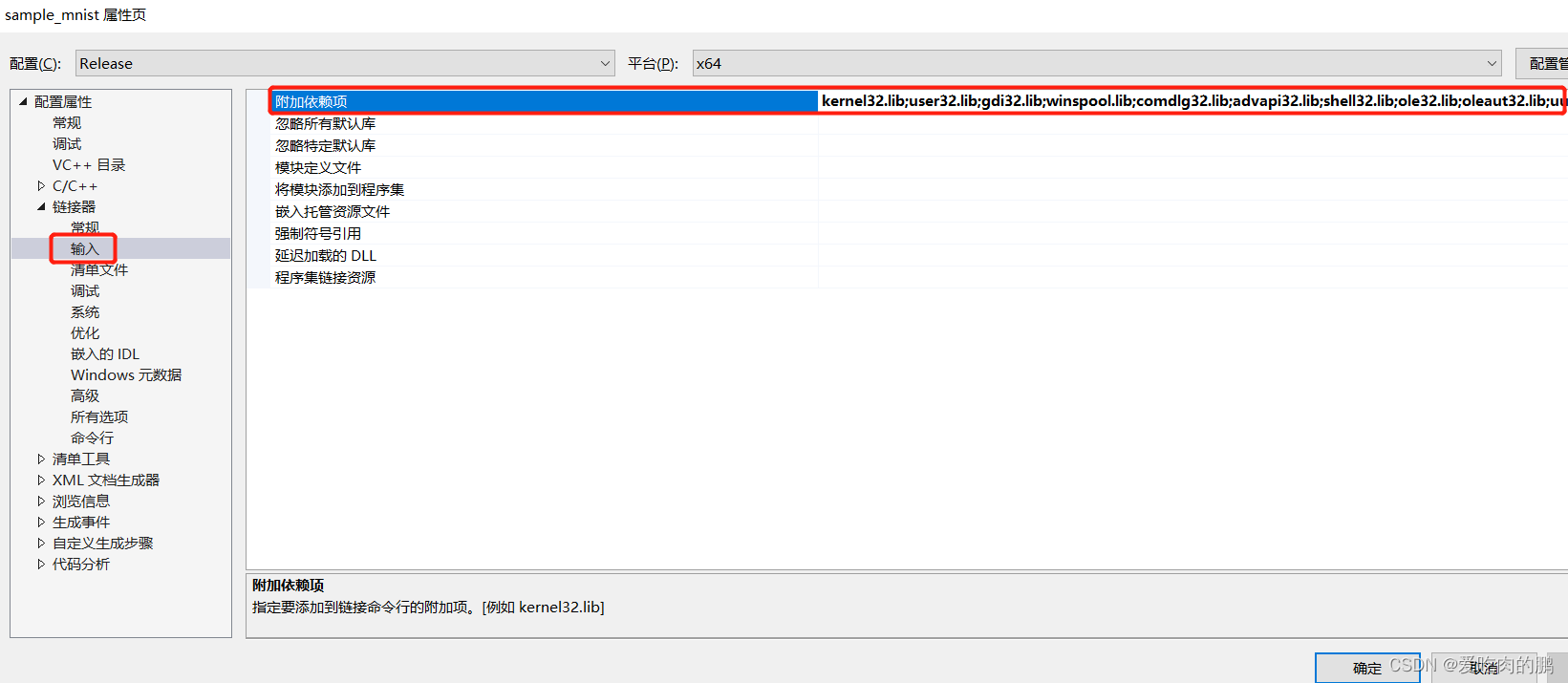
我的附加依赖项中包含以下lib文件【可以参考以下】,就把你lib文件下的lib文件全放进来,其中cudnn.lib,cublas.lib,cudart.lib,nvrtc.lib,是C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64 目录下的
nvinfer.lib
nvinfer_plugin.lib
nvonnxparser.lib
nvparsers.lib
cudnn.lib
cublas.lib
cudart.lib
nvrtc.lib
全部设置好,回到VS界面中,右键项目生成
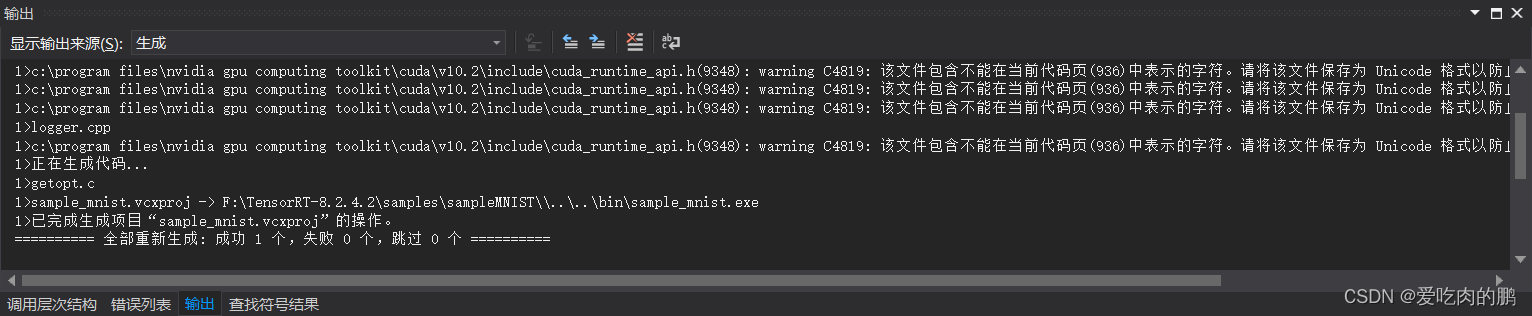
生成项目以后,会在F:\TensorRT-8.2.4.2\bin 目录下生成一个sample_mnist.exe文件,然后用cmd进行该路径下,运行这个exe文件,出现以下案例就说明安装成功了。
&&&& RUNNING TensorRT.sample_mnist [TensorRT v8204] # F:\TensorRT-8.2.4.2\bin\sample_mnist.exe
[05/27/2022-15:16:25] [I] Building and running a GPU inference engine for MNIST
[05/27/2022-15:16:26] [I] [TRT] [MemUsageChange] Init CUDA: CPU +396, GPU +0, now: CPU 3492, GPU 890 (MiB)
[05/27/2022-15:16:27] [I] [TRT] [MemUsageSnapshot] Begin constructing builder kernel library: CPU 3516 MiB, GPU 890 MiB
[05/27/2022-15:16:27] [I] [TRT] [MemUsageSnapshot] End constructing builder kernel library: CPU 3623 MiB, GPU 926 MiB
[05/27/2022-15:16:28] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +193, GPU +70, now: CPU 3800, GPU 996 (MiB)
[05/27/2022-15:16:29] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +178, GPU +86, now: CPU 3978, GPU 1082 (MiB)
[05/27/2022-15:16:29] [W] [TRT] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
[05/27/2022-15:16:29] [I] [TRT] Local timing cache in use. Profiling results in this builder pass will not be stored.
[05/27/2022-15:16:43] [I] [TRT] Some tactics do not have sufficient workspace memory to run. Increasing workspace size may increase performance, please check verbose output.
[05/27/2022-15:16:45] [I] [TRT] Detected 1 inputs and 1 output network tensors.
[05/27/2022-15:16:45] [I] [TRT] Total Host Persistent Memory: 5440
[05/27/2022-15:16:45] [I] [TRT] Total Device Persistent Memory: 0
[05/27/2022-15:16:45] [I] [TRT] Total Scratch Memory: 0
[05/27/2022-15:16:45] [I] [TRT] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 1 MiB, GPU 16 MiB
[05/27/2022-15:16:45] [I] [TRT] [BlockAssignment] Algorithm ShiftNTopDown took 0.0466ms to assign 3 blocks to 8 nodes requiring 57857 bytes.
[05/27/2022-15:16:45] [I] [TRT] Total Activation Memory: 57857
[05/27/2022-15:16:45] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +8, now: CPU 4472, GPU 1250 (MiB)
[05/27/2022-15:16:45] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +0, GPU +10, now: CPU 4472, GPU 1260 (MiB)
[05/27/2022-15:16:45] [W] [TRT] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
[05/27/2022-15:16:45] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +0, GPU +4, now: CPU 0, GPU 4 (MiB)
[05/27/2022-15:16:45] [I] [TRT] [MemUsageChange] Init CUDA: CPU +0, GPU +0, now: CPU 4398, GPU 1164 (MiB)
[05/27/2022-15:16:45] [I] [TRT] Loaded engine size: 1 MiB
[05/27/2022-15:16:46] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +59, GPU +66, now: CPU 4457, GPU 1232 (MiB)
[05/27/2022-15:16:46] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +3, GPU +8, now: CPU 4460, GPU 1240 (MiB)
[05/27/2022-15:16:46] [W] [TRT] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
[05/27/2022-15:16:46] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +1, now: CPU 0, GPU 1 (MiB)
[05/27/2022-15:16:46] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +79, GPU +66, now: CPU 4372, GPU 1198 (MiB)
[05/27/2022-15:16:46] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +2, GPU +8, now: CPU 4374, GPU 1206 (MiB)
[05/27/2022-15:16:46] [W] [TRT] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
[05/27/2022-15:16:46] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +0, now: CPU 0, GPU 1 (MiB)
[05/27/2022-15:16:46] [I] Input:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@.*@@@@@@@@@@
@@@@@@@@@@@@@@@@.=@@@@@@@@@@
@@@@@@@@@@@@+@@@.=@@@@@@@@@@
@@@@@@@@@@@% #@@.=@@@@@@@@@@
@@@@@@@@@@@% #@@.=@@@@@@@@@@
@@@@@@@@@@@+ *@@:-@@@@@@@@@@
@@@@@@@@@@@= *@@= @@@@@@@@@@
@@@@@@@@@@@. #@@= @@@@@@@@@@
@@@@@@@@@@= =++.-@@@@@@@@@@
@@@@@@@@@@ =@@@@@@@@@@
@@@@@@@@@@ :*## =@@@@@@@@@@
@@@@@@@@@@:*@@@% =@@@@@@@@@@
@@@@@@@@@@@@@@@% =@@@@@@@@@@
@@@@@@@@@@@@@@@# =@@@@@@@@@@
@@@@@@@@@@@@@@@# =@@@@@@@@@@
@@@@@@@@@@@@@@@* *@@@@@@@@@@
@@@@@@@@@@@@@@@= #@@@@@@@@@@
@@@@@@@@@@@@@@@= #@@@@@@@@@@
@@@@@@@@@@@@@@@=.@@@@@@@@@@@
@@@@@@@@@@@@@@@++@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
[05/27/2022-15:16:46] [I] Output:
0:
1:
2:
3:
4: **********
5:
6:
7:
8:
9:
&&&& PASSED TensorRT.sample_mnist [TensorRT v8204] # F:\TensorRT-8.2.4.2\bin\sample_mnist.exe如果运行exe报错,比如以下错误
[ltWrapper.cpp::nvinfer1::rt::CublasLtWrapper::setupHeuristic::327] Error Code 2: Internal Error (Assertion cublasStatus == CUBLAS_STATUS_SUCCESS failed. )
[01/19/2022-11:26:08] [E] [TRT] 2: [builder.cpp::nvinfer1::builder::Builder::buildSerializedNetwork::609] Error Code 2: Internal Error (Assertion enginePtr != nullptr failed. )
这可能是cuda10.2和Tensorrt兼容问题,需要安装cuda10.2补丁包(官网有),如果你确定已经安装了,可以再重新生成一下项目再试试。
YOLOV5 部署
针对YOLOv5 6.0版本进行部署
这部分本文参考自:
【YOLOv5 Tensorrt Python/C++部署_一笑奈何LHY的博客-CSDN博客_c++部署 python】
以yolov5s.pt为例,下载yolov5 6.0 和上述链接中的代码到本地:
根据基于上述参考链接中的代码,本项目添加了视频检测功能,可替换自己的类。同时为了可以读取类的txt文件,在项目中添加了一个获得类的函数
std::vector<std::string> get_classes(std::string &path)
{
std::vector<std::string> classes_name;
std::ifstream infile(path);
if (infile.is_open())
{
std::string line;
while (getline(infile,line))
{
classes_name.emplace_back(line);
}
}
return classes_name;
}git clone -b v6.0 https://github.com/ultralytics/yolov5.git
https://github.com/YINYIPENG-EN/YOLOv5TensorRT.git
生成wts模型
将yolov5s.pt 文件放到yolov5文件夹下
运行:
-w参数为输入pt权重模型路径,-o参数为输出wts模型的路径。将会在当前文件夹下生成yolov5s.wts文件,这个文件是用来之后转换成tensorrt的序列化模型
python gen_wts.py -w yolov5s.pt -o yolov5s.wts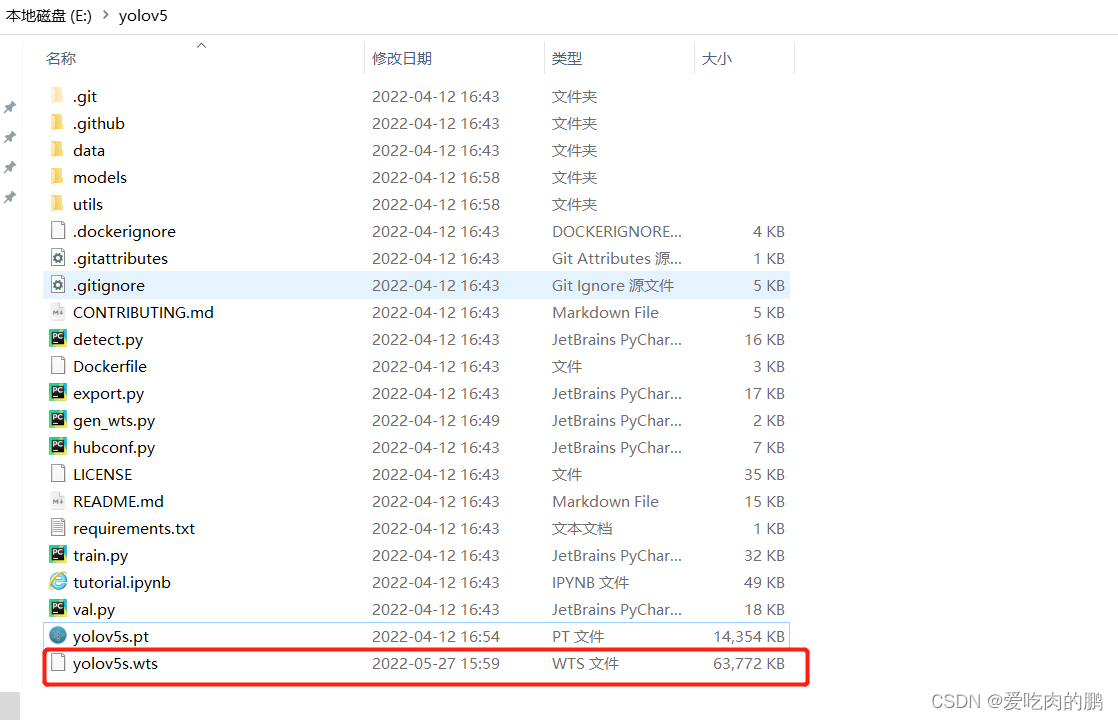
CMakeLists文件配置
这里默认你的Opencv已经安装好了
打开之前下载的YOLOv5TensorRT这个文件,修改CMakeLists.txt文件。修改Opencv、Tensorrt、dirent.h的目录。注意这三个文件必须填写绝对路径!
注:其中dirent.h在YOLOv5TensorRT/include/下,修改arch=compute_75;code=sm_75【因为我用的是英伟达1650,这个填写的是显卡算力,根据自己的显卡去修改,可参考:CUDA GPU | NVIDIA Developer】
我的CMakeLists.txt如下
cmake_minimum_required(VERSION 2.6)
project(yolov5)
#change to your own path
##################################################
set(OpenCV_DIR "F:\\opencv\\opencv\\build")
set(TRT_DIR "F:\\TensorRT-8.2.4.2")
set(Dirent_INCLUDE_DIRS "E:\\YOLOv5TensorRT\\include")
##################################################
add_definitions(-std=c++11)
add_definitions(-DAPI_EXPORTS)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
set(THREADS_PREFER_PTHREAD_FLAG ON)
find_package(Threads)
# setup CUDA
find_package(CUDA 10.2 REQUIRED)
message(STATUS " libraries: ${CUDA_LIBRARIES}")
message(STATUS " include path: ${CUDA_INCLUDE_DIRS}")
include_directories(${CUDA_INCLUDE_DIRS})
include_directories(${Dirent_INCLUDE_DIRS})
#change to your GPU own compute_XX
###########################################################################################
set(CUDA_NVCC_FLAGS ${CUDA_NVCC_FLAGS};-std=c++11;-g;-G;-gencode;arch=compute_75;code=sm_75)
###########################################################################################
####
enable_language(CUDA) # add this line, then no need to setup cuda path in vs
####
include_directories(${PROJECT_SOURCE_DIR}/include)
include_directories(${TRT_DIR}\\include)
# -D_MWAITXINTRIN_H_INCLUDED for solving error: identifier "__builtin_ia32_mwaitx" is undefined
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -Ofast -D_MWAITXINTRIN_H_INCLUDED")
# setup opencv
find_package(OpenCV QUIET
NO_MODULE
NO_DEFAULT_PATH
NO_CMAKE_PATH
NO_CMAKE_ENVIRONMENT_PATH
NO_SYSTEM_ENVIRONMENT_PATH
NO_CMAKE_PACKAGE_REGISTRY
NO_CMAKE_BUILDS_PATH
NO_CMAKE_SYSTEM_PATH
NO_CMAKE_SYSTEM_PACKAGE_REGISTRY
)
message(STATUS "OpenCV library status:")
message(STATUS " version: ${OpenCV_VERSION}")
message(STATUS " libraries: ${OpenCV_LIBS}")
message(STATUS " include path: ${OpenCV_INCLUDE_DIRS}")
include_directories(${OpenCV_INCLUDE_DIRS})
link_directories(${TRT_DIR}\\lib)
add_executable(yolov5 ${PROJECT_SOURCE_DIR}/yolov5.cpp ${PROJECT_SOURCE_DIR}/yololayer.cu ${PROJECT_SOURCE_DIR}/yololayer.h ${PROJECT_SOURCE_DIR}/preprocess.cu)
target_link_libraries(yolov5 "nvinfer" "nvinfer_plugin")
target_link_libraries(yolov5 ${OpenCV_LIBS})
target_link_libraries(yolov5 ${CUDA_LIBRARIES})
target_link_libraries(yolov5 Threads::Threads)
运行Cmake
在YOLOv5TensorRT/下建一个build文件
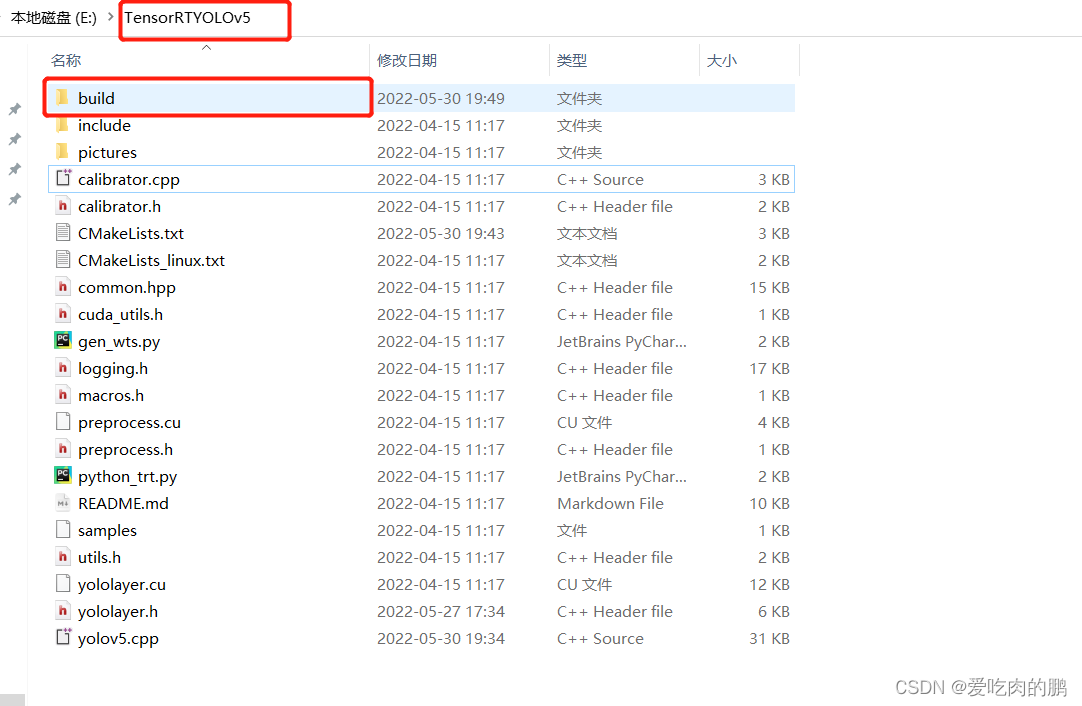
打开CMake,代码为YOLOv5TensorRT,build目录为刚才新建的build路径
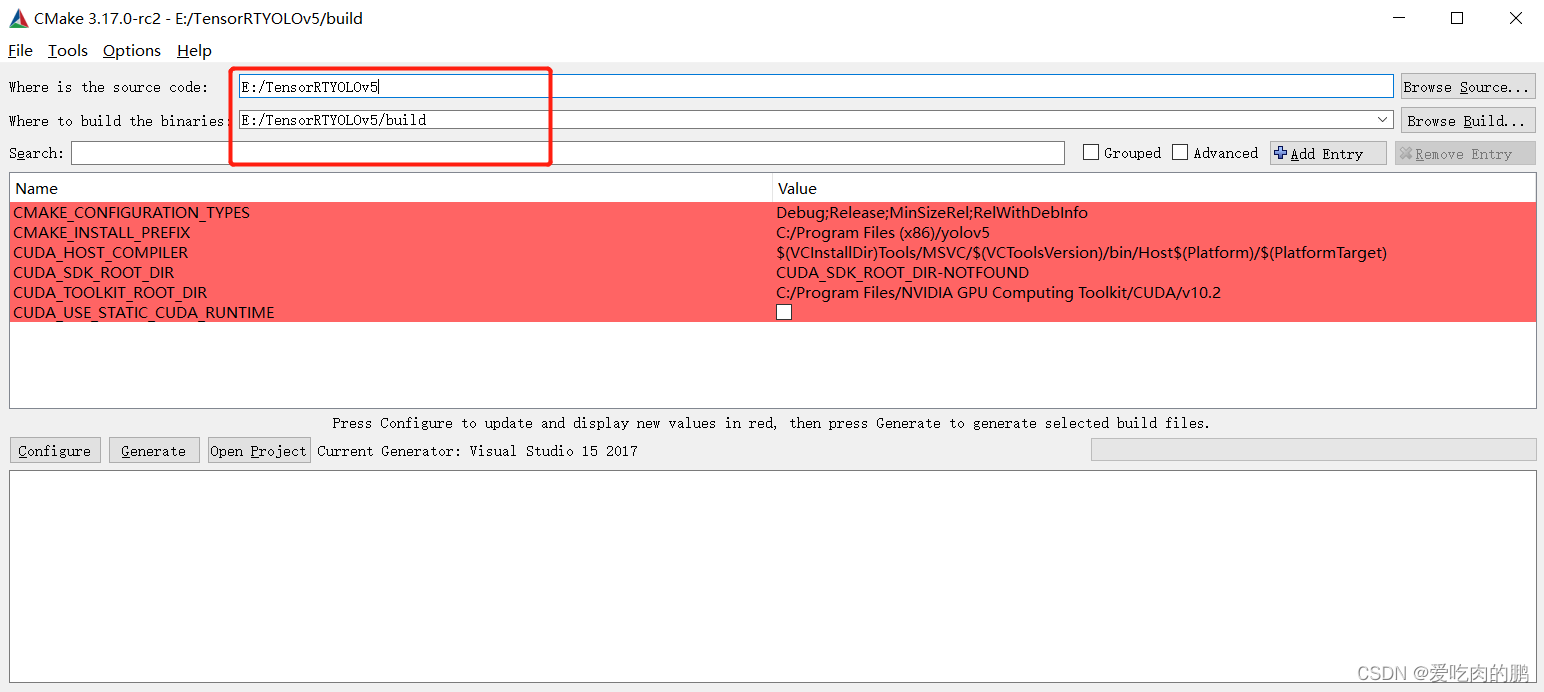
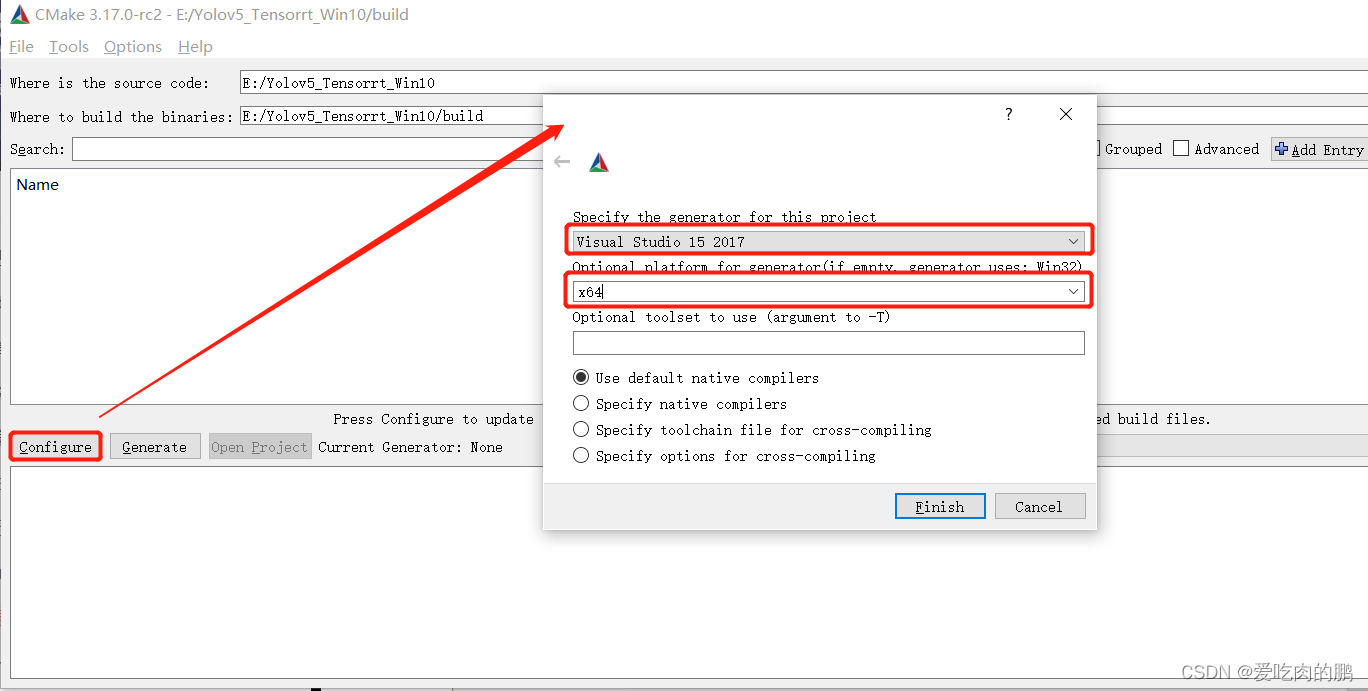
然后点击Configure(下图中的路径还是写的Yolov5_Tensorrt_Win10是老项目,因为添加了东西,其实已经换成了YOLOv5TensorRT和YOLOv5TensorRT/build )
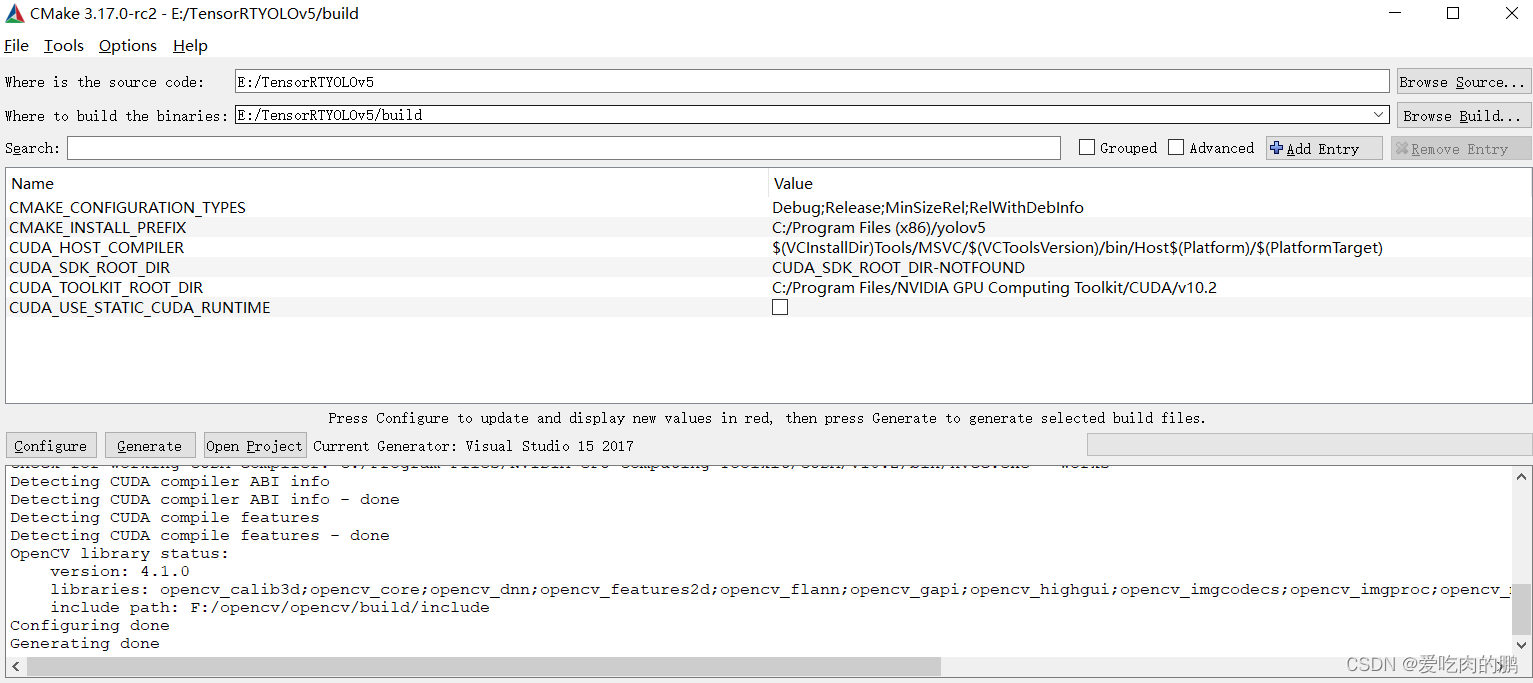
运行完以后会出现以下界面,显示配置完成,点击Generate 在点击open Project会自动打开VS
有时候会提升找不到cuda,检查一下路径对不对。【有时候Cmake的时候有各种问题,欢迎大家把遇到的问题和解决办法留言,方便大家一起解决学习】
编译
进入:E:\YOLOv5TensorRT\build ,打开yolov5.sln 项目文件
然后依次打开项目中的yolov5/Header Files/yololayer.h,可以修改红色框中的输入大小和类的数量。
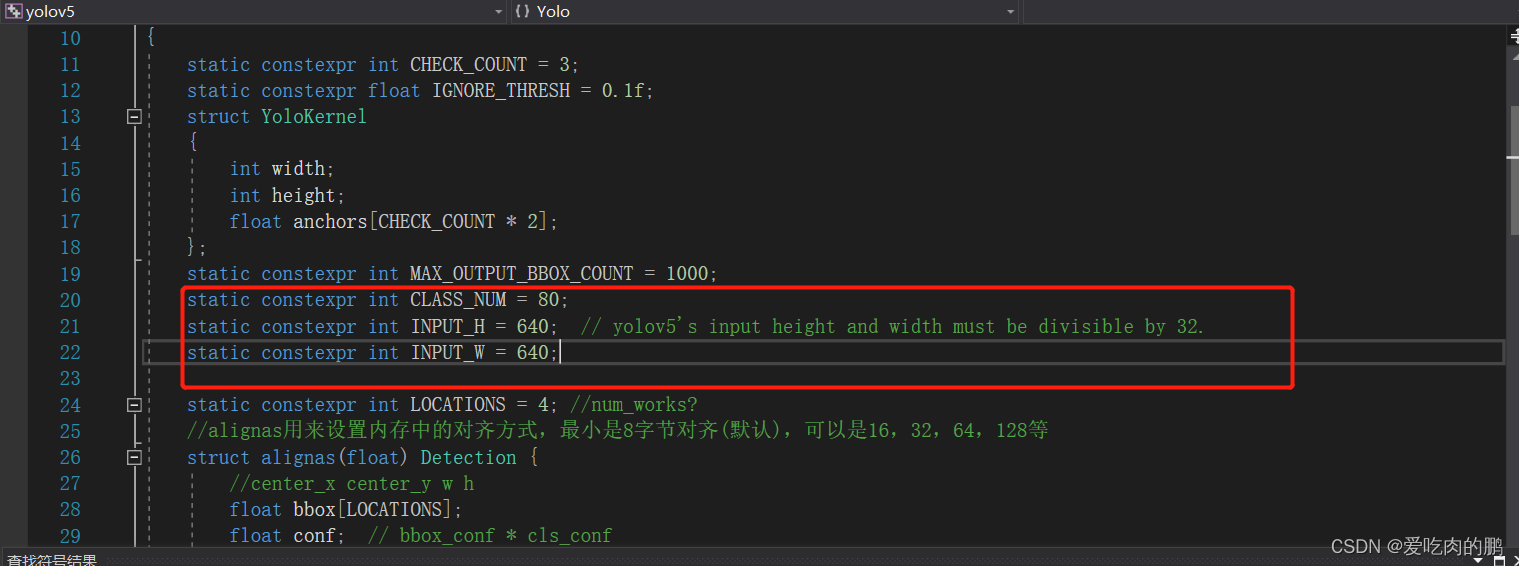
上VS界面上面的Debug改为Release

右键项目重新生成

编译成功以后,会在YOLOv5TensorRT\build\Release下生成一个yolov5.exe程序
程序运行
生成engine文件
将最前面生成的yolov5s.wts序列化模型复制到这个exe文件下。
输入:使用的是s模型,最后则输入s,若为m模型,最后一个参数则需要改成m
./yolov5.exe -s yolov5s.wts yolov5s.engine s
该过程是将yolov5s.wts转化成yolov5s.engine文件的过程,这个过程比较长【差不多10~20分钟】,耐心等待。成功以后如下显示
./yolov5.exe -s yolov5s.wts yolov5s.engine s
Loading weights: yolov5s.wts
Building engine, please wait for a while...
[05/27/2022-16:39:23] [W] [TRT] TensorRT was linked against cuBLAS/cuBLASLt 10.2.2 but loaded cuBLAS/cuBLASLt 10.2.1
[05/27/2022-16:39:24] [W] [TRT] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
[05/27/2022-16:48:34] [W] [TRT] TensorRT was linked against cuBLAS/cuBLASLt 10.2.2 but loaded cuBLAS/cuBLASLt 10.2.1
[05/27/2022-16:48:34] [W] [TRT] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
Build engine successfully!
同时在exe文件夹下生成了engine文件
预测
图像预测:
将E:\YOLOv5TensorRT\ 下的整个pictures文件复制到exe程序文件下,同时将coco_classes.txt文件也放进来

然后打开cmd运行如下命令进行预测:
./yolov5.exe -d yolov5s.engine -img ./pictures出现如下:
E:\Yolov5_Tensorrt_Win10\build\Release>yolov5 -d yolov5s.engine ./pictures
[05/27/2022-16:54:45] [W] [TRT] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
[05/27/2022-16:54:45] [W] [TRT] TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
7ms
7ms此时会在当前目录下生成预测结果图:


视频预测
./yolov5.exe -d yolov5s.engine -video 0
如果需要替换自己的类,记得在代码中把类yololayer.h的数量改一下,如果放自己的txt,在yolov5.cpp中的主函数里将classes_path换成自己的路径即可。
完成上述即完成了整个过程。
权重:
链接:https://pan.baidu.com/s/15CXUvJSyWhC7ud96JIQ-8A
提取码:yypn
 https://github.com/YINYIPENG-EN/YOLOv5TensorRT.git
https://github.com/YINYIPENG-EN/YOLOv5TensorRT.git















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











